
使用 kubernetes 遇到最多的 70%问题都可以归于网络问题,最近发现如果内核参数: bridge-nf-call-iptables设置不当的话会影响 kubernetes 中 node 节点上的 pod 通过 clusterip 去访问同 node上的其它 pod 时会有超时现象,复盘记录一下排查的前因后因。
1
问题现象
集群环境为 K8s v1.15.9,cni 指定了 flannel-vxlan 跟 portmap, kube-proxy 使用 mode 为 ipvs
问题现象是,某个 Node 节点上的 pod 通过 service 访问其它服务时,有些能通,有些不通,不通的都提示 timeout
异常的请求:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ curl -v http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080* Rebuilt URL to: http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080/* Trying 10.233.53.172...* TCP_NODELAY set# 这里一直等待直到超时</code>
这个节点上的很多 pod 都存在这个问题, 其它节点未发现异常.
正常请求:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ curl -v http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080* Rebuilt URL to: http://panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080/* Trying 10.233.53.172...* TCP_NODELAY set* Connected to panorama-v2-frontend-service.spring-prod.svc.cluster.local (10.233.53.172) port 8080 (#0)> GET / HTTP/1.1> Host: panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080> User-Agent: curl/7.52.1> Accept: */*>< HTTP/1.1 200 OK</code>
2
排查过程
先对异常 Node 进行排查,因为其它节点是正常的,通过对异常 Node 的网络、kube-proxy、 iptables、ipvs 规则、kubelet 等排查后未发现有可疑的地方,就暂时排除嫌疑了。
第二个可疑的是 DNS, coreDNS 负责对 service 解析成 ClusterIP, 在出问题的 Node 上经过多次测试均能正确解析,coreDNS 排除嫌疑。
可疑的地方都筛了一遍,无果, 那就只能再从现象来发现看看有没有相同点。
首先,访问路径为:Service – > ClusterIP – > PodIP
对 service 访问异常,coreDNS 已经被排除了,那先绕过 service,直接使用 ClusterIP 访问呢? 测试后现象依旧。另外关注公号“终码一生”,回复关键词“资料”,获取视频教程和最新的面试资料!
那再绕过 ClusterIP,直接使用 PodIP 呢? Bingo,之前会出问题的访问都是正常的了。
那么问题就出在 CluterIP – > PodIP 上, 那么又有以下可能:
ClusterIP 没有正确转发到 PodIP 上可能导致超时如果正确转发,响应没有返回也可能导致超时第一种可能性很容易排查,之前已经确认了 ipvs 规则、iptables 规则都是没有问题的,且通过 ClusterIP 发起的请求可以到达 PodIP 上, 基本就排除了可能性一
另外,对比正常跟异常请求会发现,异常的请求原 Pod 跟目标 pod 都是在同一个 Node 上,而正常的请求则处于不同的 Node,会是这个影响吗?
上面的可能性二,只能祭出抓包神器了tcpdump, 通过抓包发现(抓包过程见文未)会发现请求中出现了Reset
那么问题转换一下: 为什么相同 Node 上 podA 通过 service/ClusterIP 访问 PodB 响应会不返回呢,而通过 PodIP 访问就没问题?
补充一句就是,相同 Node 上的 pod 相互访问是不需要经过 Flannel 的,因此 Flannel 可以排除嫌疑
so, 问题在哪?
回到 tcpdump 的抓包数据, 可以发现,响应的数据没有按照请求的路径返回,嗯,Interesting
3
罪魁祸首
不管是 iptables 还是 ipvs 模式,Kubernetes 中访问 service 都会进行 DNAT,将原本访问 ClusterIP:Port 的数据包 DNAT 成 service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并SNAT,这样原路返回形成一个完整的连接链路.
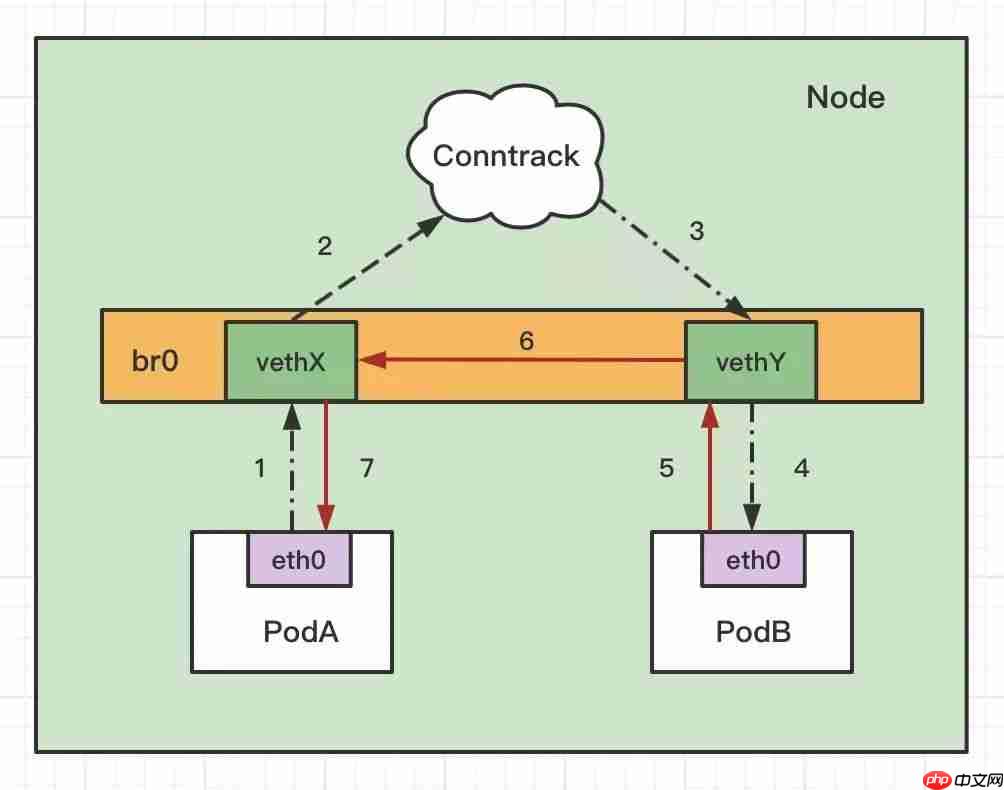
从 tcpdump 看到请求被 reset 了, 没错, bridge-nf-call-iptables(如果是 ipv6 的话则是net.bridge.bridge-nf-call-ip6tables)参数
但是不对,这个参数 linux 默认开启的呢?难道是有人修改了么?
使用命令查看该参数是否开启:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ cat /proc/sys/net/bridge/bridge-nf-call-iptables# 0</code>
返回 0,说明确实没有开启(后来被证实是被同事修改了),那这个参数是如何影响的返回路径的呢?
那就不得不说linux bridge了!
虽然 CNI 使用的是 flannel, 但 flannel 封装的也是 linux bridge,linux bridge 是虚拟的二层转发设备,而 iptables conntrack 是在三层上,所以如果直接访问同一网桥内的地址(ip 同一网段),就会直接走二层转发,不经过 conntrack:
结合上面的图来看,同 Node 通过 service 访问 pod 的访问路径如下:
PodA 访问 service, 经过 coreDNS 解析成 Cluster IP,不是网桥内的地址(ClusterIP 一般跟 PodIP 不在一个网段),走 Conntrack,进行 DNAT,将 ClusterIP 转换成 PodIP:PortDNAT 后发现是要转发到了同节点上的 PodB,PodB 回包时发现目的 IP(此时是 PodA 的 IP) 在同一网桥上(PodA 与 PodB 的 IP 段一致),就直接走二层转发了,不会去调 conntrack,这样就导致回包时没有原路返回没有返回包就导致请求方一直等直到超时退出.
这样也解释了为何访问在其它节点的应用的 ClusterIP 没有问题,因为目标 PodIP 与源 PodIP 不在同一个网段上,肯定要走 conntrack.
4
问题解决
总述,开启参数后问题解决
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ echo "net.bridge.bridge-nf-call-iptables=1" >> /etc/sysctl.conf$ echo "net.bridge.bridge-nf-call-ip6tables=1" >> /etc/sysctl.conf$ sysctl -p /etc/sysctl.conf</code>
5
linux conntrack
关于 conntrack 其实也是个值得好好研究一番的知识点, 各个发行版都有工具可以看到 conntrack 里的记录,格式如下:
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ conntrack -Ltcp 6 119 SYN_SENT src=10.224.1.34 dst=10.233.53.172 sport=56916 dport=8080 [UNREPLIED] src=10.224.1.56 dst=10.224.1.34 sport=8080 dport=56916 mark=0 use=1</code>
那个著名的DNS 5s timeout[1]的问题就跟 conntrack 机制有关,由于篇幅有限,就不在这里展开.
6
tcpdump
在容器中的抓包命令
代码语言:javascript代码运行次数:0运行复制<code class="javascript">$ tcpdump -vvv host 10.224.1.34 or 10.233.53.172 or 10.224.1.56</code>
其中的三个 ip 分别对应 podA IP, podB 的 ClusterIP, podB 的 PodIP
这里由于篇幅的关系,只保存有关键信息,同时使用注释是作者加入的,方便理解.
对于异常请求的 tcpdump,如下:
代码语言:javascript代码运行次数:0运行复制<code class="javascript"># podA 请求 PodBpanorama-frontend-deploy-c8f6fd4b6-52tvf.45954 > panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [S], cksum 0x4cc5 (incorrect -> 0xba1b), seq 1108986852, win 28200, options [mss 1410,sackOK,TS val 1345430037 ecr 0,nop,wscale 7], length 0# 10-224-1-56是PodB的podIP, 这里省略了解析过程,可以看到返回数据给PodA10-224-1-56.panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.45954: Flags [S.], cksum 0x1848 (incorrect -> 0x99ac), seq 3860576650, ack 1108986853, win 27960, options [mss 1410,sackOK,TS val 2444502128 ecr 1345430037,nop,wscale 7], length 0# 重点: podA直接reset了请求.panorama-frontend-deploy-c8f6fd4b6-52tvf.45954 > 10-224-1-56.panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [R], cksum 0xb6b5 (correct), seq 1108986853, win 0, length 0</code>
最后会发现 PodA 给 PodB 发送了个R Flags, 也就是reset, 就是因为当 PodB 返回握手确认给到 PodA,PodA 根本不认识这个请求,所以直接给 reset 掉了, 三手握手都没有建立,this is why!
而对于net.bridge.bridge-nf-call-iptables=1的正常请求的 tcpdump 如下:
代码语言:javascript代码运行次数:0运行复制<code class="javascript"># 能看到正常的三次握手, 这里省略# 开启传输数据panorama-frontend-deploy-c8f6fd4b6-52tvf.36434 > panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080: Flags [P.], cksum 0x4d3c (incorrect -> 0x6f84), seq 1:128, ack 1, win 221, options [nop,nop,TS val 1346139372 ecr 2445211463], length 127: HTTP, length: 127 GET / HTTP/1.1 Host: panorama-v2-frontend-service.spring-prod.svc.cluster.local:8080 User-Agent: curl/7.52.1 Accept: */*panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.36434: Flags [.], cksum 0x4cbd (incorrect -> 0xe8a6), seq 1, ack 128, win 219, options [nop,nop,TS val 2445211463 ecr 1346139372], length 0panorama-v2-frontend-service.spring-prod.svc.cluster.local.8080 > panorama-frontend-deploy-c8f6fd4b6-52tvf.36434: Flags [P.], cksum 0x4dac (incorrect -> 0x0421), seq 1:240, ack 128, win 219, options [nop,nop,TS val 2445211463 ecr 1346139372], length 239: HTTP, length: 239 HTTP/1.1 200 OK Server: nginx/1.17.1 Date: Wed, 18 Aug 2021 15:10:17 GMT Content-Type: text/html Content-Length: 1540 Last-Modified: Fri, 09 Jul 2021 06:36:53 GMT Connection: keep-alive ETag: "60e7ee85-604" Accept-Ranges: bytes</code>
相信这个请求路径还是很清晰的,就不再啰嗦.
7
结语
禁用net.bridge.bridge-nf-call-ip6tables这个参数当然也有好外,那就是考虑同网段的 IP 访问没必要走 conntrack,一定程度有助于性能。
kubernetes 的官方文档[2]中明确提及 Node 节点上需要开启这个参数,不然碰到各种诡异的现象也只是时间问题,所以还是不要随意调整。
以防后患的话可以对该参数是否开启进行监控,防止被人误修改。
以上就是K8s为啥要启用bridge-nf-call-iptables内核参数?用案例给你讲明白!的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 399
399



















