
【问题说明】
在生产环境中添加了新的副本集成员(secondary):10.9.197.6:27017,数据量为140G。然而,该成员同步了一天后仍未追上主节点的数据。通过以下方式查看同步情况:
查看主从复制状态的命令,以下两种方式的结果是一致的:
方式一:
use admin
db.runCommand( { replSetGetStatus : 1 } )指定的值不会影响命令的输出。此命令提供的数据源自于包含在由副本集的其他成员发送到当前实例的心跳中的数据。由于心跳的频率,这些数据可能是几秒钟过期。详情请参考官档:https://www.php.cn/link/5fc4698a9539a70b368c5aa9736c49eb
方式二:
rs.status()
查看复制状态,发现状态是"stateStr" : "RECOVERING"。信息为"infoMessage" : "could not find member to sync from",使用 rs.syncFrom("10.9.161.130:27017") 也无法让其继续正常同步。具体信息如下:
kk-comic-shard01:RECOVERING> rs.status() {
"set" : "kk-comic-shard01",
"date" : ISODate("2017-02-07T02:12:17.613Z"),
"myState" : 3,
"term" : NumberLong(5),
"heartbeatIntervalMillis" : NumberLong(2000),
"members" : [
{
"_id" : 2,
"name" : "10.9.95.69:27017",
"health" : 1,
"state" : 7,
"stateStr" : "ARBITER",
"uptime" : 41966,
"lastHeartbeat" : ISODate("2017-02-07T02:12:14.490Z"),
"lastHeartbeatRecv" : ISODate("2017-02-07T02:12:15.696Z"),
"pingMs" : NumberLong(0),
"configVersion" : 19
},
{
"_id" : 4,
"name" : "10.9.161.130:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 41966,
"optime" : {
"ts" : Timestamp(1486433534, 636),
"t" : NumberLong(5)
},
"optimeDate" : ISODate("2017-02-07T02:12:14Z"),
"lastHeartbeat" : ISODate("2017-02-07T02:12:14.489Z"),
"lastHeartbeatRecv" : ISODate("2017-02-07T02:12:16.435Z"),
"pingMs" : NumberLong(0),
"electionTime" : Timestamp(1486103572, 783),
"electionDate" : ISODate("2017-02-03T06:32:52Z"),
"configVersion" : 19
},
{
"_id" : 5,
"name" : "10.9.184.101:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 41966,
"optime" : {
"ts" : Timestamp(1486433534, 629),
"t" : NumberLong(5)
},
"optimeDate" : ISODate("2017-02-07T02:12:14Z"),
"lastHeartbeat" : ISODate("2017-02-07T02:12:14.489Z"),
"lastHeartbeatRecv" : ISODate("2017-02-07T02:12:16.438Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "10.9.161.130:27017",
"configVersion" : 19
},
{
"_id" : 6,
"name" : "10.9.197.6:27017",
"health" : 1,
"state" : 3,
"stateStr" : "RECOVERING",
"uptime" : 41985,
"optime" : {
"ts" : Timestamp(1486391572, 534),
"t" : NumberLong(5)
},
"optimeDate" : ISODate("2017-02-06T14:32:52Z"),
"maintenanceMode" : 487,
"infoMessage" : "could not find member to sync from",
"configVersion" : 19,
"self" : true
}
],
"ok" : 1
}kk-comic-shard01:RECOVERING> rs.printSlaveReplicationInfo() source: 10.9.184.101:27017 syncedTo: Tue Feb 07 2017 10:15:24 GMT+0800 (CST) 0 secs (0 hrs) behind the primary source: 10.9.197.6:27017 syncedTo: Mon Feb 06 2017 22:32:52 GMT+0800 (CST) 42152 secs (11.71 hrs) behind the primary
【问题原因】
主要问题在于新加入的secondary节点最后一个操作时间为“2017-02-06T14:32:52Z”,而主节点的最后一个操作时间为“2017-02-07T02:12:14.489Z”,相差约12小时。这个时间差可能超过了oplog窗口(oplog中第一个和最后一个操作条目之间的时间差)。换句话说,主节点上的操作量太大,导致secondary节点无法赶上。
在初始同步期间,secondary节点同步的是特定时间点的数据。当该时间点的数据被同步后,secondary节点会连接到oplog并应用从该时间点开始的oplog条目中的更改。只要oplog保存了该时间点之间的所有操作,secondary节点就可以正常同步。但是,oplog的大小是有限的,它是一个固定大小的集合。如果在初始同步期间主节点上的操作量超过了oplog能够保存的范围,最早的操作会被删除(“fade out”)。因此,secondary节点无法“构建”与主节点相同的数据,导致同步无法完成,状态一直处于RECOVERY模式。
【解决办法】
根据上述分析,有两种解决办法:
方法一:停止应用,使得主节点不再有新的操作,从而不会使得oplog窗口小于主节点的操作。
方法二:增大oplog的大小。
在不能停库的情况下,显然方法一不适用,因此应选择方法二:增大oplog的大小。
修改oplog大小
方法1:不停服务情况下
参考官档:https://www.php.cn/link/fb02df1865e291f64cc263d80f5ae3a5
Restart a Secondary in Standalone Mode on a Different Port
db.shutdownServer()
用其他端口以单机模式重新启动该实例,不使用--replSet参数。
方法一:根据生产环境参数文件设置启动mongo,即将非默认情况参数进行指定。以下参数根据生产参数文件来设置,情况不一:
/data/servers/app/mongodb-3.2.8/bin/mongod --port 37017 --dbpath /data/servers/data/mg27017/data/ --directoryperdb --wiredTigerDirectoryForIndexes --nojournal &
该方法较为麻烦,建议选择下面的方法二:
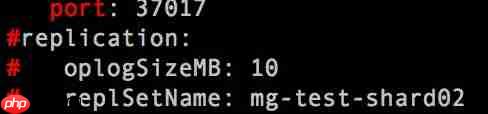
方法二:将参数文件进行修改:注释replSet部分,修改port为37017,然后以改完后的控制文件来启动mongo。
/data/servers/app/mongodb-3.2.8/bin/mongod -f /data/servers/data/mg27017/mongod.conf
下面截图显示的是只要更改的部分,端口号改为任意的没被占用的即可,此处改为37017。
netstat -anp | grep $port查看端口号是否已启动。

Create a Backup of the Oplog (Optional)
在单机模式(非replSet方式)下备份该37017端口已存在的oplog,oplog对应的集合为local数据库下的oplog.rs。下面为具体命令:
/data/servers/app/mongodb-3.2.8/bin/mongodump --db local --collection 'oplog.rs' --port 37017 --host=127.0.0.1 -uroot -p111111111 --authenticationDatabase=admin -o /data/servers/data/mg27017/dump
【命令说明】
-o(--out)是指定输出目录。该目录需要执行备份的用户拥有相应权限,不用提前创建。--authenticationDatabase是用户名和密码对应的认证数据库,如果环境不需要密码认证,则-u、-p、--authenticationDatabase不需要指定。Recreate the Oplog with a New Size and a Seed Entry
保存oplog中的最后一个条目。
登陆local数据库:
use local
定义对象:db
db = db.getSiblingDB('local')使用temp集合来保存最后一个条目,这个集合保证里面没有数据:db.temp.drop(),在删除前确认下该数据是否可以删除,如果不可以删除,使用另一个集合也是一样的。此处temp没有数据。

使用db.collection.save()方法:找到自然顺序的逆向排序后的最后一个条目,并将其保存到一个临时的集合里面。
db.temp.save( db.oplog.rs.find( { }, { ts: 1, h: 1 } ).sort( {$natural : -1} ).limit(1).next() )插入后结果为:

Remove the Existing Oplog Collection
删除local下的oplog.rs集合,结果返回为true。
db = db.getSiblingDB('local')
db.oplog.rs.drop()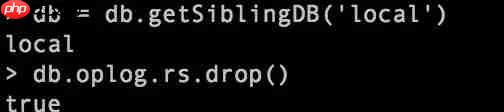
Create a New Oplog
创建oplog.rs固定集合,设置大小为4G,该大小根据实际情况来定。
db.runCommand( { create: "oplog.rs", capped: true, size: (4 * 1024 * 1024 * 1024) } )Insert the Last Entry of the Old Oplog into the New Oplog
将之前保存的oplog的最后一个条目插入到新的oplog里。
db.oplog.rs.save( db.temp.findOne() )
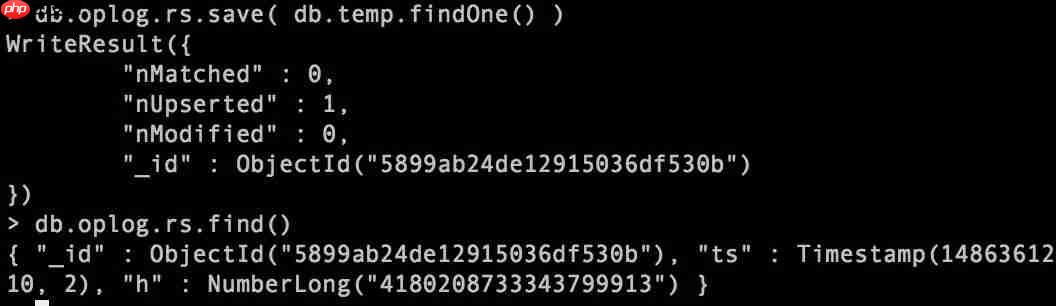
跟temp结果比对是一致的。
Restart the Member
关闭单机实例,要用admin才能关闭。
use admin db.shutdownServer()
将之前更改的操作还原,启动mongo。
/data/servers/app/mongodb-3.2.8/bin/mongod -f /data/servers/data/mg27017/mongod.conf
查看主从复制状态,确保状态正常。
db.runCommand( { replSetGetStatus : 1 } ) 或者 rs.status()Repeat Process for all Members that may become Primary
对要更改oplog大小的所有secondary成员重复此过程。
Change the Size of the Oplog on the Primary
对于主库,需要先将主库切成从库,再重复上述oplog调整过程。
方法一:
rs.stepDown()
方法二:
config=rs.conf() config.members[2].priority = 6 rs.reconfig(config)
此处数字2为rs.conf()里要变成主库的secondary所在的次序,从0开始算,与id无关。priority数字最大即变成主库。旧的主库调整完后,记得要将priority变为1。
方法2:停服务情况下
该方法操作最为简便,但是需要停服务。具体步骤为:
关闭mongod实例(所有节点)
use admin db.shutdownServer()
删除local数据库下的所有文件(PRIMARY节点)
rm -rf /data/servers/data/mg27017/local/*
删除mongo数据目录(secondary)
如果不确定谁是主库,就mv下数据目录。
rm -rf /data/servers/data/mg27017/data/*
修改所有节点配置文件(oplogsize)
oplogSizeMB: 4096
重启所有节点mongod
/data/servers/app/mongodb-3.2.8/bin/mongod -f /data/servers/data/mg27017/mongod.conf
该方法会导致主库如果异常,没有从库可切换,不建议使用该方式。
【小节】
设置多大的oplog合适呢,可以根据现在数据大小,io和大致的oplog window时间预估一个合适的大小。
rs.printReplicationInfo()
log length start to end:当oplog写满时可以理解为时间窗口。oplog last event time:最后一个操作发生的时间。以上就是MongoDB更改oplog大小的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 144
144























