
openpipe平台最新研究:开源模型通过强化学习在复杂推理任务中超越顶级闭源模型
OpenPipe平台近期发布的一项研究显示,通过运用GRPO强化学习算法,其团队成功地使开源模型Qwen在重度推理游戏《时空谜题》中的表现超越了DeepSeek R1、OpenAI的o1和o3-mini等业界领先模型。该研究由Ender Research的强化学习研究员Brad Hilton和OpenPipe创始人Kyle Corbitt共同完成。
研究结果表明,该方法不仅将模型与Claude Sonnet 3.7的性能差距缩小到个位数百分比,同时实现了超过100倍的推理成本优化。研究报告详细介绍了任务设计、超参数调整经验以及基于Torchtune框架构建的完整训练方案。
研究背景:大型语言模型的推理能力瓶颈
自OpenAI发布o系列推理模型以来,基于强化学习训练的LLM发展迅速。然而,逻辑演绎能力仍然是这些模型的短板,主要体现在以下三个方面:
即使是顶尖模型,也经常会出现人类容易识别的低级错误。
《时空谜题》基准测试:挑战现有模型的推理极限
为了评估模型的推理能力,研究团队使用了自定义的推理任务——《时空谜题》。该谜题类似于经典桌游Cluedo,但增加了时间和动机维度,并使用OR-Tools的CP-SAT求解器生成谜题。
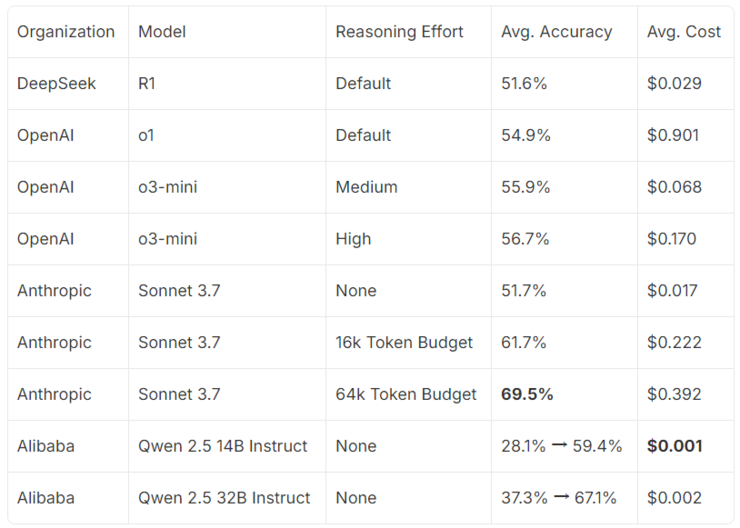
研究人员对DeepSeek R1、OpenAI的o1和o3-mini、Anthropic的Claude Sonnet 3.7以及Qwen 14B和32B模型进行了基准测试。结果显示,Claude Sonnet 3.7表现最佳,而未经调优的Qwen模型性能相对较弱。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
GRPO算法与高效训练方案:突破性能瓶颈的关键
研究团队采用GRPO强化学习算法对Qwen模型进行训练。与PPO等传统方法相比,GRPO算法在简化训练过程的同时,也取得了显著的性能提升。
训练过程主要包括以下步骤:
研究中还使用了vLLM推理引擎、HuggingFace Transformers AutoTokenizer以及Torchtune库,并对参数进行了精细的调优,以提高训练效率和模型性能。Torchtune库提供的功能包括激活检查点、激活卸载、量化和PEFT等。
研究结果:显著提升性能并降低成本
经过100多次迭代训练,Qwen模型的推理性能得到了显著提升,140亿参数的模型接近Claude Sonnet 3.7的水平,而320亿参数的模型则几乎达到了Sonnet的性能。
更重要的是,该方法大幅降低了推理成本,实现了超过100倍的优化。研究还发现,仅需16个训练样本就能实现高达10-15%的性能提升。
结论:强化学习在提升开源模型推理能力方面的巨大潜力
这项研究证明了强化学习在提升开源模型推理能力方面的巨大潜力。通过GRPO算法和高效的训练方案,即使是相对较小的开源模型也能在复杂的推理任务中达到甚至超越顶级闭源模型的性能,同时大幅降低成本。 这为开源社区提供了新的方向,也为未来LLM的发展提供了新的思路。
以上就是GRPO在《时空谜题》中击败o1、o3-mini和R1的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 191
191























