
摩尔线程科研团队在 arxiv 上发表最新研究成果《round attention:以轮次块稀疏性开辟多轮对话优化新范式》,该方法显著提升了大型语言模型(llm)的多轮对话推理效率。 round attention 的端到端延迟低于现有主流的 flash attention 推理引擎,并大幅降低了 kv 缓存的 gpu 显存占用(节省 55% 到 82%)。
近年来,LLM 的广泛应用凸显了多轮对话场景下两大瓶颈:计算开销巨大和 GPU 内存需求高涨。摩尔线程的 Round Attention 正是针对这两个问题提出的解决方案。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
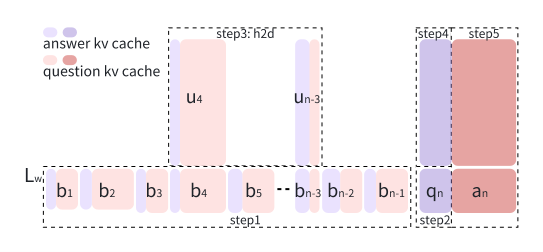
Round Attention 的核心创新:
Round Attention 以轮次为单位优化 Attention 机制,并基于对多轮对话 Attention 分布规律的深入研究,提出了独特的推理流程。其主要优势体现在:
性能提升:
Round Attention 在保持模型推理精度的前提下,实现了显著的性能提升:端到端延迟低于 Flash Attention,KV 缓存显存占用降低 55% 到 82%。
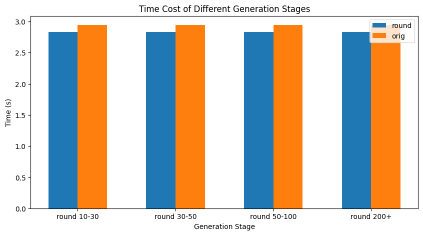
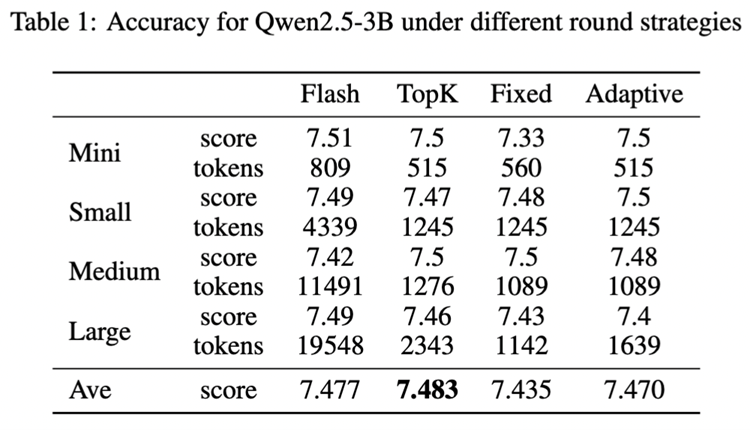
未来展望:
摩尔线程团队希望与开源社区合作,进一步探索稀疏注意力优化,共同解决 LLM 落地应用中的效率和成本难题。 论文全文已可在 arXiv 上获取:
https://www.php.cn/link/65b22292b232047ac742de249504db02
以上就是摩尔线程 Round Attention:以轮次块稀疏性开辟多轮对话优化新范式的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 924
924


















