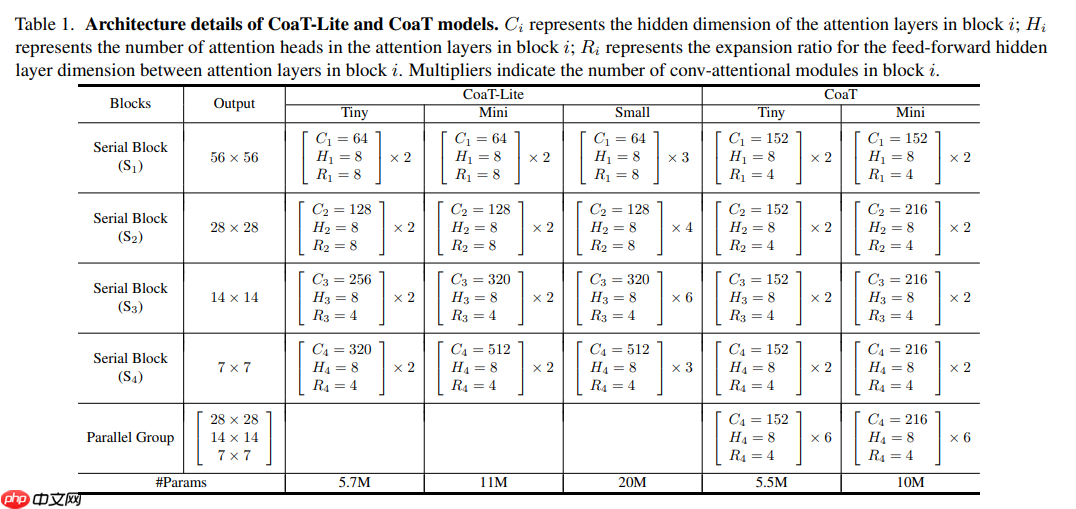
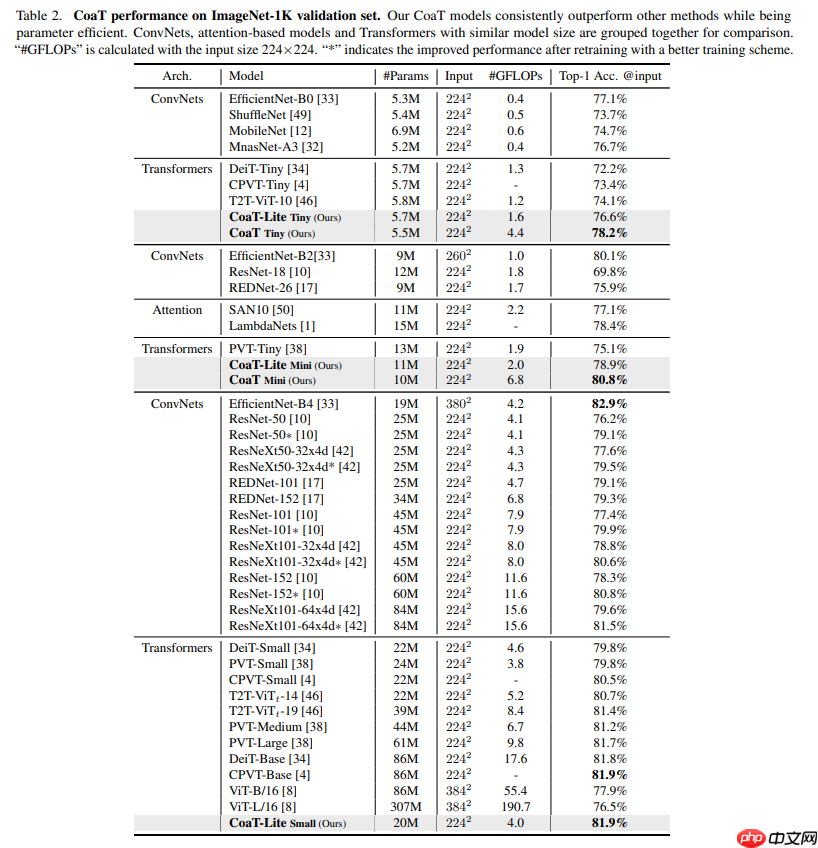
本文介绍基于Transformer的图像分类器CoaT,其含Co-Scale和Conv-Attentional机制,能为Vision Transformer提供多尺度和上下文建模功能,性能超T2T-ViT等网络。还阐述了Conv-Attention模块、Co-Scale机制的原理与代码实现,搭建了模型并验证了精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜




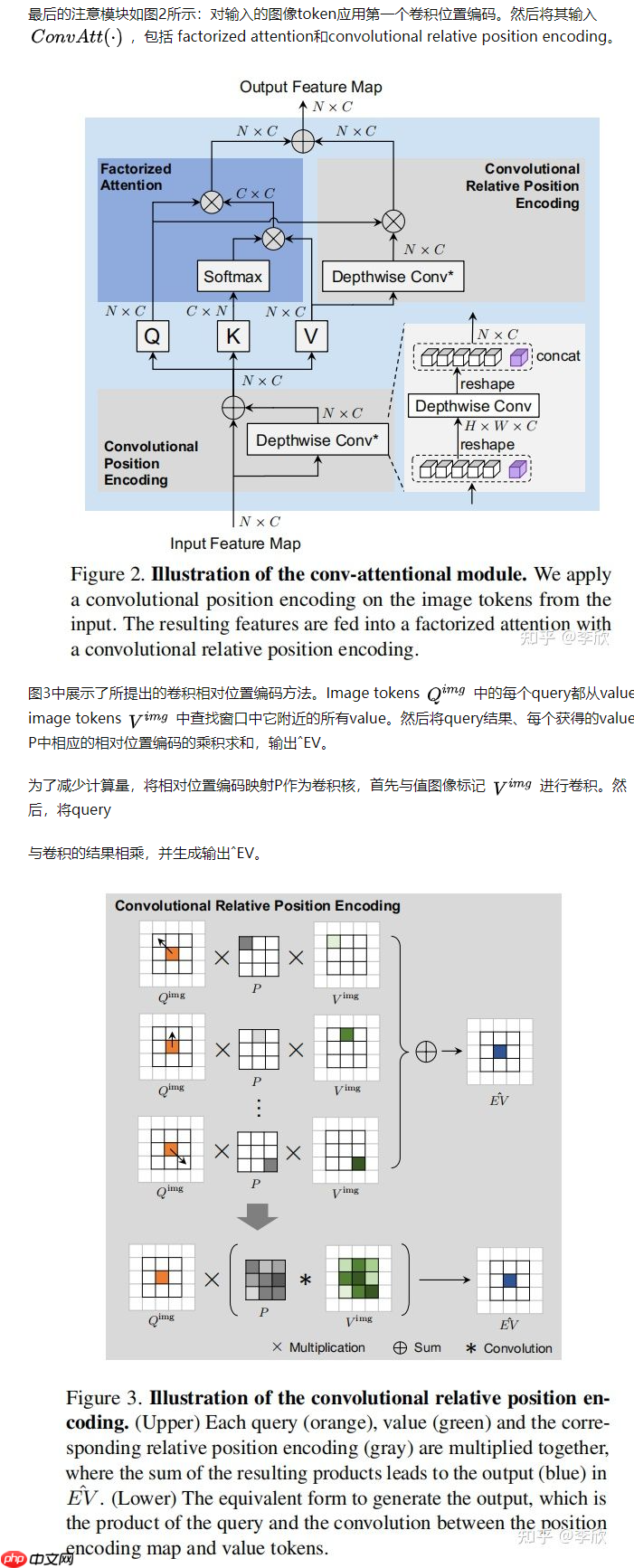
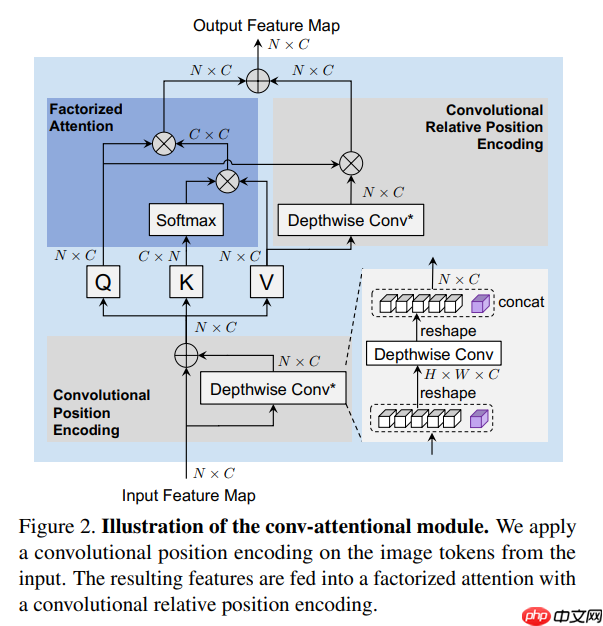
class ConvRelPosEnc(nn.Layer):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window):
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__() if isinstance(window, int): # Set the same window size for all attention heads.
window = {window: h}
self.window = window elif isinstance(window, dict):
self.window = window else: raise ValueError()
self.conv_list = nn.LayerList()
self.head_splits = [] for cur_window, cur_head_split in window.items(): # Use dilation=1 at default.
dilation = 1
padding_size = (cur_window + (cur_window - 1)
* (dilation - 1)) // 2
cur_conv = nn.Conv2D(cur_head_split*Ch, cur_head_split*Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split*Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x*Ch for x in self.head_splits] def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size assert N == 1 + H * W # Convolutional relative position encoding.
# Shape: [B, h, H*W, Ch].
q_img = q[:, :, 1:, :] # Shape: [B, h, H*W, Ch].
v_img = v[:, :, 1:, :] # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img = v_img.reshape((B, h, H, W, Ch))
v_img = v_img.transpose((0, 1, 4, 2, 3))
v_img = v_img.flatten(1, 2) # v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W)
# Split according to channels.
v_img_list = paddle.split(v_img, self.channel_splits, axis=1)
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)]
conv_v_img = paddle.concat(conv_v_img_list, axis=1) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
conv_v_img = conv_v_img.reshape((B, h, Ch, H, W))
conv_v_img = conv_v_img.transpose((0, 1, 3, 4, 2))
conv_v_img = conv_v_img.flatten(2, 3) # conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h)
EV_hat_img = q_img * conv_v_img
zero = paddle.zeros((B, h, 1, Ch), dtype=q.dtype) # Shape: [B, h, N, Ch].
EV_hat = paddle.concat((zero, EV_hat_img), axis=2) return EV_hatclass FactorAtt_ConvRelPosEnc(nn.Layer):
""" Factorized attention with convolutional relative position encoding class. """
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., shared_crpe=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) # Note: attn_drop is actually not used.
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) # Shared convolutional relative position encoding.
self.crpe = shared_crpe def forward(self, x, size):
B, N, C = x.shape # Generate Q, K, V.
# Shape: [3, B, h, N, Ch].
qkv = self.qkv(x).reshape(
(B, N, 3, self.num_heads, C // self.num_heads)
).transpose((2, 0, 3, 1, 4)) # Shape: [B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Factorized attention.
# Softmax on dim N.
k_softmax = nn.functional.softmax(k, axis=2) # Shape: [B, h, Ch, Ch].
k_softmax_T_dot_v = paddle.matmul(k_softmax.transpose((0, 1, 3, 2)), v) # k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v)
# Shape: [B, h, N, Ch].
# factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v)
factor_att = paddle.matmul(q, k_softmax_T_dot_v) # Convolutional relative position encoding.
# Shape: [B, h, N, Ch].
crpe = self.crpe(q, v, size=size) # Merge and reshape.
x = self.scale * factor_att + crpe # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
x = x.transpose((0, 2, 1, 3)).reshape((B, N, C)) # Output projection.
x = self.proj(x)
x = self.proj_drop(x) # Shape: [B, N, C].
return xclass ConvPosEnc(nn.Layer):
""" Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2D(dim, dim, k, 1, k//2, groups=dim) def forward(self, x, size):
B, N, C = x.shape
H, W = size assert N == 1 + H * W # Extract CLS token and image tokens.
# Shape: [B, 1, C], [B, H*W, C].
cls_token, img_tokens = x[:, :1], x[:, 1:] # Depthwise convolution.
feat = img_tokens.transpose((0, 2, 1)).reshape((B, C, H, W))
x = self.proj(feat) + feat
x = x.flatten(2).transpose((0, 2, 1)) # Combine with CLS token.
x = paddle.concat((cls_token, x), axis=1) return x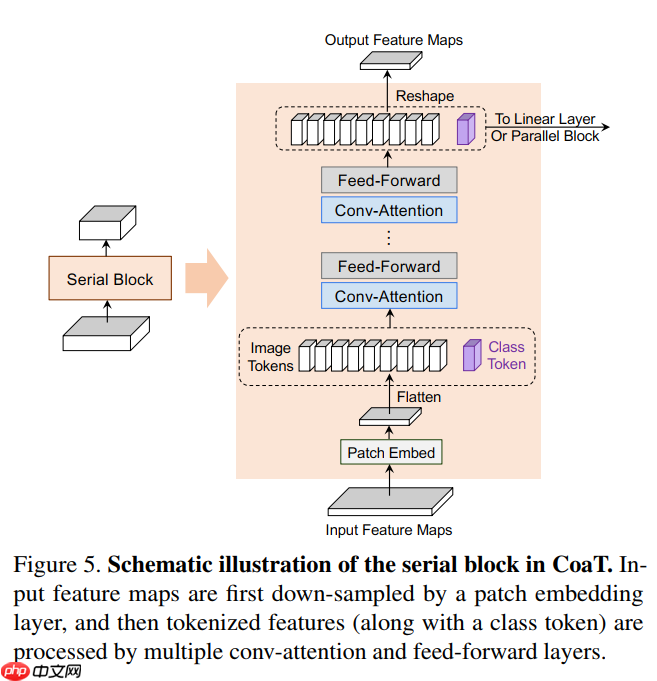
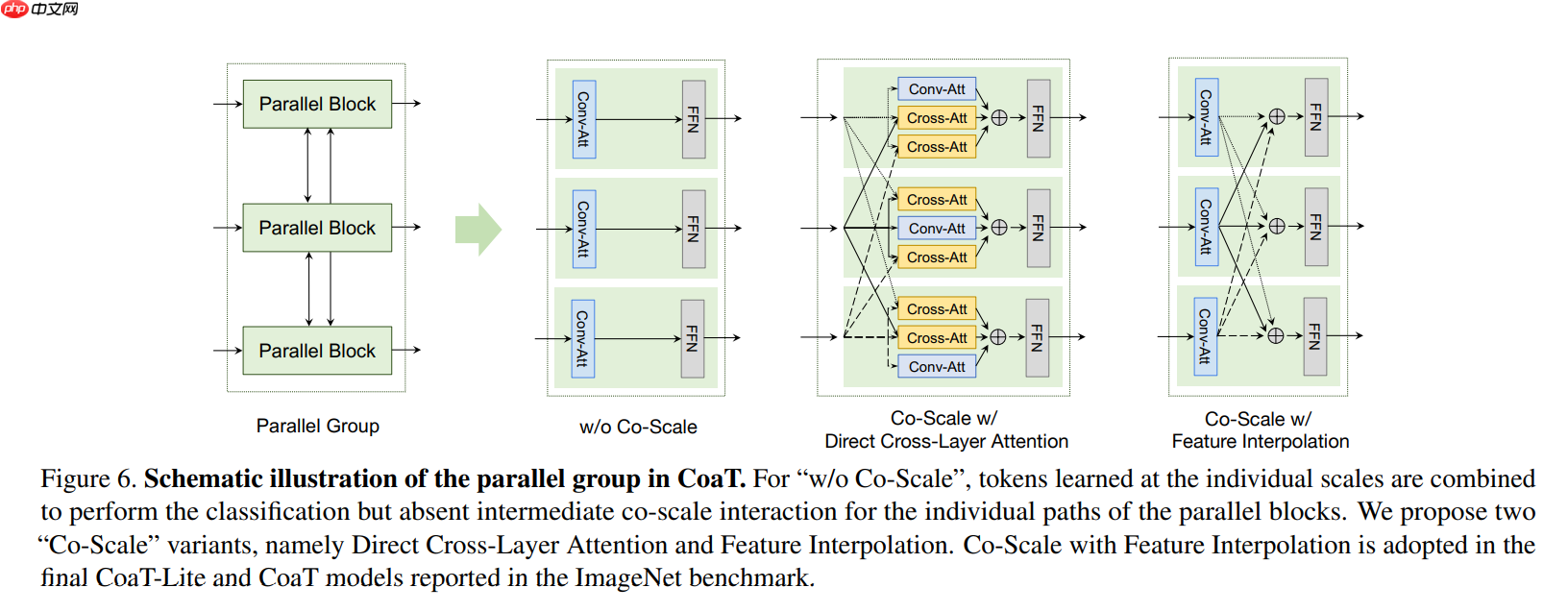
class SerialBlock(nn.Layer):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
shared_cpe=None, shared_crpe=None):
super().__init__() # Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
shared_crpe=shared_crpe
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() # MLP.
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(
in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
) def forward(self, x, size):
# Conv-Attention.
# Apply convolutional position encoding.
x = self.cpe(x, size)
cur = self.norm1(x) # Apply factorized attention and convolutional relative position encoding.
cur = self.factoratt_crpe(cur, size)
x = x + self.drop_path(cur) # MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur) return xclass ParallelBlock(nn.Layer):
""" Parallel block class. """
def __init__(self, dims, num_heads, mlp_ratios=[], qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
shared_cpes=None, shared_crpes=None):
super().__init__() # Conv-Attention.
self.cpes = shared_cpes
self.norm12 = norm_layer(dims[1], epsilon=epsilon)
self.norm13 = norm_layer(dims[2], epsilon=epsilon)
self.norm14 = norm_layer(dims[3], epsilon=epsilon)
self.factoratt_crpe2 = FactorAtt_ConvRelPosEnc(
dims[1], num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[1]
)
self.factoratt_crpe3 = FactorAtt_ConvRelPosEnc(
dims[2], num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[2]
)
self.factoratt_crpe4 = FactorAtt_ConvRelPosEnc(
dims[3], num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[3]
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity() # MLP.
self.norm22 = norm_layer(dims[1], epsilon=epsilon)
self.norm23 = norm_layer(dims[2], epsilon=epsilon)
self.norm24 = norm_layer(dims[3], epsilon=epsilon) # In parallel block, we assume dimensions are the same and share the linear transformation.
assert dims[1] == dims[2] == dims[3] assert mlp_ratios[1] == mlp_ratios[2] == mlp_ratios[3]
mlp_hidden_dim = int(dims[1] * mlp_ratios[1])
self.mlp2 = self.mlp3 = self.mlp4 = Mlp(
in_features=dims[1],
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop
) def upsample(self, x, factor, size):
""" Feature map up-sampling. """
return self.interpolate(x, scale_factor=factor, size=size) def downsample(self, x, factor, size):
""" Feature map down-sampling. """
return self.interpolate(x, scale_factor=1.0/factor, size=size) def interpolate(self, x, scale_factor, size):
""" Feature map interpolation. """
B, N, C = x.shape
H, W = size assert N == 1 + H * W
cls_token = x[:, :1, :]
img_tokens = x[:, 1:, :]
img_tokens = img_tokens.transpose((0, 2, 1)).reshape((B, C, H, W))
img_tokens = F.interpolate(
img_tokens,
scale_factor=scale_factor,
mode='bilinear'
)
img_tokens = img_tokens.reshape((B, C, -1)).transpose((0, 2, 1))
out = paddle.concat((cls_token, img_tokens), axis=1) return out def forward(self, x1, x2, x3, x4, sizes):
_, (H2, W2), (H3, W3), (H4, W4) = sizes # Conv-Attention.
x2 = self.cpes[1](x2, size=(H2, W2)) # Note: x1 is ignored.
x3 = self.cpes[2](x3, size=(H3, W3))
x4 = self.cpes[3](x4, size=(H4, W4))
cur2 = self.norm12(x2)
cur3 = self.norm13(x3)
cur4 = self.norm14(x4)
cur2 = self.factoratt_crpe2(cur2, size=(H2, W2))
cur3 = self.factoratt_crpe3(cur3, size=(H3, W3))
cur4 = self.factoratt_crpe4(cur4, size=(H4, W4))
upsample3_2 = self.upsample(cur3, factor=2, size=(H3, W3))
upsample4_3 = self.upsample(cur4, factor=2, size=(H4, W4))
upsample4_2 = self.upsample(cur4, factor=4, size=(H4, W4))
downsample2_3 = self.downsample(cur2, factor=2, size=(H2, W2))
downsample3_4 = self.downsample(cur3, factor=2, size=(H3, W3))
downsample2_4 = self.downsample(cur2, factor=4, size=(H2, W2))
cur2 = cur2 + upsample3_2 + upsample4_2
cur3 = cur3 + upsample4_3 + downsample2_3
cur4 = cur4 + downsample3_4 + downsample2_4
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4) # MLP.
cur2 = self.norm22(x2)
cur3 = self.norm23(x3)
cur4 = self.norm24(x4)
cur2 = self.mlp2(cur2)
cur3 = self.mlp3(cur3)
cur4 = self.mlp4(cur4)
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4) return x1, x2, x3, x4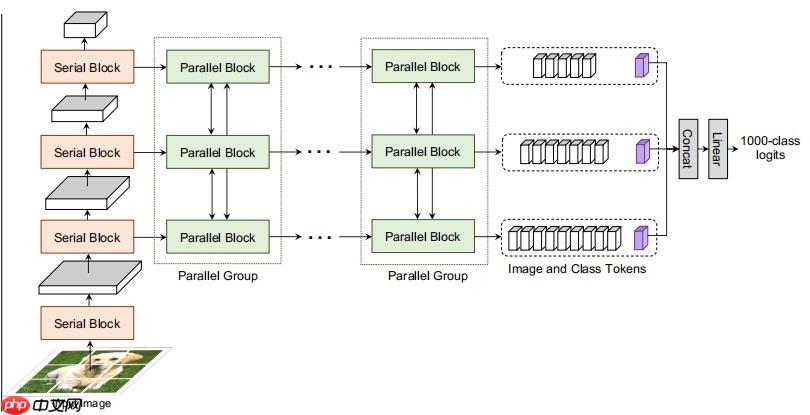
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom common import DropPath, Identityfrom common import to_2tuple, add_parameterfrom common import trunc_normal_, ones_, zeros_class Mlp(nn.Layer):
""" Feed-forward network (FFN, a.k.a. MLP) class. """
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass ConvRelPosEnc(nn.Layer):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window):
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__() if isinstance(window, int): # Set the same window size for all attention heads.
window = {window: h}
self.window = window elif isinstance(window, dict):
self.window = window else: raise ValueError()
self.conv_list = nn.LayerList()
self.head_splits = [] for cur_window, cur_head_split in window.items(): # Use dilation=1 at default.
dilation = 1
padding_size = (cur_window + (cur_window - 1)
* (dilation - 1)) // 2
cur_conv = nn.Conv2D(cur_head_split*Ch, cur_head_split*Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split*Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x*Ch for x in self.head_splits] def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size assert N == 1 + H * W # Convolutional relative position encoding.
# Shape: [B, h, H*W, Ch].
q_img = q[:, :, 1:, :] # Shape: [B, h, H*W, Ch].
v_img = v[:, :, 1:, :] # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img = v_img.reshape((B, h, H, W, Ch))
v_img = v_img.transpose((0, 1, 4, 2, 3))
v_img = v_img.flatten(1, 2) # v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W)
# Split according to channels.
v_img_list = paddle.split(v_img, self.channel_splits, axis=1)
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)]
conv_v_img = paddle.concat(conv_v_img_list, axis=1) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
conv_v_img = conv_v_img.reshape((B, h, Ch, H, W))
conv_v_img = conv_v_img.transpose((0, 1, 3, 4, 2))
conv_v_img = conv_v_img.flatten(2, 3) # conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h)
EV_hat_img = q_img * conv_v_img
zero = paddle.zeros((B, h, 1, Ch), dtype=q.dtype) # Shape: [B, h, N, Ch].
EV_hat = paddle.concat((zero, EV_hat_img), axis=2) return EV_hatclass FactorAtt_ConvRelPosEnc(nn.Layer):
""" Factorized attention with convolutional relative position encoding class. """
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., shared_crpe=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias) # Note: attn_drop is actually not used.
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) # Shared convolutional relative position encoding.
self.crpe = shared_crpe def forward(self, x, size):
B, N, C = x.shape # Generate Q, K, V.
# Shape: [3, B, h, N, Ch].
qkv = self.qkv(x).reshape(
(B, N, 3, self.num_heads, C // self.num_heads)
).transpose((2, 0, 3, 1, 4)) # Shape: [B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Factorized attention.
# Softmax on dim N.
k_softmax = nn.functional.softmax(k, axis=2) # Shape: [B, h, Ch, Ch].
k_softmax_T_dot_v = paddle.matmul(k_softmax.transpose((0, 1, 3, 2)), v) # k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v)
# Shape: [B, h, N, Ch].
# factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v)
factor_att = paddle.matmul(q, k_softmax_T_dot_v) # Convolutional relative position encoding.
# Shape: [B, h, N, Ch].
crpe = self.crpe(q, v, size=size) # Merge and reshape.
x = self.scale * factor_att + crpe # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
x = x.transpose((0, 2, 1, 3)).reshape((B, N, C)) # Output projection.
x = self.proj(x)
x = self.proj_drop(x) # Shape: [B, N, C].
return xclass ConvPosEnc(nn.Layer):
""" Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2D(dim, dim, k, 1, k//2, groups=dim) def forward(self, x, size):
B, N, C = x.shape
H, W = size assert N == 1 + H * W # Extract CLS token and image tokens.
# Shape: [B, 1, C], [B, H*W, C].
cls_token, img_tokens = x[:, :1], x[:, 1:] # Depthwise convolution.
feat = img_tokens.transpose((0, 2, 1)).reshape((B, C, H, W))
x = self.proj(feat) + feat
x = x.flatten(2).transpose((0, 2, 1)) # Combine with CLS token.
x = paddle.concat((cls_token, x), axis=1) return xclass SerialBlock(nn.Layer):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
shared_cpe=None, shared_crpe=None):
super().__init__() # Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim, epsilon=epsilon)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpe)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else Identity() # MLP.
self.norm2 = norm_layer(dim, epsilon=epsilon)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop) def forward(self, x, size):
# Conv-Attention.
# Apply convolutional position encoding.
x = self.cpe(x, size)
cur = self.norm1(x) # Apply factorized attention and convolutional relative position encoding.
cur = self.factoratt_crpe(cur, size)
x = x + self.drop_path(cur) # MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur) return xclass ParallelBlock(nn.Layer):
""" Parallel block class. """
def __init__(self, dims, num_heads, mlp_ratios=[], qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, epsilon=1e-6,
shared_cpes=None, shared_crpes=None):
super().__init__() # Conv-Attention.
self.cpes = shared_cpes
self.norm12 = norm_layer(dims[1], epsilon=epsilon)
self.norm13 = norm_layer(dims[2], epsilon=epsilon)
self.norm14 = norm_layer(dims[3], epsilon=epsilon)
self.factoratt_crpe2 = FactorAtt_ConvRelPosEnc(
dims[1], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[1]
)
self.factoratt_crpe3 = FactorAtt_ConvRelPosEnc(
dims[2], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[2]
)
self.factoratt_crpe4 = FactorAtt_ConvRelPosEnc(
dims[3], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[3]
)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else Identity() # MLP.
self.norm22 = norm_layer(dims[1], epsilon=epsilon)
self.norm23 = norm_layer(dims[2], epsilon=epsilon)
self.norm24 = norm_layer(dims[3], epsilon=epsilon) # In parallel block, we assume dimensions are the same and share the linear transformation.
assert dims[1] == dims[2] == dims[3] assert mlp_ratios[1] == mlp_ratios[2] == mlp_ratios[3]
mlp_hidden_dim = int(dims[1] * mlp_ratios[1])
self.mlp2 = self.mlp3 = self.mlp4 = Mlp(
in_features=dims[1], hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def upsample(self, x, factor, size):
""" Feature map up-sampling. """
return self.interpolate(x, scale_factor=factor, size=size) def downsample(self, x, factor, size):
""" Feature map down-sampling. """
return self.interpolate(x, scale_factor=1.0/factor, size=size) def interpolate(self, x, scale_factor, size):
""" Feature map interpolation. """
B, N, C = x.shape
H, W = size assert N == 1 + H * W
cls_token = x[:, :1, :]
img_tokens = x[:, 1:, :]
img_tokens = img_tokens.transpose((0, 2, 1)).reshape((B, C, H, W))
img_tokens = F.interpolate(
img_tokens, scale_factor=scale_factor, mode='bilinear')
img_tokens = img_tokens.reshape((B, C, -1)).transpose((0, 2, 1))
out = paddle.concat((cls_token, img_tokens), axis=1) return out def forward(self, x1, x2, x3, x4, sizes):
_, (H2, W2), (H3, W3), (H4, W4) = sizes # Conv-Attention.
x2 = self.cpes[1](x2, size=(H2, W2)) # Note: x1 is ignored.
x3 = self.cpes[2](x3, size=(H3, W3))
x4 = self.cpes[3](x4, size=(H4, W4))
cur2 = self.norm12(x2)
cur3 = self.norm13(x3)
cur4 = self.norm14(x4)
cur2 = self.factoratt_crpe2(cur2, size=(H2, W2))
cur3 = self.factoratt_crpe3(cur3, size=(H3, W3))
cur4 = self.factoratt_crpe4(cur4, size=(H4, W4))
upsample3_2 = self.upsample(cur3, factor=2, size=(H3, W3))
upsample4_3 = self.upsample(cur4, factor=2, size=(H4, W4))
upsample4_2 = self.upsample(cur4, factor=4, size=(H4, W4))
downsample2_3 = self.downsample(cur2, factor=2, size=(H2, W2))
downsample3_4 = self.downsample(cur3, factor=2, size=(H3, W3))
downsample2_4 = self.downsample(cur2, factor=4, size=(H2, W2))
cur2 = cur2 + upsample3_2 + upsample4_2
cur3 = cur3 + upsample4_3 + downsample2_3
cur4 = cur4 + downsample3_4 + downsample2_4
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4) # MLP.
cur2 = self.norm22(x2)
cur3 = self.norm23(x3)
cur4 = self.norm24(x4)
cur2 = self.mlp2(cur2)
cur3 = self.mlp3(cur3)
cur4 = self.mlp4(cur4)
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4) return x1, x2, x3, x4class PatchEmbed(nn.Layer):
""" Image to Patch Embedding """
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \ f"img_size {img_size} should be divided by patch_size {patch_size}."
# Note: self.H, self.W and self.num_patches are not used
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1] # since the image size may change on the fly.
self.num_patches = self.H * self.W
self.proj = nn.Conv2D(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim) def forward(self, x):
_, _, H, W = x.shape
out_H, out_W = H // self.patch_size[0], W // self.patch_size[1]
x = self.proj(x).flatten(2).transpose((0, 2, 1))
out = self.norm(x) return out, (out_H, out_W)class CoaT(nn.Layer):
""" CoaT class. """
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dims=[0, 0, 0, 0],
serial_depths=[0, 0, 0, 0], parallel_depth=0, num_heads=0,
mlp_ratios=[0, 0, 0, 0], qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm, epsilon=1e-6,
return_interm_layers=False, out_features=None,
crpe_window={3: 2, 5: 3, 7: 3}, class_dim=1000,
**kwargs):
super().__init__()
self.return_interm_layers = return_interm_layers
self.out_features = out_features
self.class_dim = class_dim # Patch embeddings.
self.patch_embed1 = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
self.patch_embed2 = PatchEmbed(
img_size=img_size // 4, patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed3 = PatchEmbed(
img_size=img_size // 8, patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed4 = PatchEmbed(
img_size=img_size // 16, patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3]) # Class tokens.
self.cls_token1 = add_parameter(
self, paddle.zeros((1, 1, embed_dims[0])))
self.cls_token2 = add_parameter(
self, paddle.zeros((1, 1, embed_dims[1])))
self.cls_token3 = add_parameter(
self, paddle.zeros((1, 1, embed_dims[2])))
self.cls_token4 = add_parameter(
self, paddle.zeros((1, 1, embed_dims[3]))) # Convolutional position encodings.
self.cpe1 = ConvPosEnc(dim=embed_dims[0], k=3)
self.cpe2 = ConvPosEnc(dim=embed_dims[1], k=3)
self.cpe3 = ConvPosEnc(dim=embed_dims[2], k=3)
self.cpe4 = ConvPosEnc(dim=embed_dims[3], k=3) # Convolutional relative position encodings.
self.crpe1 = ConvRelPosEnc(
Ch=embed_dims[0] // num_heads, h=num_heads, window=crpe_window)
self.crpe2 = ConvRelPosEnc(
Ch=embed_dims[1] // num_heads, h=num_heads, window=crpe_window)
self.crpe3 = ConvRelPosEnc(
Ch=embed_dims[2] // num_heads, h=num_heads, window=crpe_window)
self.crpe4 = ConvRelPosEnc(
Ch=embed_dims[3] // num_heads, h=num_heads, window=crpe_window) # Disable stochastic depth.
dpr = drop_path_rate assert dpr == 0.0
# Serial blocks 1.
self.serial_blocks1 = nn.LayerList([
SerialBlock(
dim=embed_dims[0], num_heads=num_heads, mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer, epsilon=epsilon,
shared_cpe=self.cpe1, shared_crpe=self.crpe1
) for _ in range(serial_depths[0])]
) # Serial blocks 2.
self.serial_blocks2 = nn.LayerList([
SerialBlock(
dim=embed_dims[1], num_heads=num_heads, mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer, epsilon=epsilon,
shared_cpe=self.cpe2, shared_crpe=self.crpe2
) for _ in range(serial_depths[1])]
) # Serial blocks 3.
self.serial_blocks3 = nn.LayerList([
SerialBlock(
dim=embed_dims[2], num_heads=num_heads, mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer, epsilon=epsilon,
shared_cpe=self.cpe3, shared_crpe=self.crpe3
) for _ in range(serial_depths[2])]
) # Serial blocks 4.
self.serial_blocks4 = nn.LayerList([
SerialBlock(
dim=embed_dims[3], num_heads=num_heads, mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer, epsilon=epsilon,
shared_cpe=self.cpe4, shared_crpe=self.crpe4
) for _ in range(serial_depths[3])]
) # Parallel blocks.
self.parallel_depth = parallel_depth if self.parallel_depth > 0:
self.parallel_blocks = nn.LayerList([
ParallelBlock(
dims=embed_dims, num_heads=num_heads, mlp_ratios=mlp_ratios, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer, epsilon=epsilon,
shared_cpes=[self.cpe1, self.cpe2, self.cpe3, self.cpe4],
shared_crpes=[self.crpe1, self.crpe2,
self.crpe3, self.crpe4]
) for _ in range(parallel_depth)]
) # Classification head(s).
if not self.return_interm_layers:
self.norm1 = norm_layer(embed_dims[0], epsilon=epsilon)
self.norm2 = norm_layer(embed_dims[1], epsilon=epsilon)
self.norm3 = norm_layer(embed_dims[2], epsilon=epsilon)
self.norm4 = norm_layer(embed_dims[3], epsilon=epsilon) # CoaT series: Aggregate features of last three scales for classification.
if self.parallel_depth > 0: assert embed_dims[1] == embed_dims[2] == embed_dims[3]
self.aggregate = nn.Conv1D(
in_channels=3, out_channels=1, kernel_size=1)
self.head = nn.Linear(embed_dims[3], class_dim) else: # CoaT-Lite series: Use feature of last scale for classification.
self.head = nn.Linear(embed_dims[3], class_dim) # Initialize weights.
trunc_normal_(self.cls_token1)
trunc_normal_(self.cls_token2)
trunc_normal_(self.cls_token3)
trunc_normal_(self.cls_token4)
self.apply(self._init_weights) def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def insert_cls(self, x, cls_token):
""" Insert CLS token. """
cls_tokens = cls_token.expand((x.shape[0], -1, -1))
x = paddle.concat((cls_tokens, x), axis=1) return x def remove_cls(self, x):
""" Remove CLS token. """
return x[:, 1:, :] def forward_features(self, x0):
B = x0.shape[0] # Serial blocks 1.
x1, (H1, W1) = self.patch_embed1(x0)
x1 = self.insert_cls(x1, self.cls_token1) for blk in self.serial_blocks1:
x1 = blk(x1, size=(H1, W1))
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(
(B, H1, W1, -1)
).transpose((0, 3, 1, 2)) # Serial blocks 2.
x2, (H2, W2) = self.patch_embed2(x1_nocls)
x2 = self.insert_cls(x2, self.cls_token2) for blk in self.serial_blocks2:
x2 = blk(x2, size=(H2, W2))
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(
(B, H2, W2, -1)
).transpose((0, 3, 1, 2)) # Serial blocks 3.
x3, (H3, W3) = self.patch_embed3(x2_nocls)
x3 = self.insert_cls(x3, self.cls_token3) for blk in self.serial_blocks3:
x3 = blk(x3, size=(H3, W3))
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(
(B, H3, W3, -1)
).transpose((0, 3, 1, 2)) # Serial blocks 4.
x4, (H4, W4) = self.patch_embed4(x3_nocls)
x4 = self.insert_cls(x4, self.cls_token4) for blk in self.serial_blocks4:
x4 = blk(x4, size=(H4, W4))
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(
(B, H4, W4, -1)
).transpose((0, 3, 1, 2)) # Only serial blocks: Early return.
if self.parallel_depth == 0: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
if self.return_interm_layers:
feat_out = {} if 'x1_nocls' in self.out_features:
feat_out['x1_nocls'] = x1_nocls if 'x2_nocls' in self.out_features:
feat_out['x2_nocls'] = x2_nocls if 'x3_nocls' in self.out_features:
feat_out['x3_nocls'] = x3_nocls if 'x4_nocls' in self.out_features:
feat_out['x4_nocls'] = x4_nocls return feat_out else: # Return features for classification.
x4 = self.norm4(x4)
x4_cls = x4[:, 0] return x4_cls # Parallel blocks.
for blk in self.parallel_blocks:
x1, x2, x3, x4 = blk(x1, x2, x3, x4, sizes=[
(H1, W1), (H2, W2), (H3, W3), (H4, W4)]) # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
if self.return_interm_layers:
feat_out = {} if 'x1_nocls' in self.out_features:
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(
(B, H1, W1, -1)
).transpose((0, 3, 1, 2))
feat_out['x1_nocls'] = x1_nocls if 'x2_nocls' in self.out_features:
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(
(B, H2, W2, -1)
).transpose((0, 3, 1, 2))
feat_out['x2_nocls'] = x2_nocls if 'x3_nocls' in self.out_features:
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(
(B, H3, W3, -1)
).transpose((0, 3, 1, 2))
feat_out['x3_nocls'] = x3_nocls if 'x4_nocls' in self.out_features:
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(
(B, H4, W4, -1)
).transpose((0, 3, 1, 2))
feat_out['x4_nocls'] = x4_nocls return feat_out else:
x2 = self.norm2(x2)
x3 = self.norm3(x3)
x4 = self.norm4(x4)
x2_cls = x2[:, :1] # Shape: [B, 1, C].
x3_cls = x3[:, :1]
x4_cls = x4[:, :1] # Shape: [B, 3, C].
merged_cls = paddle.concat((x2_cls, x3_cls, x4_cls), axis=1) # Shape: [B, C].
merged_cls = self.aggregate(merged_cls).squeeze(axis=1) return merged_cls def forward(self, x):
# Return intermediate features (for down-stream tasks).
if self.return_interm_layers: return self.forward_features(x) else: # Return features for classification.
x = self.forward_features(x)
x = self.head(x) return x/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
def coat_ti(pretrained=False, **kwargs):
model = CoaT(
patch_size=4, embed_dims=[152, 152, 152, 152],
serial_depths=[2, 2, 2, 2], parallel_depth=6,
num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs
) if pretrained:
params = paddle.load('data/data86865/coat_tiny.pdparams')
model.set_dict(params) return modeldef coat_m(pretrained=False, **kwargs):
model = CoaT(
patch_size=4, embed_dims=[152, 216, 216, 216],
serial_depths=[2, 2, 2, 2], parallel_depth=6,
num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs
) if pretrained:
params = paddle.load('data/data86865/coat_mini.pdparams')
model.set_dict(params) return modeldef coat_lite_ti(pretrained=False, **kwargs):
model = CoaT(
patch_size=4, embed_dims=[64, 128, 256, 320],
serial_depths=[2, 2, 2, 2], parallel_depth=0,
num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs
) if pretrained:
params = paddle.load('data/data86865/coat_lite_tiny.pdparams')
model.set_dict(params) return modeldef coat_lite_m(pretrained=False, **kwargs):
model = CoaT(
patch_size=4, embed_dims=[64, 128, 320, 512],
serial_depths=[2, 2, 2, 2], parallel_depth=0,
num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs
) if pretrained:
params = paddle.load('data/data86865/coat_lite_mini.pdparams')
model.set_dict(params) return modeldef coat_lite_s(pretrained=False, **kwargs):
model = CoaT(
patch_size=4, embed_dims=[64, 128, 320, 512],
serial_depths=[3, 4, 6, 3], parallel_depth=0,
num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs
) if pretrained:
params = paddle.load('data/data86865/coat_lite_small.pdparams')
model.set_dict(params) return modelmodel = coat_ti(True) random_input = paddle.randn((1, 3, 224, 224)) out = model(random_input)print(out.shape) model.eval() out = model(random_input)print(out.shape)
[1, 1000] [1, 1000]
!mkdir ~/data/ILSVRC2012 !tar -xf ~/data/data68594/ILSVRC2012_img_val.tar -C ~/data/ILSVRC2012
import osimport cv2import numpy as npimport paddleimport paddle.vision.transforms as Tfrom PIL import Image# 构建数据集class ILSVRC2012(paddle.io.Dataset):
def __init__(self, root, label_list, transform, backend='pil'):
self.transform = transform
self.root = root
self.label_list = label_list
self.backend = backend
self.load_datas() def load_datas(self):
self.imgs = []
self.labels = [] with open(self.label_list, 'r') as f: for line in f:
img, label = line[:-1].split(' ')
self.imgs.append(os.path.join(self.root, img))
self.labels.append(int(label)) def __getitem__(self, idx):
label = self.labels[idx]
image = self.imgs[idx] if self.backend=='cv2':
image = cv2.imread(image) else:
image = Image.open(image).convert('RGB')
image = self.transform(image) return image.astype('float32'), np.array(label).astype('int64') def __len__(self):
return len(self.imgs)
val_transforms = T.Compose([
T.Resize(248, interpolation='bicubic'),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])# 配置模型model = coat_lite_s(pretrained=True)
model = paddle.Model(model)
model.prepare(metrics=paddle.metric.Accuracy(topk=(1, 5)))# 配置数据集val_dataset = ILSVRC2012('data/ILSVRC2012', transform=val_transforms, label_list='data/data68594/val_list.txt', backend='pil')# 模型验证acc = model.evaluate(val_dataset, batch_size=256, num_workers=0, verbose=1)print(acc){'acc_top1': 0.81832, 'acc_top5': 0.95582}以上就是Paddle2.0:浅析并实现 CoaT 模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 1001
1001























