采用PaddlePaddle 3.0深度学习框架,基于预训练的ResNet50模型开发,通过监督学习训练出深度学习模型识别手语翻译成对应文字,为听力和言语障碍者提供一种将手语转换为书面语言的桥梁。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在听力和言语障碍个体日常生活中,手语扮演着至关重要的角色,它是一种复杂的语言形式,有自己的语法和语义规则。为促进残障人士与社会的无障碍交流,开发能准确识别和翻译手语的人工智能系统尤为关键,然而手语数据集收集和标注工作相对困难,且缺乏标准化的数据获取渠道,为相关技术研发带来挑战。
为克服这些挑战,本项目采用开源手语字母图像数据集,包含手语中使用的26类字母和3类基本手势图像,采用PaddlePaddle 3.0深度学习框架,基于预训练的ResNet50模型开发,通过监督学习训练出深度学习模型识别手语翻译成对应文字,为听力和言语障碍者提供一种将手语转换为书面语言的桥梁。
通过技术手段,帮助听障和语言障碍人士与社会更有效地沟通,为残障人士提供了更多的交流可能性,促进社会的多元化和包容性。
采用开源的ASL_Alphabet数据集,划分为训练数据集样本数量69600,验证集样本数量17400,均为200x200像素的图像。
有29个类,除了 26 个英文字母外,还包括 SPACE(空格)、 DELETE(删除)和 NOTHING(无动作)这三个类别,它们在实时应用和分类中非常有用。
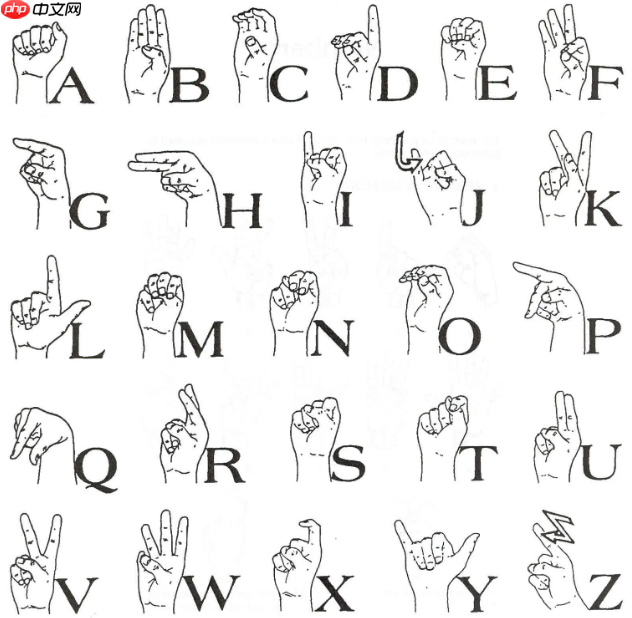
手语形式如下图所示
# 数据集解压到work文件夹内!tar -xvf /home/aistudio/data/data292697/shouyu.tar -C work/
#分别读取train.txt和val.txt文件内的内容# 初始化一个空列表来存储文件内容train_list = []
val_list = []# 打开文件并读取每一行with open('/home/aistudio/work/iamges/train.txt', 'r') as file: for line in file: # 分割每行的图像路径和标签
path, label = line.strip().split(' ') # 将路径和标签作为列表添加到train_list中
train_list.append([path, label])# 打开文件并读取每一行with open('/home/aistudio/work/iamges/val.txt', 'r') as file: for line in file: # 分割每行的图像路径和标签
path, label = line.strip().split(' ') # 将路径和标签作为列表添加到val_list中
val_list.append([path, label])# 打印列表内容print(train_list)# 打印列表内容print(val_list)# 对数据集处理,将路径添加到前缀,并统计每个数据集的类别数量prefix = 'work/iamges'train_list = [[f'{prefix}/{item[0]}',item[1]] for item in train_list]
val_list = [[f'{prefix}/{item[0]}',item[1]] for item in val_list]# 打印新的列表以验证print(train_list[10])print(val_list[10])print(type(train_list[10]))print(type(val_list[10]))print("训练集样本数量是:{}".format(len(train_list)))print("验证集样本数量是:{}".format(len(val_list)))['work/iamges/train/A/A1008.jpg', '0'] ['work/iamges/val/A/A1063.jpg', '0'] <class 'list'> <class 'list'> 训练集样本数量是:69600 验证集样本数量是:17400
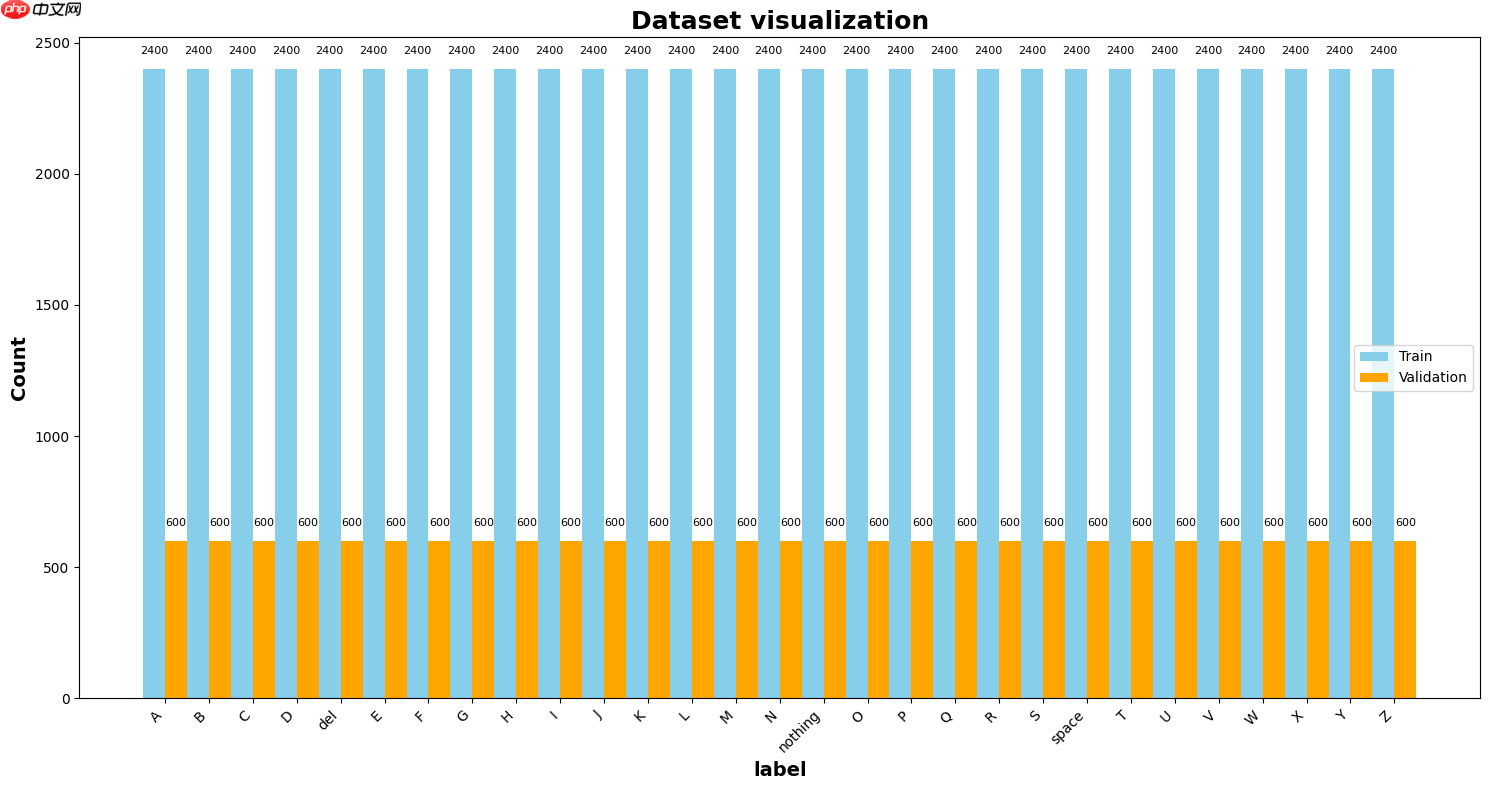
此部分主要目的是对训练集和验证集中的类别分布进行可视化;
通过遍历数据列表来统计每个类别的出现次数,并将类别编号转换为更具可读性的标签;
然后使用Matplotlib库创建一个条形图,其中包含两组条形,分别代表训练集和验证集中每个类别的数量;
对数据集的可视化有助于快速识别数据集中的类别不平衡问题,为后续的数据分析和模型训练提供有用的信;
import matplotlib.pyplot as plt# 假设这是从文件中读取的数据列表train_data = train_list
val_data = val_list# 初始化字典来存储每个数据集的类别数量train_category_counts = {str(i): 0 for i in range(29)} # 假设有0-28共29个类别val_category_counts = {str(i): 0 for i in range(29)}# 统计训练集每个类别的数量for item in train_data:
category = item[1]
train_category_counts[category] += 1# 统计验证集每个类别的数量for item in val_data:
category = item[1]
val_category_counts[category] += 1# 类别编号到标签的映射category_mapping = { '0': 'A', '1': 'B', '2': 'C', '3': 'D', '4': 'del', '5': 'E', '6': 'F', '7': 'G', '8': 'H', '9': 'I', '10': 'J', '11': 'K', '12': 'L', '13': 'M', '14': 'N', '15': 'nothing', '16': 'O', '17': 'P', '18': 'Q', '19': 'R', '20': 'S', '21': 'space', '22': 'T', '23': 'U', '24': 'V', '25': 'W', '26': 'X', '27': 'Y', '28': 'Z'}# 使用映射更新类别计数字典的键train_category_counts = {category_mapping[key]: value for key, value in train_category_counts.items()}
val_category_counts = {category_mapping[key]: value for key, value in val_category_counts.items()}# 创建条形图plt.figure(figsize=(15, 8))
bar_width = 0.5index = list(range(len(train_category_counts))) # 使用数值索引# 绘制训练集的条形图train_bars = plt.bar([i - bar_width/2 for i in index], list(train_category_counts.values()), bar_width, label='Train', color='skyblue')# 绘制验证集的条形图val_bars = plt.bar([i + bar_width/2 for i in index], list(val_category_counts.values()), bar_width, label='Validation', color='orange')# 添加类别标签category_labels = list(train_category_counts.keys())
plt.xticks([i for i in index], category_labels, rotation=45, ha='right')# 添加图表标题和轴标签plt.xlabel('label', fontsize=14, fontweight='bold') # 设置 x 轴标签并加粗加大plt.ylabel('Count', fontsize=14, fontweight='bold') # 设置 y 轴标签并加粗加大plt.title('Dataset visualization', fontsize=18, fontweight='bold')
plt.legend()# 在每个条形上添加数量标签for i in index: # 训练集数量标签
plt.text(i - bar_width/2, list(train_category_counts.values())[i] + 50, str(list(train_category_counts.values())[i]), ha='center', va='bottom', fontsize=8) # 验证集数量标签
plt.text(i + bar_width/2, list(val_category_counts.values())[i] + 50, str(list(val_category_counts.values())[i]), ha='center', va='bottom', fontsize=8)
plt.tight_layout()
plt.show()1、数据预处理 :定义了一个名为 preprocess 的函数,用于对图像进行以下预处理步骤
2、自定义数据读取 :定义了一个名为 Reader 的类,继承自 PaddlePaddle 的 Dataset 类,用于封装数据读取和预处理逻辑
3、生成数据集实例 :使用 Reader 类创建了两个数据集实例
import paddlefrom paddle.vision.transforms import Compose, Resize, Normalizefrom PIL import Imageimport numpy as npfrom paddle.io import Dataset# 自定义的数据预处理函数,输入原始图像,输出处理后的图像def preprocess(img):
transform = Compose([
Resize(size=(224, 224)), # 调整图像大小为224x224
Normalize(mean=[127.5, 127.5, 127.5], std=[127.5, 127.5, 127.5], data_format='HWC'), # 标准化
])
img = transform(img)
img = np.array(img).transpose((2, 0, 1)).astype('float32') # 转换数据格式从HWC到CHW
img = paddle.to_tensor(img) # 将numpy数组转换为paddle张量
return img# 自定义数据读取器class Reader(Dataset):
def __init__(self, data):
super().__init__()
self.samples = data # 使用全部数据
def __getitem__(self, idx):
# 处理图像
img_path = self.samples[idx][0] # 获取图像路径
img = Image.open(img_path) if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) # 数据预处理
# 处理标签
label = self.samples[idx][1] # 获取标签
label = np.array([label], dtype='int64') # 转换标签数据类型为int64
return img, label def __len__(self):
# 返回数据集中图片的数量
return len(self.samples)# 生成训练数据集实例train_dataset = Reader(train_list)# 生成验证数据集实例eval_dataset = Reader(val_list)# # 打印数据集大小# print(len(train_dataset))# print(len(eval_dataset))# # 打印一个训练样本的形状和标签# print(train_dataset[0][0].shape)# print(train_dataset[0][1])# print(type(train_dataset[0][1]))本段代码通过定义一个名为 visualize_data 的函数,实现从给定数据集中随机选取指定数量的图像并展示其对应标签的功能。
该函数首先随机生成不重复的索引,然后遍历这些索引,对每个选中的图像进行预处理,包括格式转换和数据范围的调整,以确保图像能被正确显示。
最后在一个4x4的网格布局中,使用 matplotlib 库展示这些图像和它们的标签名称。
此可视化工具有助于开发者和研究人员快速理解数据集的内容和结构,检查数据的预处理流程是否符合预期,以及标签是否正确映射。

import matplotlib.pyplot as pltimport numpy as npfrom paddle.io import Dataset# 定义一个函数来显示图像和标签def visualize_data(dataset, num_images=16):
plt.figure(figsize=(15, 15)) # 设置整个图像的大小
indices = np.random.choice(len(dataset), num_images, replace=False) # 随机选择索引
for i, idx in enumerate(indices): # 获取一个样本
image, label = dataset[idx] # 获取标签名称
label_name = category_mapping[str(label[0])] # 确保标签是字符串格式
# 将图像数据重新缩放回 [0, 1] 范围
image = (image.numpy().transpose((1, 2, 0)) + 1) / 2
# 绘制图像
plt.subplot(4, 4, i+1) # 创建4x4网格中的子图
plt.imshow(image)
plt.title(f'Label: {label_name}')
plt.axis('off')
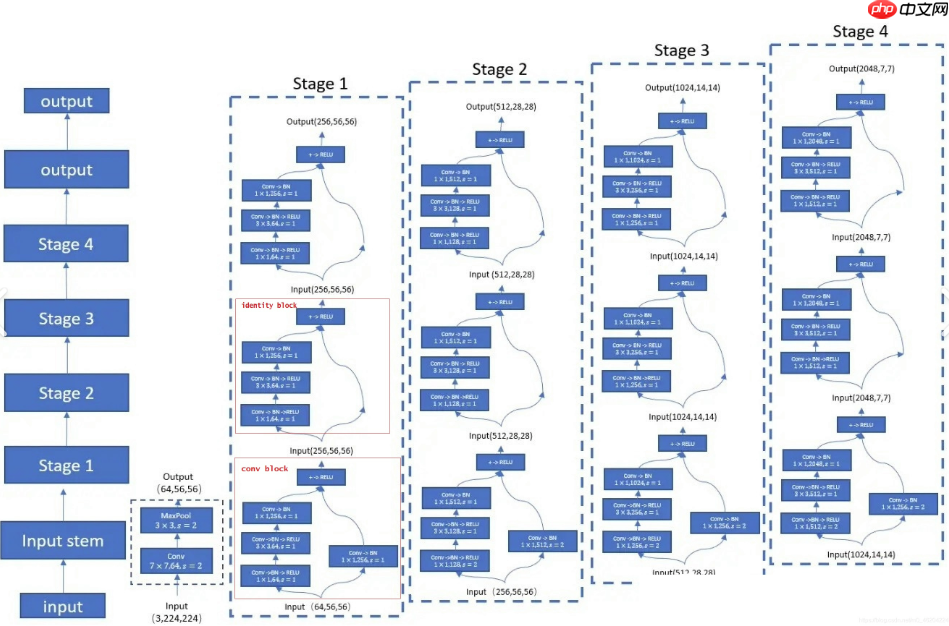
plt.show()# 确保 category_mapping 已经定义category_mapping = { '0': 'A', '1': 'B', '2': 'C', '3': 'D', '4': 'del', '5': 'E', '6': 'F', '7': 'G', '8': 'H', '9': 'I', '10': 'J', '11': 'K', '12': 'L', '13': 'M', '14': 'N', '15': 'nothing', '16': 'O', '17': 'P', '18': 'Q', '19': 'R', '20': 'S', '21': 'space', '22': 'T', '23': 'U', '24': 'V', '25': 'W', '26': 'X', '27': 'Y', '28': 'Z'}# 显示训练集中随机抽取的16张图像visualize_data(train_dataset)本部分定义了一个名为 MyNet 的神经网络模型,继承自 PaddlePaddle 的 paddle.nn.Layer 基类,使用迁移学习和预训练的 ResNet50 网络作为特征提取部分。
迁移学习是一种高效的学习技术,通过将一个在大型数据集(如ImageNet)上预训练的模型调整应用于不同的但相关的任务,从而提高模型在目标数据集上的性能,减少训练时间和计算资源的需求,尤其适用于数据量较小或标注成本较高的情况;
ResNet50 是残差网络(ResNet)的一个变体,它包含50层,通过使用跳跃连接(或“残差连接”)解决了深度神经网络训练中的退化问题,这使得网络能够更深入地学习特征而不会发生梯度消失或爆炸;
通过迁移学习,利用ResNet50在大规模数据集上学到的知识,来提高对手语字母图像的识别精度,不仅能够提升模型的性能,还能加速开发过程,为后续的手语识别和翻译任务奠定坚实的基础。
#定义模型class MyNet(paddle.nn.Layer):
def __init__(self):
super(MyNet,self).__init__()
self.layer=paddle.vision.models.resnet50(pretrained=True)
self.fc = paddle.nn.Linear(1000, 29) #网络的前向计算过程
def forward(self,x):
x=self.layer(x)
x=self.fc(x) return x本段代码通过定义输入规格、实例化自定义的 MyNet 模型,并使用 paddle.Model 进行封装,为接下来的模型训练和评估准备了环境。
其中input_define 和 label_define 指定模型输入数据形状和类型,确保数据与模型期望的格式一致,而 paddle.Model 封装使得模型训练过程更加简洁高效。
之后配置并启动模型训练过程。创建了一个使用 Adam 算法的优化器,并设置学习率,指定使用 GPU 进行训练的设备。
通过 model.prepare 方法设置了优化器、损失函数(交叉熵损失)和评估指标(准确率)。
调用 model.fit 方法开始训练,指定了训练数据集、验证数据集、批次大小、训练轮次、模型保存路径和频率以及日志打印频率。
# 定义输入input_define = paddle.static.InputSpec(shape=[-1,3,224,224], dtype="float32", name="img") label_define = paddle.static.InputSpec(shape=[-1,1], dtype="int64",name="label")# 实例化网络对象并定义优化器等训练逻辑model = MyNet() model = paddle.Model(model,inputs=input_define,labels=label_define) # 用Paddle.Model()对模型进行封装
optimizer = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())# 上述优化器中的学习率(learning_rate)参数很重要。要是训练过程中得到的准确率呈震荡状态,忽大忽小,可以试试进一步把学习率调低。place = paddle.CUDAPlace(0) # 使用第一个GPU设备model.prepare(optimizer=optimizer, # 指定优化器
loss=paddle.nn.CrossEntropyLoss(), # 指定损失函数
metrics=paddle.metric.Accuracy()) # 指定评估方法model.fit(train_data=train_dataset, # 训练数据集
eval_data=eval_dataset, # 测试数据集
batch_size=128, # 一个批次的样本数量
epochs=5, # 迭代轮次
save_dir="model/", # 把模型参数、优化器参数保存至自定义的文件夹
save_freq=1, # 设定每隔多少个epoch保存模型参数及优化器参数
log_freq=500, # 打印日志的频率)The loss value printed in the log is the current step, and the metric is the average value of previous steps. Epoch 1/5 step 500/544 - loss: 0.2382 - acc: 0.7220 - 690ms/step step 544/544 - loss: 0.0961 - acc: 0.7410 - 690ms/step save checkpoint at /home/aistudio/model/0 Eval begin... step 136/136 - loss: 0.0028 - acc: 0.9412 - 455ms/step Eval samples: 17400 Epoch 2/5
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(
step 500/544 - loss: 0.0257 - acc: 0.9742 - 683ms/step step 544/544 - loss: 0.0396 - acc: 0.9744 - 683ms/step save checkpoint at /home/aistudio/model/1 Eval begin... step 136/136 - loss: 0.0380 - acc: 0.9437 - 456ms/step Eval samples: 17400 Epoch 3/5
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(
step 500/544 - loss: 0.1033 - acc: 0.9043 - 690ms/step step 544/544 - loss: 0.1167 - acc: 0.9101 - 690ms/step save checkpoint at /home/aistudio/model/2 Eval begin... step 136/136 - loss: 0.0066 - acc: 0.9640 - 470ms/step Eval samples: 17400 Epoch 4/5
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(
step 500/544 - loss: 0.0835 - acc: 0.9816 - 696ms/step step 544/544 - loss: 0.0354 - acc: 0.9822 - 696ms/step save checkpoint at /home/aistudio/model/3 Eval begin... step 136/136 - loss: 9.4019e-05 - acc: 0.9939 - 470ms/step Eval samples: 17400 Epoch 5/5
/opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages/paddle/nn/layer/norm.py:788: UserWarning: When training, we now always track global mean and variance. warnings.warn(
step 500/544 - loss: 0.0011 - acc: 0.9873 - 693ms/step step 544/544 - loss: 0.0018 - acc: 0.9877 - 693ms/step save checkpoint at /home/aistudio/model/4 Eval begin... step 136/136 - loss: 0.0440 - acc: 0.9778 - 458ms/step Eval samples: 17400 save checkpoint at /home/aistudio/model/final
最终验证集测试结果为 step 136/136 - loss: 0.0440 - acc: 0.9778 - 458ms/step Eval samples: 17400 准确率高达97.8%
定义了一个用于图像推理的数据集类 InferDataset,能够加载单张图片并进行预处理;
实例化一个使用PaddlePaddle框架的推理模型 MyNet,并加载了训练好的模型参数;
使用这个模型对指定路径的图片进行预测,并将预测结果转换为类别标签,最后打印出预测的类别;
class InferDataset(Dataset):
def __init__(self, img_path=None):
"""
数据读取Reader(推理)
:param img_path: 推理单张图片
"""
super().__init__() if img_path:
self.img_paths = [img_path] else: raise Exception("请指定需要预测对应图片路径") def __getitem__(self, index):
# 获取图像路径
img_path = self.img_paths[index] # 使用Pillow来读取图像数据并转成Numpy格式
img = Image.open(img_path) if img.mode != 'RGB':
img = img.convert('RGB')
img = preprocess(img) #数据预处理--这里仅包括简单数据预处理,没有用到数据增强
return img def __len__(self):
return len(self.img_paths)#实例化推理模型model = paddle.Model(MyNet(),inputs=input_define)#读取刚刚训练好的参数model.load('model/final')#准备模型model.prepare()#利用训练好的模型进行预测infer_path='/home/aistudio/work/iamges/train/E/E1000.jpg'# print(infer_path)infer_data = InferDataset(infer_path)
result = model.predict(test_data=infer_data)[0]
# 关键代码,实现预测功能result = paddle.to_tensor(result)
result = np.argmax(result.numpy())
# 获得最大值所在的序号category_mapping = { '0': 'A', '1': 'B', '2': 'C', '3': 'D', '4': 'del', '5': 'E', '6': 'F', '7': 'G', '8': 'H', '9': 'I', '10': 'J', '11': 'K', '12': 'L', '13': 'M', '14': 'N', '15': 'nothing', '16': 'O', '17': 'P', '18': 'Q', '19': 'R', '20': 'S', '21': 'space', '22': 'T', '23': 'U', '24': 'V', '25': 'W', '26': 'X', '27': 'Y', '28': 'Z'}print(category_mapping[str(result)])Predict begin... step 1/1 [==============================] - 27ms/step Predict samples: 1 E
以上就是【掌上心语】PaddlePaddle 3.0实现29类智能手语识别助力残障人士的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 641
641






















