该本科毕设研究代码注释自动生成,基于Seq2Seq模型,以Java代码为输入,用北大胡星等人的数据集,构建含编码器、Bahdanau注意力机制、解码器的模型,经训练测试,10个epoch结果不理想,需继续优化。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

这个项目是我本科毕设(代码注释自动生成技术研究)的一部分,使用的是Seq2Seq模型,把代码注释自动生成任务当成机器翻译问题的一种变形。
我们使用的数据集是北京大学的胡星等人提供,他们的项目地址:EMSE-DeepCom。他们的论文:
感觉他们主要研究的AST对结果的影响,英文对于代码是具有严格的书写结构的,因此他们认为AST作为输入是有效的。本项目主要是只使用代码本身作为输入,看看与他们的实验结果有什么差别。
数据展示:
code(代码是java代码,每段代码是一个完整的方法):
public synchronized void info ( string msg ) { log record record = new log record ( level . info , msg ) ; log ( record ) ; }comment(由胡星等人从javadoc提取,每个注释是对对应方法功能的描述):
logs a info message
另:
Ahmad等人基于trnasfrormer模型搭建了一个模型,取得了不错的结果,详情可见论文:
我们也基于transformer框架搭建,研究原始的transformer框架与Ahmad等人改进的框架的区别,项目直达:基于Trasformer的代码注释自动生成技术研究
我的github项目直达:Code-Summarization
import paddlefrom paddle.nn import Transformerfrom paddle.io import Datasetimport osfrom tqdm import tqdmimport timeimport numpy as npimport matplotlib.pyplot as pltfrom nltk.translate.bleu_score import sentence_bleu
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nltk/decorators.py:68: DeprecationWarning: `formatargspec` is deprecated since Python 3.5. Use `signature` and the `Signature` object directly regargs, varargs, varkwargs, defaults, formatvalue=lambda value: "" /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/nltk/lm/counter.py:15: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sequence, defaultdict
code_path='/home/aistudio/data/data73043/camel_code.txt'comment_path='/home/aistudio/data/data73043/comment.txt'
def creat_dataset(a,b):
# a : code
# b: comment
with open(a,encoding='utf-8') as tc:
lines1=tc.readlines() for i in range(len(lines1)):
lines1[i]="<start> "+lines1[i].strip('\n')+" <end>"
with open(b,encoding='utf-8') as ts:
lines2=ts.readlines() for i in range(len(lines2)):
lines2[i]="<start> "+lines2[i].strip('\n')+" <end>"
if(len(lines1)!=len(lines2) ): print("数据量不匹配") return lines1,lines2code,comment=creat_dataset(code_path,comment_path)print(code[0])print(comment[0])
<start> public synchronized void info ( string msg ) { log record record = new log record ( level . info , msg ) ; log ( record ) ; } <end>
<start> logs a info message <end>其中词典的构造可以根据词汇出现的频率进行筛选,由变量word_fre控制
def build_cropus(data):
crpous=[] for i in range(len(data)):
cr=data[i].strip().lower()
cr=cr.split()
crpous.extend(cr) return crpous# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数iddef build_dict(corpus,frequency):
# 首先统计每个不同词的频率(出现的次数),使用一个词典记录
word_freq_dict = dict() for word in corpus: if word not in word_freq_dict:
word_freq_dict[word] = 0
word_freq_dict[word] += 1
# 将这个词典中的词,按照出现次数排序,出现次数越高,排序越靠前
# 一般来说,出现频率高的高频词往往是:I,the,you这种代词,而出现频率低的词,往往是一些名词,如:nlp
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
# 构造3个不同的词典,分别存储,
# 每个词到id的映射关系:word2id_dict
# 每个id到词的映射关系:id2word_dict
word2id_dict = {'<pad>':0,'<unk>':1}
id2word_dict = {0:'<pad>',1:'<unk>'} # 按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
for word, freq in word_freq_dict: if freq>frequency:
curr_id = len(word2id_dict)
word2id_dict[word] = curr_id
id2word_dict[curr_id] = word else:
word2id_dict[word]=1
return word2id_dict, id2word_dictword_fre=1code_word2id_dict,code_id2word_dict=build_dict(build_cropus(code),word_fre) comment_word2id_dict,comment_id2word_dict=build_dict(build_cropus(comment),word_fre)
code_maxlen=200 # 论文建议长度comment_maxlen=30 # 论文建议长度code_vocab_size=len(code_id2word_dict) comment_vocab_size=len(comment_id2word_dict)print(code_vocab_size)print(comment_vocab_size)
38869 32213
def build_tensor(data,dicta,maxlen):
tensor=[] for i in range(len(data)):
subtensor=[]
lista=data[i].split() for j in range(len(lista)):
index=dicta.get(lista[j])
subtensor.append(index)
if len(subtensor) < maxlen:
subtensor+=[0]*(maxlen-len(subtensor)) else:
subtensor=subtensor[:maxlen]
tensor.append(subtensor) return tensorcode_tensor=build_tensor(code,code_word2id_dict,code_maxlen) comment_tensor=build_tensor(comment,comment_word2id_dict,comment_maxlen) code_tensor=np.array(code_tensor) comment_tensor=np.array(comment_tensor)
test_code_tensor=code_tensor[:20000] val_code_tensor=code_tensor[20000:40000] train_code_tensor=code_tensor[40000:] test_comment_tensor=comment_tensor[:20000] val_comment_tensor=comment_tensor[20000:40000] train_comment_tensor=comment_tensor[40000:]print(test_code_tensor.shape[0])print(val_code_tensor.shape)print(train_code_tensor.shape)
20000 (20000, 200) (445812, 200)
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, code,comment):
"""
步骤二:实现构造函数,定义数据集大小
"""
super(MyDataset, self).__init__()
self.code = code
self.comment=comment def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
return self.code[index], self.comment[index] def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return self.code.shape[0]train_dataset = MyDataset(train_code_tensor,train_comment_tensor) val_dataset=MyDataset(val_code_tensor,val_comment_tensor) test_dataset=MyDataset(test_code_tensor,test_comment_tensor)
# 测试定义的数据集BATCH_SIZE=128train_loader = paddle.io.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True,drop_last=True) val_loader=paddle.io.DataLoader(val_dataset,batch_size=BATCH_SIZE,shuffle=True,drop_last=True) test_loader=paddle.io.DataLoader(test_dataset,batch_size=BATCH_SIZE,shuffle=True,drop_last=True)
example_x, example_y = next(iter(val_loader))print(example_x.shape)print(example_y.shape)print(example_y[:,:1].shape)
[128, 200] [128, 30] [128, 1]
网络模型使用的是带注意力机制的Seq2Seq网络架构,注意力机制使用的是Bahdanau提出的注意力机制计算方法。
模型的框架如下:
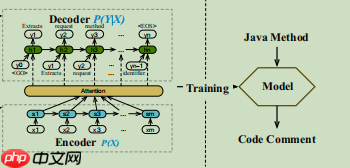
class Encoder(paddle.nn.Layer):
def __init__(self, vocab_size, embed_dim, hidn_size,rate=0.2):
super(Encoder, self).__init__()
self.embedder = paddle.nn.Embedding(vocab_size, embed_dim)
self.gru = paddle.nn.GRU(input_size=embed_dim,hidden_size=hidden_size,dropout=rate) def forward(self, sequence):
inputs = self.embedder(sequence)
encoder_output, encoder_state = self.gru(inputs)
# encoder_output [128, 18, 256] [batch_size, time_steps, hidden_size]
# encoder_state [num_layer*drection,batch_size,hidden_size] num_layer*drection=1*1=1
return encoder_output, encoder_stateencoder=Encoder(vocab_size=30000,embed_dim=256,hidden_size=64) paddle.summary(encoder,(128,200),dtypes='int64')
class BahdanauAttention(paddle.nn.Layer):
def __init__(self, hidden_size):
super(BahdanauAttention, self).__init__()
self.W1 = paddle.nn.Linear(hidden_size,hidden_size)
self.W2 = paddle.nn.Linear(hidden_size,hidden_size)
self.V = paddle.nn.Linear(hidden_size,1) def forward(self, hidden , encoder_out):
# hidden 隐藏层的形状 == (1,批大小,隐藏层大小)
hidden = paddle.transpose(hidden, perm=[1, 0, 2]) #[batch_size,1,hidden_size]
# encoder_out [batch_size,seq_len, hidden_size]
# 分数的形状 == (批大小,最大长度,1)
# 我们在最后一个轴上得到 1, 因为我们把分数应用于 self.V
# 在应用 self.V 之前,张量的形状是(批大小,最大长度,单位)
score = self.V(paddle.nn.functional.tanh(self.W1(encoder_out) + self.W2(hidden)))
# 注意力权重 (attention_weights) 的形状 == (批大小,最大长度,1)
attention_weights = paddle.nn.functional.softmax(score, axis=1) # 上下文向量 (context_vector) 求和之后的形状 == (批大小,隐藏层大小)
context_vector = attention_weights * encoder_out
context_vector = paddle.sum(context_vector, axis=1) return context_vectorclass Decoder(paddle.nn.Layer):
def __init__(self, vocab_size, embedding_dim, hidden_size,rate=0.2):
super(Decoder, self).__init__()
self.embedding = paddle.nn.Embedding(vocab_size, embedding_dim)
self.gru = paddle.nn.GRU(input_size=embedding_dim+hidden_size,hidden_size=hidden_size,dropout=rate)
self.fc = paddle.nn.Linear(hidden_size,vocab_size) # 用于注意力
self.attention = BahdanauAttention(hidden_size) def forward(self, x, hidden, enc_output):
# 编码器输出 (enc_output) 的形状 == (批大小,最大长度,隐藏层大小)
context_vector= self.attention(hidden, enc_output) #[batch_size,hideen_size]
# x 在通过嵌入层后的形状 == (批大小,1,嵌入维度)
x = self.embedding(x) # x 在拼接 (concatenation) 后的形状 == (批大小,1,嵌入维度 + 隐藏层大小)
x = paddle.concat([paddle.unsqueeze(context_vector, 1), x], axis=-1) # 将合并后的向量传送到 GRU
output, state = self.gru(x) # 输出的形状 == (批大小 * 1,隐藏层大小)
output = paddle.reshape(output, (-1, output.shape[2])) # 输出的形状 == (批大小,vocab)
x = self.fc(output) return x, state一组好的超参数可以取得好的结果,但是寻找这么一组好的参数往往是需要不断试验。
EPOCHS = 18embedding_size=256 # hidden_size=256 # max_grad_norm=5.0learning_rate=0.001train_batch_num=train_code_tensor.shape[0]//BATCH_SIZE #3482val_batch_num=val_code_tensor.shape[0]//BATCH_SIZE #156droprate=0.1
encoder=Encoder(code_vocab_size,embedding_size,hidden_size,droprate) decoder=Decoder(comment_vocab_size,embedding_size,hidden_size,droprate)
# 优化器clip = paddle.nn.ClipGradByGlobalNorm(clip_norm=max_grad_norm)
optim = paddle.optimizer.Adam(parameters=encoder.parameters()+decoder.parameters(),grad_clip=clip)# 自定义loss函数,消除padding的0的影响def getloss(predict, label):
cost = paddle.nn.functional.cross_entropy(predict,label,reduction='none')
zeo=paddle.zeros(label.shape,label.dtype)
mask=paddle.cast(paddle.logical_not(paddle.equal(label,zeo)),dtype=predict.dtype)
cost *= mask
return paddle.mean(cost)# 训练def train_step(inp, targ):
loss = 0
enc_output, enc_hidden = encoder(inp)
dec_hidden = enc_hidden
dec_input = paddle.unsqueeze(paddle.to_tensor([comment_word2id_dict.get('<start>')] * BATCH_SIZE), 1) # 教师强制 - 将目标词作为下一个输入
for t in range(1, targ.shape[1]): # 将编码器输出 (enc_output) 传送至解码器
predictions, dec_hidden= decoder(dec_input, dec_hidden, enc_output)
loss += getloss(predictions,targ[:, t]) # 使用教师强制
dec_input =paddle.unsqueeze(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1]))
batch_loss.backward()
optim.step()
optim.clear_grad() return batch_loss# 验证def val_step(inp, targ):
loss = 0
enc_output, enc_hidden = encoder(inp)
dec_hidden = enc_hidden
dec_input = paddle.unsqueeze(paddle.to_tensor([comment_word2id_dict.get('<start>')] * BATCH_SIZE), 1) # 教师强制 - 将目标词作为下一个输入
for t in range(1, targ.shape[1]): # 将编码器输出 (enc_output) 传送至解码器
predictions, dec_hidden= decoder(dec_input, dec_hidden, enc_output)
loss += getloss(predictions,targ[:, t]) # 使用教师强制
dec_input =paddle.unsqueeze(targ[:, t], 1)
batch_loss = (loss / int(targ.shape[1])) # 下面这行不能注释掉,否则GPU的显存会爆掉,有大佬知道为什么吗?
batch_loss.backward()
optim.clear_grad() return batch_losstrain_loss_list=[]
val_loss_list=[]def train():
for epoch in range(EPOCHS):
start = time.time()
train_total_loss = 0
encoder.train()
decoder.train() for (batch, (inp, targ)) in enumerate(train_loader):
batch_loss = train_step(inp, targ)
train_total_loss += batch_loss if batch % 400 == 0: print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,batch,batch_loss.numpy()[0]))
train_loss_list.append(train_total_loss.numpy()[0]/ train_batch_num)
print('train Epoch {} avaLoss {:.4f}'.format(epoch + 1,train_total_loss.numpy()[0] / train_batch_num))
encoder.eval()
decoder.eval()
val_total_loss=0
for (batch, (inp, targ)) in enumerate(val_loader): #print(batch,inp.shape,targ.shape)
batch_loss = val_step(inp, targ)
val_total_loss += batch_loss if batch % 20 == 0: print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1,batch,batch_loss.numpy()[0]))
val_loss_list.append(val_total_loss.numpy()[0] / val_batch_num)
print('val Epoch {} avaLoss {:.4f}'.format(epoch + 1,val_total_loss.numpy()[0] / val_batch_num))
print('Time taken for 1 epoch {}h\n'.format((time.time() - start)/3600))train()
paddle.save(encoder.state_dict(), "/home/aistudio/output/encoder.pdparams") paddle.save(decoder.state_dict(), "/home/aistudio/output/decoder.pdparams") paddle.save(optim.state_dict(), "/home/aistudio/output/optim.pdopt")
def draw_loss(a,b):
x_list=[] for i in range(len(a)):
x_list.append(i)
plt.title("LOSS")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(x_list,a,marker='s',label="train")
plt.plot(x_list,b,marker='s',label="val")
plt.legend()
plt.savefig('/home/aistudio/output/LOSS.png')
plt.show()
draw_loss(train_loss_list,val_loss_list)训练10个epoch的结果:
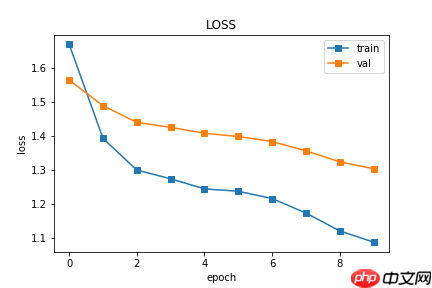
decoder_model_state_dict=paddle.load("/home/aistudio/output/decoder.pdparams")
decoder.set_state_dict(decoder_model_state_dict)
encoder_model_state_dict=paddle.load("/home/aistudio/output/encoder.pdparams")
encoder.set_state_dict(encoder_model_state_dict)def evalute(code):
result=''
# code.shape(1,500)
code=paddle.unsqueeze(code,axis=0)
code_encoding_out,code_encoding_hidden=encoder(code)
hidden=code_encoding_hidden # decoder_input.shape(1,1)
decoder_input=paddle.unsqueeze(paddle.to_tensor([comment_word2id_dict['<start>']]),axis=0)
for i in range(comment_maxlen):
#(batch_size,output_target_len,target_vocab_size)
pre,hidden=decoder(decoder_input,hidden,code_encoding_out)
# 取预测结果中概率最大的值
pred_id=paddle.argmax(pre[0]).numpy()
if comment_id2word_dict.get(pred_id[0])=='<end>': return result
result+=comment_id2word_dict.get(pred_id[0])+' '
# fed back
decoder_input=paddle.unsqueeze(paddle.to_tensor(pred_id),0)
return resultdef translate():
with open('/home/aistudio/output/result.txt','w+') as re: #for i in tqdm(range(len(test_code_tensor))):
for i in tqdm(range(5)):
result=evalute(paddle.to_tensor(test_code_tensor[i])) print('')
re.write(result+'\n')
translate()10个epoch的结果不理想(很差),后续继续炼丹
with open('/home/aistudio/output/result.txt','r') as re:
pre=re.readlines()with open(code_path,'r') as scode:
code=scode.readlines()with open(comment_path,'r') as scomment:
comment=scomment.readlines()for i in range(5): print('code: ', code[i].strip()) print('真实 comment : ',comment[i].strip()) print('预测 comment:',pre[i])code: public synchronized void info ( string msg ) { log record record = new log record ( level . info , msg ) ; log ( record ) ; }
真实 comment : logs a info message
预测 comment: log a message to the log file .
code: public void handle gateway receiver create ( gateway receiver recv ) throws management exception { if ( ! is service initialised ( str_ ) ) { return ; } if ( ! recv . is manual start ( ) ) { return ; } create gateway receiver m bean ( recv ) ; }
真实 comment : handles gateway receiver creation
预测 comment: handles gateway receiver that will be used by the target gateway .
code: public void data changed ( i data provider data provider ) ;
真实 comment : this method will be notified by data provider whenever the data changed in data provider
预测 comment: called when data has changed .
code: public void range ( i hypercube space , i visit kd node visitor ) { if ( root == null ) { return ; } root . range ( space , visitor ) ; }
真实 comment : locate all points within the twodtree that fall within the given ihypercube and visit those nodes via the given visitor .
预测 comment: sets the range of the given sequence .
code: public void handle disk creation ( disk store disk ) throws management exception { if ( ! is service initialised ( str_ ) ) { return ; } disk store m bean bridge bridge = new disk store m bean bridge ( disk ) ; disk store mx bean disk store m bean = new disk store m bean ( bridge ) ; object name disk store m bean name = m bean jmx adapter . get disk store m bean name ( cache impl . get distributed system ( ) . get distributed member ( ) , disk . get name ( ) ) ; object name changed m bean name = service . register internal m bean ( disk store m bean , disk store m bean name ) ; service . federate ( changed m bean name , disk store mx bean . class , bool_ ) ; notification notification = new notification ( jmx notification type . dis k_ stor e_ created , member source , sequence number . next ( ) , system . current time millis ( ) , management constants . dis k_ stor e_ create d_ prefix + disk . get name ( ) ) ; member level notif emitter . send notification ( notification ) ; member m bean bridge . add disk store ( disk ) ; }
真实 comment : handles disk creation .
预测 comment: handles the disk cache for the given session .以上就是【NLP】基于Seq2Seq的代码注释自动生成技术研究的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 999
999























