据统计,2020年全国共接报火灾74.8万起,直接财产损失高达67.5亿元。火灾已经成为危害人们生命财产安全的一种多发性灾害。基于PaddleX实现火灾、烟雾检测,并探索模型的优化历程。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

据统计,2021年全国共接报火灾74.8万起,直接财产损失高达67.5亿元。火灾已经成为危害人们生命财产安全的一种多发性灾害。
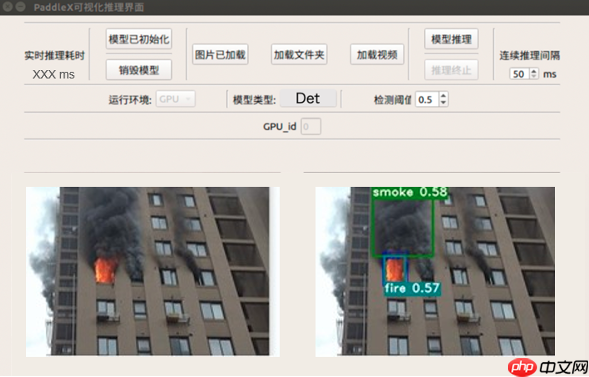
针对住宅、加油站、公路、森林等火灾高发场景,应用飞桨PaddleX的目标检测技术,可以自动检测监控区域内的烟雾和火灾,帮助相关人员及时应对,最大程度降低人员伤亡及财物损失,模型效果如图所示。

希望通过梳理优化模型精度和性能的思路能帮助用户更高效地解决实际火灾和烟雾检测应用中的问题。开放烟雾和火灾数据和预训练模型,并提供服务器Serving和Jetson NX边缘侧芯片的部署指南。
方案难点:
注:本地、服务器运行代码下载和使用教程请参考火灾烟雾检测
安装的相关问题参考PaddleX安装
本项目中已经帮大家下载好了最新版的PaddleX,无需下载,只需安装环境~
如仍需安装or安装更新,可以执行以下步骤
# 项目已提供PaddlePaddleX,无需执行此步骤# !git clone https://github.com/PaddlePaddle/PaddleX.git -b develop
!unzip -q PaddleX.zip
# 安装环境%cd /home/aistudio/PaddleX !git checkout develop !pip install -r requirements.txt !python setup.py install
本案例使用数据集包含MIT协议互联网下载图片和MIT协议公开数据集,共有6675张图片,分别检测烟雾和火灾,示例图片如下图所示:

数据集图片格式是VOC数据格式,VOC数据是每个图像文件对应一个同名的xml文件,xml文件内包含对应图片的基本信息,比如文件名、来源、图像尺寸以及图像中包含的物体区域信息和类别信息等。
xml文件中包含以下字段:
filename,表示图像名称。
size,表示图像尺寸。包括:图像宽度、图像高度、图像深度。
<size>
<width>500</width>
<height>375</height>
<depth>3</depth></size>object字段,表示每个物体。包括:
| 标签 | 说明 |
|---|---|
| name | 物体类别名称 |
| pose | 关于目标物体姿态描述(非必须字段) |
| truncated | 如果物体的遮挡超过15-20%并且位于边界框之外,请标记为truncated(非必须字段) |
| difficult | 难以识别的物体标记为difficult(非必须字段) |
| bndbox子标签 | (xmin,ymin) 左上角坐标,(xmax,ymax) 右下角坐标, |
将这6675张图片按9:1比例随机切分,切分后包含6008张图片的训练集和667张图片的验证集,提供处理好的数据集,下载地址。包含以下文件夹和文件:images,annotations,labels.txt, train_list.txt和 val_list.txt,分别图片、xml标注文件、存储类别信息、训练样本列表、验证样本列表。训练样本列表和验证样本列表的每一行格式为:图片路径 对应的xml路径,例如images/fire_00348.jpg annotations/fire_00348.xml。
数据处理命令如下,执行一次即可。
# 第一次运行项目执行即可!mkdir /home/aistudio/dataset/ %cd /home/aistudio/dataset/ !mv /home/aistudio/data/data107770/train_list.txt ./ !mv /home/aistudio/data/data107770/val_list.txt ./ !mv /home/aistudio/data/data107770/labels.txt ./ !unzip -q /home/aistudio/data/data107770/images.zip -d ./ !unzip -q /home/aistudio/data/data107770/annotations.zip -d ./ %cd ..
最终数据集文件组织结构为:
├── dataset ├── annotations │ ├── fire_000001.xml │ ├── fire_000002.xml │ ├── fire_000003.xml │ | ... ├── images │ ├── fire_000001.jpg │ ├── fire_000003.jpg │ ├── fire_000003.jpg │ | ... ├── label_list.txt ├── train.txt └── valid.txt
PaddleX提供了5种目标检测模型:FasterRCNN、YOLOv3、PP-YOLO、PP-YOLOv2和PP-YOLO-tiny。
Faster RCNN:Ross B. Girshick在2016年提出了新的FasterRCNN,需要先产生候选区域,再对RoI做分类和位置坐标的预测,这类算法被称为两阶段目标检测算法。在结构上,Faster RCNN已经将特征抽取(feature extraction),proposal提取,bounding box regression(rect refine),classification都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
YOLOv3:Joseph Redmon等人在2015年提出YOLO(You Only Look Once,YOLO)算法,通常也被称为YOLOv1;2016年,他们对算法进行改进,又提出YOLOv2版本;2018年发展出YOLOv3版本。YOLOv3使用单个网络结构,在产生候选区域的同时即可预测出物体类别和位置,这类算法被称为单阶段目标检测算法。另外,YOLOv3算法产生的预测框数目比Faster R-CNN少很多。Faster R-CNN中每个真实框可能对应多个标签为正的候选区域,而YOLOv3里面每个真实框只对应一个正的候选区域。这些特性使得YOLOv3算法具有更快的速度,能到达实时响应的水平。
PP-YOLO:PP-YOLO是PaddleDetection优化和改进的YOLOv3的模型,在COCO test-dev2017数据集上精度达到45.9%,在单卡V100上FP32推理速度为72.9 FPS,V100上开启TensorRT下FP16推理速度为155.6 FPS。PP-YOLO从如下方面优化:
PP-YOLOv2:相较20年发布的PP-YOLO,PP-YOLOv2版本在COCO 2017 test-dev上的精度提升了3.6个百分点,由45.9%提升到了49.5%;在640*640的输入尺寸下,FPS达到68.9FPS。 主要改进点:
PP-YOLO-tiny:在当前移动互联网、物联网、车联网等行业迅猛发展的背景下,边缘设备上直接部署目标检测的需求越来越旺盛。生产线上往往需要在极低硬件成本的硬件例如树莓派、FPGA、K210 等芯片上部署目标检测算法。而我们常用的手机 App,也很难直接在终端采用超过 6M 的深度学习算法。如何在尽量不损失精度的前提下,获得体积更小、运算速度更快的算法呢?得益于 PaddleSlim 飞桨模型压缩工具的能力,体积仅为 1.3M 的 PP-YOLO-tiny 诞生了!PP-YOLO-tiny 沿用了 PP-YOLO 系列模型的 spp,iou loss, drop block, mixup, sync bn 等优化方法,并进一步采用了针对移动端的优化策略:
根据部署场景以及烟火检测实时性、高召回低误检要求,这里我们选择了PP-YOLOv2算法进行火灾和烟雾检测。
本项目采用PP-YOLOv2作为烟火检测的模型,模型训练需要经过如下环节:

具体代码请参考train.py,可修改参数:
PaddleX提供了单卡/多卡训练模型,满足用户多种训练需求:
%cd /home/aistudio/code/
/home/aistudio/code
# GPU单卡训练%cd /home/aistudio/code/# 可以在code文件夹内选择不同的训练文件进行训练,每个文件使用的策略参考本项目10.3小节!export CUDA_VISIBLE_DEVICES=0!python 1.train_ppyolov2_imagenet.py# GPU多卡训练,例如使用2张卡时执行:# export CUDA_VISIBLE_DEVICES=0,1 #windows和Mac下不需要执行该命令# python -m paddle.distributed.launch --gpus 0,1 1.train_ppyolov2_imagenet.py
因为采用多个数据集一起训练,每个数据集标注方式不同,如下图左数据集A将火标注为一个检测框,但是下图右数据集B又将火标注为多个检测框。

不同的标注方式就导致训练好的模型,无法有效的计算mAP值。我们可以通过下图从两方面分析:

综上,我们计算不同置信度阈值下图片级召回率和图片级误检率,找到符合要求的召回率和误检率,对应的置信度阈值用于后续模型预测阶段。使用PP-YOLOv2训练好的模型进行评估,评估数据暂未公开,大家可以按照下面步骤准备数据集:
1)新建文件夹eval_imgs
!mkdir /home/aistudio/dataset/eval_imgs/
!mkdir /home/aistudio/dataset/eval_imgs/fire_smoke/
!mkdir /home/aistudio/dataset/eval_imgs/neg_pics/
4)生成图片列表TXT文件,正样本标签为1,负样本标签为0,格式如下:
fire_smoke/00001.jpg 1fire_smoke/00002.jpg 1... neg_pics/00001.jpg 0
代码实现:
!python gen_txt.py
# 评估数据未公开,按上面步骤准备好验证集,即可以执行该命令!python metric.py
得到PP-YOLOv2烟雾和火灾检测指标,召回相对达到预期,但是召回比较高,后续我们将一起探究如何降低误检率:
| 模型 | 召回率/% | 误检率/% |
|---|---|---|
| PP-YOLOv2+ResNet50 | 95.1 | 23.22 |
【名词解释】
加载训练好的模型,置信度阈值设置为0.4,执行下行命令对验证集或测试集图片进行预测:
# 模型路径、测试图片路径、结果保存路径、阈值可在predict.py文件内修改# 如果报错可以检查模型路径等是否正确!python predict.py
可视化预测结果示例如下,可以看出室内的火灾也可以有效检测出来:

注:图片来源于互联网,侵权删稿
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型
# 根据具体使用的训练文件,修改模型路径model_dir!paddlex --export_inference --model_dir=/home/aistudio/code/output/ppyolov2_r50vd_dcn/best_model/ --save_dir=/home/aistudio/code/inference_model
预测模型会导出到inference_model/目录下,包括model.pdmodel、model.pdiparams、model.pdiparams.info、model.yml和pipeline.yml五个文件,分别表示模型的网络结构、模型权重、模型权重名称、模型的配置文件(包括数据预处理参数等)和可用于PaddleX Manufacture SDK的流程配置文件。
接下来使用PaddleX python高性能预测接口,在终端输入以下代码即可,同时可以通过以下代码进行速度预测:
!python infer.py
关于预测速度的说明:加载模型后,前几张图片的预测速度会较慢,这是因为运行启动时涉及到内存显存初始化等步骤,通常在预测20-30张图片后模型的预测速度达到稳定。如果需要评估预测速度,可通过指定预热轮数warmup_iters完成预热。为获得更加精准的预测速度,可指定repeats重复预测后取时间平均值。
本小节侧重展示在模型迭代过程中优化精度的思路,在本案例中,有些优化策略获得了精度收益,而有些没有。在其他质检场景中,可根据实际情况尝试这些优化策略,具体请参考模型优化文档
修改图片尺寸:数据处理时,可修改target_size为480、608、640等
数据增强:数据处理时,使用不同的预处理、增强方法组合,包含:RandomHorizontalFlip、RandomDistort 、 RandomCrop 、RandomExpand、MixupImage等,详细解释请参考图像预处理/增强
不同模型:单阶段(YOLOv3、PP-YOLO、PP-YOLOv2等)
不同backbone:ResNet50、ResNet101、DarkNet53、MobileNet3,具体每个模型可选参数,可参考检测模型文件每个模型的backbone,如YOLOV3,就表示这些模型可以作为YOLOV3的backbone:
if backbone not in [ 'MobileNetV1', 'MobileNetV1_ssld', 'MobileNetV3', 'MobileNetV3_ssld', 'DarkNet53', 'ResNet50_vd_dcn', 'ResNet34'
]:是否加DCN(Deformable Convolution Network,可变形卷积):FasterRCNN通过设置with_dcn=True使用可变性卷积
加入背景图片:当误检较高时,可以考虑使用add_negative_samplesAPI加入背景图片作为负样本进行训练,只需一行代码即可,image_dir表示负样本路径:
train_dataset.add_negative_samples(image_dir='/home/aistudio/dataset/train_neg')
训练参数调整
采用PaddleX在单卡Tesla V100上测试模型的推理时间(输入数据拷贝至GPU的时间、计算时间、数据拷贝至CPU的时间),推理时间取100次推理取平均耗时,即9 模型推理repeats参数设置为100。
我们可以运行code文件夹下的训练文件,进行不同模型的训练,文件名的第一个数字和下表的序号相对应。
| 序号 | 模型 | 推理时间(FPS) | Recall | Error Rate |
|---|---|---|---|---|
| 1 | PP-YOLOv2+ResNet50+ImageNet预训练(Baseline) | 24 | 95.1 | 23.22 |
| 2 | PP-YOLOv2+ResNet50+ImageNet预训练+aug | - | 94.1 | 14.9 |
| 3 | PP-YOLOv2+ResNet50+COCO预训练 | - | 97.4 | 28.6 |
| 4 | PP-YOLOv2+ResNet50+COCO预训练+aug | - | 96.3 | 11.1 |
| 5 | PP-YOLOv2+ResNet50+COCO预训练+aug+SPP=False | - | 96 | 13.21 |
| 6 | PP-YOLOv2+ResNet50+aug+COCO预训练+背景图 | 23.6 | 93.9 | 1.1 |
| 7 | PP-YOLOv2+ResNet101+aug+COCO预训练+背景图 | 21 | 96 | 2.2 |
| 8 | PP-YOLO+ResNet50+COCO预训练+aug | 20 | 90.0 | 8.81 |
| 9 | YOLOv3+DarkNet53+COCO预训练+img_size(640) | 21 | 88.4 | 6.01 |
说明:
从表1的实验结论中可以发现,有些优化策略在精度优化上起到了正向结果,有些策略则相反。这些结论在不同的模型和不同的数据集上并不是相通的,还需根据具体情况验证。
本实验未提供"背景图"数据集(包含5116张图片),大家自行选择不包含的烟雾和火灾的数据作为负样本即可。
模型优化思路:
通过以上的简单优化方式,获取了两个较好的模型结果:【前者模型速度更快、后者召回更高】
| 模型 | 推理时间(FPS) | Recall | Error Rate |
|---|---|---|---|
| PP-YOLOv2+ResNet50+aug+COCO预训练+SPP+背景图 | 23.6 | 93.9 | 1.1 |
| PP-YOLOv2+ResNet101+aug+COCO预训练+SPP+背景图 | 21 | 96 | 2.2 |
在项目中为用户提供了基于Jetson NX的部署Demo方案,支持用户输入单张图片、文件夹、视频流进行预测。用户可根据实际情况自行参考。
部署方式可以参考:兼容并包的PaddleX-Inference部署方式和基于QT的Jetson Xavier部署Demo。
以上就是基于PP-YOLOv2的火灾/烟雾检测的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 783
783























