本文介绍了轻量级通用视觉Transformer——MobileViT,它结合CNN与ViT优势,适用于移动设备,性能优于MobileNetV3等网络,且泛化、鲁棒性更佳。文中给出其PaddlePaddle实现代码,定义数据集、数据增强,构建模型,设置优化器等进行训练,并与MobileNetV2做对比实验,验证了MobileViT的有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

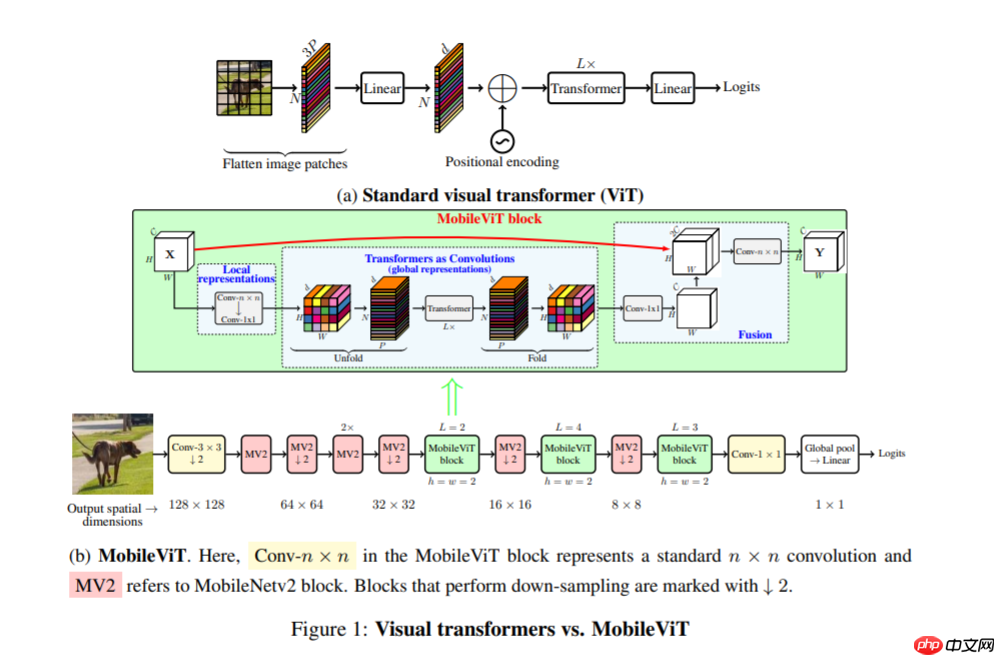
MobileViT 与 Mobilenet 系列模型一样模型的结构都十分简单
#!unzip -oq data/data110994/work.zip -d work/
import paddle
paddle.seed(8888)import numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 10, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':20, 'batch_size': 64, 'lr': 0.01}#数据集的定义class TowerDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(TowerDataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))训练集样本量: 1309,验证集样本量: 328
import paddleimport paddle.nn as nndef conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2D(inp, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
nn.Silu()
)def conv_nxn_bn(inp, oup, kernal_size=3, stride=1):
return nn.Sequential(
nn.Conv2D(inp, oup, kernal_size, stride, 1, bias_attr=False),
nn.BatchNorm2D(oup),
nn.Silu()
)class PreNorm(nn.Layer):
def __init__(self, axis, fn):
super().__init__()
self.norm = nn.LayerNorm(axis)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Layer):
def __init__(self, axis, hidden_axis, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(axis, hidden_axis),
nn.Silu(),
nn.Dropout(dropout),
nn.Linear(hidden_axis, axis),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)class Attention(nn.Layer):
def __init__(self, axis, heads=8, axis_head=64, dropout=0.):
super().__init__()
inner_axis = axis_head * heads
project_out = not (heads == 1 and axis_head == axis)
self.heads = heads
self.scale = axis_head ** -0.5
self.attend = nn.Softmax(axis = -1)
self.to_qkv = nn.Linear(axis, inner_axis * 3, bias_attr = False)
self.to_out = nn.Sequential(
nn.Linear(inner_axis, axis),
nn.Dropout(dropout)
) if project_out else nn.Identity() def forward(self, x):
q,k,v = self.to_qkv(x).chunk(3, axis=-1)
b,p,n,hd = q.shape
b,p,n,hd = k.shape
b,p,n,hd = v.shape
q = q.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
k = k.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
v = v.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
dots = paddle.matmul(q, k.transpose((0, 1, 2, 4, 3))) * self.scale
attn = self.attend(dots)
out = (attn.matmul(v)).transpose((0, 1, 3, 2, 4)).reshape((b, p, n,-1)) return self.to_out(out)class Transformer(nn.Layer):
def __init__(self, axis, depth, heads, axis_head, mlp_axis, dropout=0.):
super().__init__()
self.layers = nn.LayerList([]) for _ in range(depth):
self.layers.append(nn.LayerList([
PreNorm(axis, Attention(axis, heads, axis_head, dropout)),
PreNorm(axis, FeedForward(axis, mlp_axis, dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x return xclass MV2Block(nn.Layer):
def __init__(self, inp, oup, stride=1, expansion=4):
super().__init__()
self.stride = stride assert stride in [1, 2]
hidden_axis = int(inp * expansion)
self.use_res_connect = self.stride == 1 and inp == oup if expansion == 1:
self.conv = nn.Sequential( # dw
nn.Conv2D(hidden_axis, hidden_axis, 3, stride, 1, groups=hidden_axis, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # pw-linear
nn.Conv2D(hidden_axis, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
) else:
self.conv = nn.Sequential( # pw
nn.Conv2D(inp, hidden_axis, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # dw
nn.Conv2D(hidden_axis, hidden_axis, 3, stride, 1, groups=hidden_axis, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # pw-linear
nn.Conv2D(hidden_axis, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
) def forward(self, x):
if self.use_res_connect: return x + self.conv(x) else: return self.conv(x)class MobileViTBlock(nn.Layer):
def __init__(self, axis, depth, channel, kernel_size, patch_size, mlp_axis, dropout=0.):
super().__init__()
self.ph, self.pw = patch_size
self.conv1 = conv_nxn_bn(channel, channel, kernel_size)
self.conv2 = conv_1x1_bn(channel, axis)
self.transformer = Transformer(axis, depth, 1, 32, mlp_axis, dropout)
self.conv3 = conv_1x1_bn(axis, channel)
self.conv4 = conv_nxn_bn(2 * channel, channel, kernel_size)
def forward(self, x):
y = x.clone() # Local representations
x = self.conv1(x)
x = self.conv2(x)
# Global representations
n, c, h, w = x.shape
x = x.transpose((0,3,1,2)).reshape((n,self.ph * self.pw,-1,c))
x = self.transformer(x)
x = x.reshape((n,h,-1,c)).transpose((0,3,1,2)) # Fusion
x = self.conv3(x)
x = paddle.concat((x, y), 1)
x = self.conv4(x) return xclass MobileViT(nn.Layer):
def __init__(self, image_size, axiss, channels, num_classes, expansion=4, kernel_size=3, patch_size=(2, 2)):
super().__init__()
ih, iw = image_size
ph, pw = patch_size assert ih % ph == 0 and iw % pw == 0
L = [2, 4, 3]
self.conv1 = conv_nxn_bn(3, channels[0], stride=2)
self.mv2 = nn.LayerList([])
self.mv2.append(MV2Block(channels[0], channels[1], 1, expansion))
self.mv2.append(MV2Block(channels[1], channels[2], 2, expansion))
self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion))
self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion)) # Repeat
self.mv2.append(MV2Block(channels[3], channels[4], 2, expansion))
self.mv2.append(MV2Block(channels[5], channels[6], 2, expansion))
self.mv2.append(MV2Block(channels[7], channels[8], 2, expansion))
self.mvit = nn.LayerList([])
self.mvit.append(MobileViTBlock(axiss[0], L[0], channels[5], kernel_size, patch_size, int(axiss[0]*2)))
self.mvit.append(MobileViTBlock(axiss[1], L[1], channels[7], kernel_size, patch_size, int(axiss[1]*4)))
self.mvit.append(MobileViTBlock(axiss[2], L[2], channels[9], kernel_size, patch_size, int(axiss[2]*4)))
self.conv2 = conv_1x1_bn(channels[-2], channels[-1])
self.pool = nn.AvgPool2D(ih//32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias_attr=False) def forward(self, x):
x = self.conv1(x)
x = self.mv2[0](x)
x = self.mv2[1](x)
x = self.mv2[2](x)
x = self.mv2[3](x) # Repeat
x = self.mv2[4](x)
x = self.mvit[0](x)
x = self.mv2[5](x)
x = self.mvit[1](x)
x = self.mv2[6](x)
x = self.mvit[2](x)
x = self.conv2(x)
x = self.pool(x)
x = x.reshape((-1, x.shape[1]))
x = self.fc(x) return xdef mobilevit_xxs():
axiss = [64, 80, 96]
channels = [16, 16, 24, 24, 48, 48, 64, 64, 80, 80, 320] return MobileViT((256, 256), axiss, channels, num_classes=1000, expansion=2)def mobilevit_xs():
axiss = [96, 120, 144]
channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384] return MobileViT((256, 256), axiss, channels, num_classes=1000)def mobilevit_s():
axiss = [144, 192, 240]
channels = [16, 32, 64, 64, 96, 96, 128, 128, 160, 160, 640] return MobileViT((256, 256), axiss, channels, num_classes=100)def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)W1114 16:52:06.385679 263 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W1114 16:52:06.390952 263 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:653: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
[5, 1000] [5, 1000] [5, 100]
if __name__ == '__main__':
img = paddle.rand([5, 3, 256, 256])
vit = mobilevit_xxs()
out = vit(img) print(out.shape)
vit = mobilevit_xs()
out = vit(img) print(out.shape)
vit = mobilevit_s()
out = vit(img) print(out.shape)model = mobilevit_s() model = paddle.Model(model)
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/no_SA')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model1')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())model.fit(train_loader,
eval_loader,
epochs=20,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式model_2 = paddle.vision.models.MobileNetV2(num_classes=10model_2 = paddle.Model(model_2)
#优化器选择class SaveBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.save(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/mobilenet_v2')
callback_savebestmodel = SaveBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_savebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model_2.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())model_2.fit(train_loader,
eval_loader,
epochs=10,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
以上就是Mobile-ViT:改进的一种更小更轻精度更高的模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 419
419























