本文复现了SegNet语义分割模型,其为编码器-解码器结构,编码器对应VGG-16前13层,解码器共13层,损失函数采用带median frequency weight的加权交叉熵。在Ai Studio环境配置后,基于PaddleSeg,经模型搭建、损失函数设计及调参,在camvid数据集上复现,结果超原论文60.1%的mIoU精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文名称:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
论文地址:https://arxiv.org/pdf/1511.00561.pdf
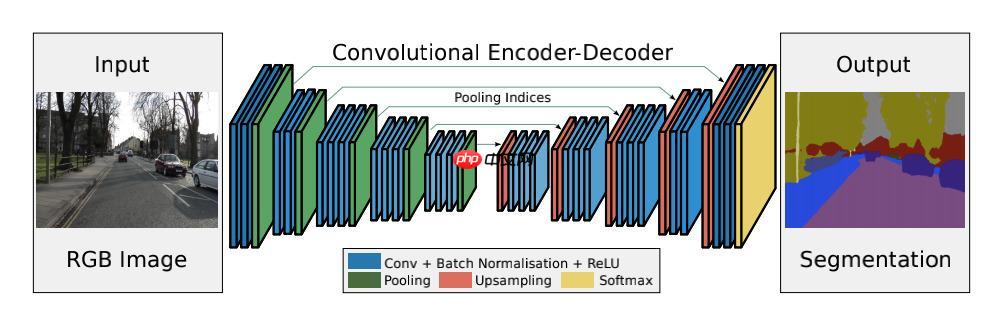
总体结构是一个“编码器——解码器”最后加上Softmax层的结构
编码器与VGG-16的前13层,相对应的,解码器也是13层
使用的是交叉熵函数
原论文使用的是“median frequency weight”的加权交叉熵进行计算,每一类的 weight=median(weights)/weights
实验时我们同时使用了不加权重的交叉熵和加权重的交叉熵进行计算,发现加权重的交叉熵效果的确更好
由于 Ai Studio 的部分兼容问题,目前使用加权交叉熵需要修改 PaddlePaddle 内置的交叉熵函数,可以在终端中执行如下命令进行暂时的修复:
1.使用 vim 编辑文件:
vim /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/functional/loss.py
2.注释掉问题语句:
:1414,1420s/^/#/g
之后就可以使用 Ai Studio 环境进行复现
在 config.yml 中可以对训练、验证参数进行设置
batch_size: 12 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大iters: 1000 #模型迭代的次数train_dataset: #训练数据设置
type: Dataset #选择数据集格式
dataset_root: data/PaddleSeg/camvid #选择数据集路径
train_path: data/PaddleSeg/camvid/train_list.txt #选择数据集list
num_classes: 12 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #送入网络之前需要进行resize
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: RandomHorizontalFlip #采用水平反转的方式进行数据增强
- type: Normalize #图像进行归一化
mode: trainval_dataset: #验证数据设置
type: Dataset #选择数据集格式
dataset_root: data/PaddleSeg/camvid #选择数据集路径
val_path: data/PaddleSeg/camvid/val_list.txt #选择数据集list
num_classes: 12 #指定目标的类别个数(背景也算为一类)
transforms: #数据预处理/增强的方式
- type: Resize #将原图resize成512*512在送入网络
target_size: [512, 512] #将原图resize成512*512在送入网络
- type: Normalize #图像进行归一化
mode: valoptimizer: #设定优化器的类型
type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合learning_rate: #设定学习率
value: 0.1 #初始学习率
decay:
type: poly #采用poly作为学习率衰减方式。
power: 0.9 #衰减率
end_lr: 0 #最终学习率loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #损失函数类型
coef: [1]model: #模型说明
type: SegNet #设定模型类别
num_classes: 12
快速开始命令介绍:
cd PaddleSeg
python train.py \ # 使用 PaddleSeg 进行训练
--config config.yml \ # 配置文件路径
--do_eval \ # 在保存模型时验证
--use_vdl \ # 使用 visualdl 保存日志
--save_interval 500 \ # 保存模型的频率
--save_dir output # 模型及日志保存路径
训练日志可以在 github 项目下载:https://github.com/stuartchen1949/segnet_paddle/tree/main/log_upload
下面截取部分信息展示: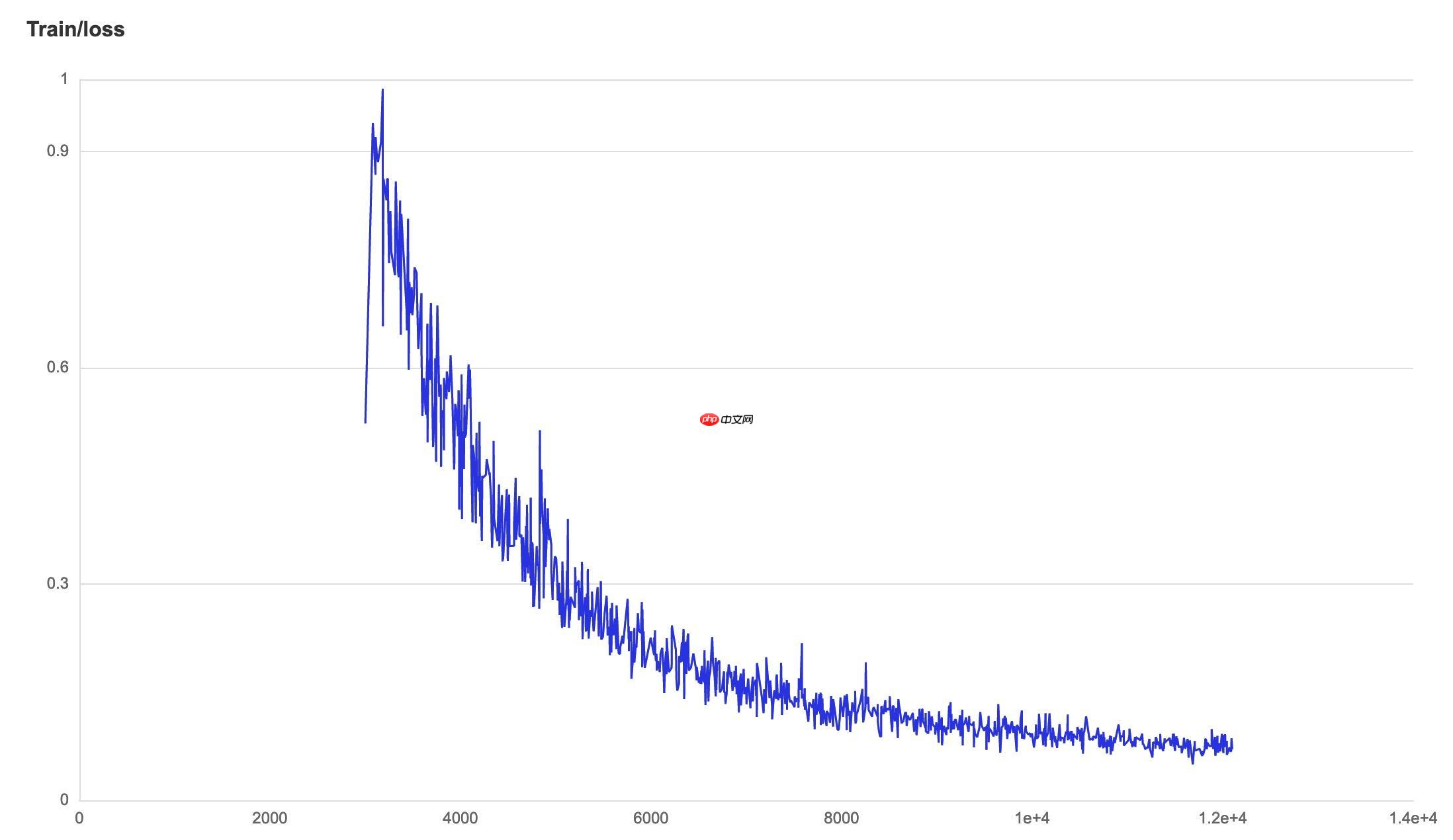
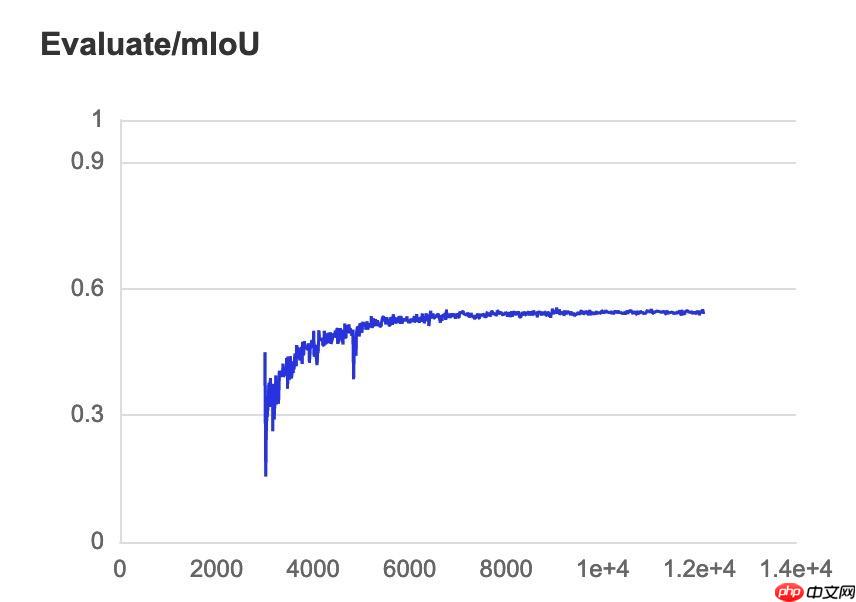
最好是按照原论文的超参数进行复现,这样工作量低
在本论文中,bs=12,lr=0.1,使用 SGD 方法,动量为0.9 但是也可以另辟蹊径,比如:分阶段训练,每个阶段设置学习率不同
截至2021年8月18日,在解码器的 unpool 过程中,Paddle 并无对应的 API,所以在本次复现使用的是 Paddle 的 interpolate 函数,插值方式设置的是“双三次插值”
本项目为“飞桨论文复现挑战赛(第四期)”参赛作品,比赛链接:https://aistudio.baidu.com/aistudio/competition/detail/106
目的是复现论文“SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation”

原论文使用“camvid 11类”数据集达到 miou 精度 60.1% ,我们的结果为 0.5553/11*12=0.605 >60.1% (因为最后一类是void,原论文并未计算,需要消除这个影响)
由于属于 语义分割 问题,故使用 Paddle 的 PaddleSeg 模块进行快速开发
PaddleSeg 快速指南:https://github.com/PaddlePaddle/PaddleSeg/blob/release/2.2/docs/quick_start.md
为了实现复现任务,我们只需要:
1.定义模型并添加至 PaddleSeg 的模型库中
2.计算出交叉熵的权值并修改 PaddleSeg 的 交叉熵函数.py
3.创建 config.py 文件设置超参数
原论文使用的是“median frequency weight”的加权交叉熵进行计算,每一类的 weight=median(weights)/weights
按照原论文的数据进行设置即可
batch_size: 12iters: 10000train_dataset:
type: Dataset
dataset_root: PaddleSeg/camvid
train_path: PaddleSeg/camvid/train_list.txt
num_classes: 12
transforms:
# - type: Resize
# target_size: [512, 512]
# - type: RandomHorizontalFlip
- type: Normalize
mode: trainval_dataset:
type: Dataset
dataset_root: PaddleSeg/camvid
val_path: PaddleSeg/camvid/val_list.txt
num_classes: 12
transforms:
# - type: Resize
# target_size: [512, 512]
- type: Normalize
mode: valoptimizer:
type: sgd
momentum: 0.9
weight_decay: 4.0e-5lr_scheduler:
type: PolynomialDecay
learning_rate: 0.1
end_lr: 0
power: 0.9loss:
types:
- type: CrossEntropyLoss
coef: [1]model:
type: SegNet
num_classes: 12import paddlefrom paddle import nnimport paddle.nn.functional as Ffrom paddleseg.cvlibs import manager@manager.LOSSES.add_componentclass CrossEntropyLoss(nn.Layer):
"""
Implements the cross entropy loss function.
Args:
weight (tuple|list|ndarray|Tensor, optional): A manual rescaling weight
given to each class. Its length must be equal to the number of classes.
Default ``None``.
ignore_index (int64, optional): Specifies a target value that is ignored
and does not contribute to the input gradient. Default ``255``.
top_k_percent_pixels (float, optional): the value lies in [0.0, 1.0]. When its value < 1.0, only compute the loss for
the top k percent pixels (e.g., the top 20% pixels). This is useful for hard pixel mining. Default ``1.0``.
data_format (str, optional): The tensor format to use, 'NCHW' or 'NHWC'. Default ``'NCHW'``.
"""
def __init__(self,
weight= # None,
# [0.49470329175952255,
# 0.35828960644888747,
# 8.478075684728779,
# 0.2632281509876036,
# 1.8575191953843206,
# 0.8569813461262166,
# 7.10457223748049,
# 7.395517740818225,
# 1.4206921357883606,
# 13.036496170307238,
# 28.57158303913671,
# # 2.1105473453421433
# 0],
[0.5183676152953121, 0.3754285285214713, 8.883627718253265, 0.2758197715255286, 1.946374345422177, 0.8979753806852697, 7.444422201714914, 7.749285195873823, 1.4886514942686155, 13.660102013013443, 29.938315778195324, 0],
ignore_index=11,
top_k_percent_pixels=1.0,
data_format='NCHW'):
super(CrossEntropyLoss, self).__init__() # if weight is not None:
# weight = paddle.to_tensor(weight, dtype='float32')
if weight is not None:
self.weight = paddle.to_tensor(weight, dtype='float32')
long_weight = weight + [0] * (256 - len(weight))
self.long_weight = paddle.to_tensor(long_weight, dtype='float32') else:
self.weight = None
self.long_weight = None
# self.weight = weight
self.ignore_index = 11
self.top_k_percent_pixels = top_k_percent_pixels
self.EPS = 1e-8
self.data_format = data_format def forward(self, logit, label, semantic_weights=None):
"""
Forward computation.
Args:
logit (Tensor): Logit tensor, the data type is float32, float64. Shape is
(N, C), where C is number of classes, and if shape is more than 2D, this
is (N, C, D1, D2,..., Dk), k >= 1.
label (Tensor): Label tensor, the data type is int64. Shape is (N), where each
value is 0 <= label[i] <= C-1, and if shape is more than 2D, this is
(N, D1, D2,..., Dk), k >= 1.
semantic_weights (Tensor, optional): Weights about loss for each pixels, shape is the same as label. Default: None.
"""
channel_axis = 1 if self.data_format == 'NCHW' else -1
if self.weight is not None and logit.shape[channel_axis] != len(
self.weight): raise ValueError( 'The number of weights = {} must be the same as the number of classes = {}.'
.format(len(self.weight), logit.shape[1]))
logit = paddle.transpose(logit, [0, 2, 3, 1]) # logit = paddle.transpose(logit, [0, 2, 1])
loss = F.cross_entropy(
logit,
label,
ignore_index=self.ignore_index,
reduction='none', # weight=self.weight
weight=self.long_weight)
mask = label != self.ignore_index
mask = paddle.cast(mask, 'float32')
loss = loss * mask if semantic_weights is not None:
loss = loss * semantic_weights if self.weight is not None:
_one_hot = F.one_hot(label, logit.shape[-1])
coef = paddle.sum(_one_hot * self.weight, axis=-1) else:
coef = paddle.ones_like(label)
label.stop_gradient = True
mask.stop_gradient = True
if self.top_k_percent_pixels == 1.0:
avg_loss = paddle.mean(loss) / (paddle.mean(mask * coef) + self.EPS) return avg_loss
loss = loss.reshape((-1, ))
top_k_pixels = int(self.top_k_percent_pixels * loss.numel())
loss, indices = paddle.topk(loss, top_k_pixels)
coef = coef.reshape((-1, ))
coef = paddle.gather(coef, indices)
coef.stop_gradient = True
return loss.mean() / (paddle.mean(coef) + self.EPS)# 解压数据!unzip -oq /home/aistudio/data/data79232/camvid.zip
# 创建listimport osdir = "camvid"%cd camvid
!touch train_list.txt
!touch val_list.txt
%cd
names = os.listdir(os.path.join(dir, "train"))
l = len(names)print("总共%d个数据" %l)
n = 0for name in names: with open("camvid/train_list.txt","r+") as f:
f.read() # t = "camvid/train/" + name + " camvid/trainannot/" + name + "\n"
t = "train/" + name + " trainannot/" + name + "\n"
f.write(t)
n+=1
# with open("train_list.txt","r+") as f:
# f.read()
# t = "camvid/train/" + name + " camvid/trainannot/" + name + "\n"
# f.write(t)
# n+=1
print("已写入%d路径" %n)dir = "camvid"names = os.listdir(os.path.join(dir, "val"))
l = len(names)print("总共%d个数据" %l)
n = 0for name in names: with open("camvid/val_list.txt","r+") as f:
f.read() # t = "camvid/val/" + name + " camvid/valannot/" + name + "\n"
t = "val/" + name + " valannot/" + name + "\n"
f.write(t)
n+=1
# with open("val_list.txt","r+") as f:
# f.read()
# t = "camvid/val/" + name + " camvid/valannot/" + name + "\n"
# f.write(t)
# n+=1
print("已写入%d路径" %n)dir = "camvid"# %cd camvid!touch train_list.txt# !touch val_list.txt# %cdnames = os.listdir(os.path.join(dir, "train"))
l = len(names)print("总共%d个数据" %l)
n = 0for name in names: with open("train_list.txt","r+") as f:
f.read()
t = "camvid/train/" + name + " camvid/trainannot/" + name + "\n"
f.write(t)
n+=1
print("已写入%d路径" %n)# 平衡数据集 lossimport cv2 as cvimport numpy as np
paths = open("train_list.txt", "r")
CLASS_NUM = 11SUM = [[] for i in range(CLASS_NUM)]
SUM_ = 0for line in paths:
line.rstrip("\n")
line.lstrip("\n")
path = line.split()
img = cv.imread(path[1], 0)
img_np = np.array(img) for i in range(CLASS_NUM):
SUM[i].append(np.sum((img_np == i)))for index, iter in enumerate(SUM): print("类别{}的数量:".format(index), sum(iter))for iter in SUM:
SUM_ += sum(iter)
median = 1/CLASS_NUMfor index, iter in enumerate(SUM): print("weight_{}:".format(index), median/(sum(iter)/SUM_))# 安装 paddleseg!git clone https://gitee.com/paddlepaddle/PaddleSeg.git !pip install PaddleSeg
# 覆写损失函数!cp cross_entropy_loss.py PaddleSeg/paddleseg/models/losses/# 添加自定义 model!cp my_model.py PaddleSeg/paddleseg/models !cp __init__.py PaddleSeg/paddleseg/models
# 训练一 3000 iter ,模型保存至output!python PaddleSeg/train.py \
--config config.yml \
--do_eval \
--use_vdl \
--save_interval 100 \
--log_iters 1 \
--save_dir output \
--iters 3000 \
--keep_checkpoint_max 10 \
--batch_size 12# 训练二 36000 iter (只训练到了12111),从output读取模型,保存至output1!python PaddleSeg/train.py \
--config config.yml \
--do_eval \
--use_vdl \
--save_interval 1 \
--log_iters 1 \
--save_dir output_1 \
--iters 36000 \
--keep_checkpoint_max 10 \
--resume_model output/iter_3000 \
--batch_size 12# 计算miou,选取output1最好模型!python PaddleSeg/val.py \
--config config.yml \
--model_path output_1/best_model/model.pdparams # --model_path model.pdparams # 复制到/home/aistudio文件夹了以上就是基于 PaddlePaddle 框架的 SegNet 论文复现的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 977
977






















