
deepseek 的影响力持续发酵,中国ai军团实现了反向技术输出,引发全球复现 deepseek 的热潮。尽管 deepseek-r1 部分开源,但关键信息仍未公开。然而,技术报告已为复现提供了指导,许多团队利用小型模型取得了成功,其中 hugging face 的 open r1 项目最为引人注目。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
Open R1 项目旨在完全开放复现 DeepSeek-R1,并补充所有未公开的技术细节。几周内,他们已完成 GRPO 实现、训练与评估代码以及合成数据生成器。项目地址:https://www.php.cn/link/59a6cd2175a468225a105a7cd7f20ec4
近期,Open R1 发布了 OpenR1-Math-220k 数据集,填补了 DeepSeek R1 合成数据缺口。该数据集包含 22 万条高质量数据,源自 80 万条 DeepSeek R1 推理轨迹。
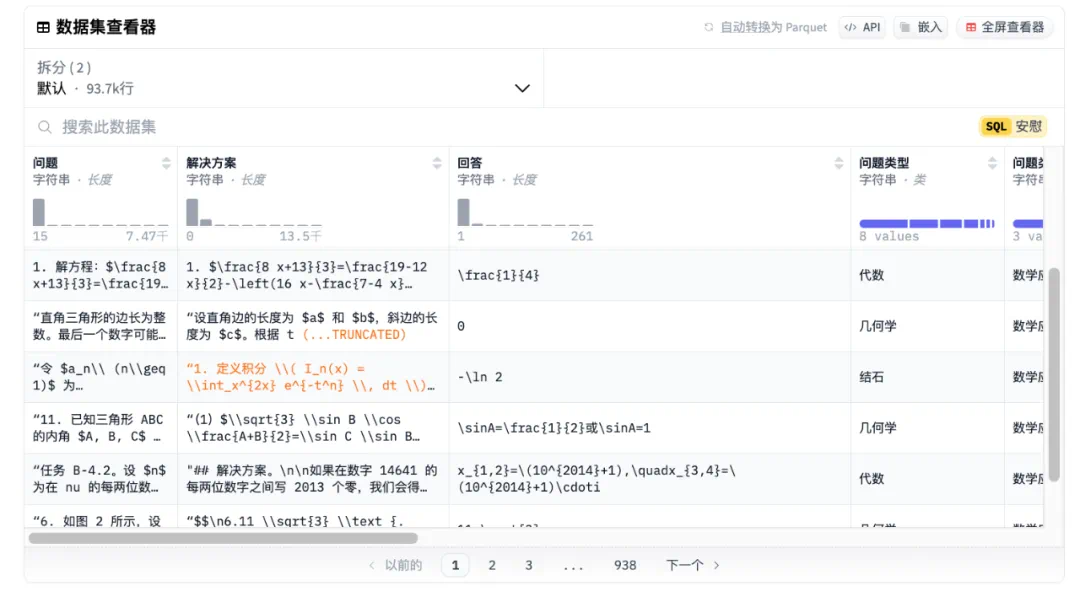 OpenR1-Math-220k 数据集概览 数据集链接:https://www.php.cn/link/058d732557d3b439eb2ffdd074bbf347
OpenR1-Math-220k 数据集概览 数据集链接:https://www.php.cn/link/058d732557d3b439eb2ffdd074bbf347
DeepSeek R1 的优势在于其将高级推理能力迁移到小型模型的能力。DeepSeek 团队使用了 60 万条推理数据,证明了这种迁移能力,即使不使用强化学习也能实现强大的推理性能。OpenR1-Math-220k 数据集弥补了 DeepSeek 未公开合成数据的不足。基于该数据集训练的 Qwen-7B-Math-Instruct 模型,性能与 DeepSeek-Distill-Qwen-7B 相当。
OpenR1-Math-220k 数据集特点:
数据集分为 default (94k 问题) 和 extended (131k 问题) 两个部分。
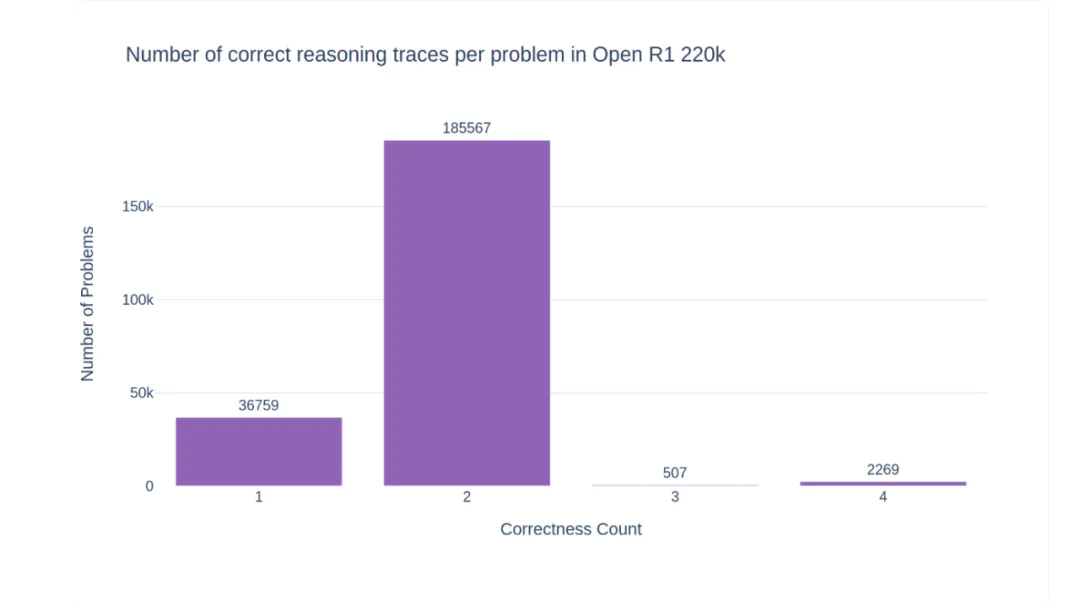
Open R1 团队希望这种可扩展、高质量的推理数据生成过程能够启发其他领域。数据生成过程使用了 vLLM 和 SGLang,并对 Math-Verify 工具进行了改进,利用 Llama-3.3-70B-Instruct 模型进行二次评估,确保数据质量。数据生成脚本:https://www.php.cn/link/59a6cd2175a468225a105a7cd7f20ec4/tree/main/slurm
在 OpenR1-Math-220k 数据集上训练的 Qwen-7B-Math-Instruct 模型,与 DeepSeek-Distill-Qwen-7B 的性能相当。
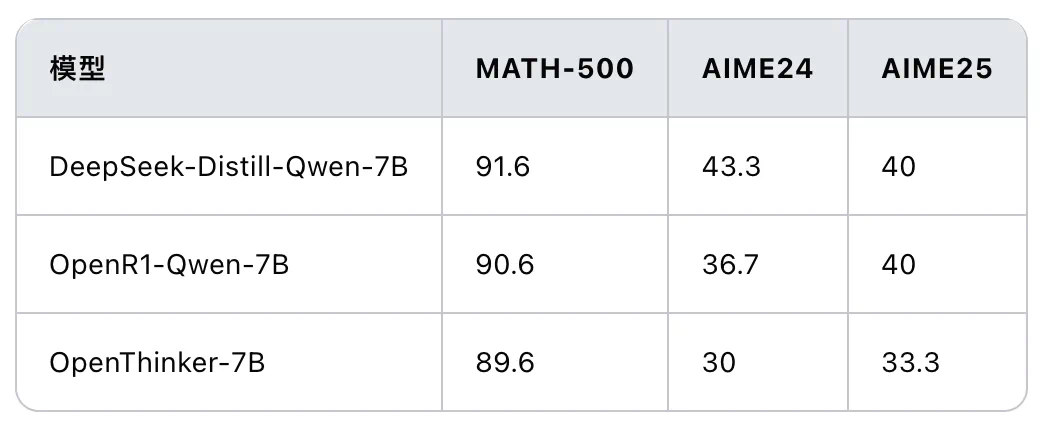
Open R1 项目的成果表明,少量高质量的推理数据也能实现强大的推理能力,并引发了关于 LLM 推理机制、数据规模和 CoT 长度等问题的深入探讨。 相关研究表明,更小、更高质量的数据集可能更有效。 Open R1 团队正在进行更多实验,以优化 GRPO 训练。


参考链接:https://www.php.cn/link/ddc751074ed4db1ce8e65aec173d16e3, https://www.php.cn/link/6e3a0a9abe898f51ff56c491b528b302, https://www.php.cn/link/a87c3e8f9b58723ac1c4f6ab69c0d0c9, https://www.php.cn/link/0af07e9885819ecb85897611e758433b, https://www.php.cn/link/b8742743f35ad13e837cb8fc849f759d
以上就是开源22万条DeepSeek R1的高质量数据!你也能复现DeepSeek了的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 358
358


















