本文复现了ConViT模型,其通过GPSA模块将CNN的归纳偏置引入ViT。代码用Paddle实现,包含网络结构搭建、模型定义等。在Cifar10数据集验证,因结合卷积优点,少样本下性能优于DeiT。还提供预训练权重,ImageNet验证集上不同架构有对应精度。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


In this paper, we take a new step towards bridging the gap between CNNs and Transformers, by presenting a new method to “softly" introduce a convolutional inductive bias into the ViT
paper:https://arxiv.org/abs/2103.10697
code:https://github.com/facebookresearch/convit
Hi guy,我们又见面了,这次来复现ConViT,官方性能如下
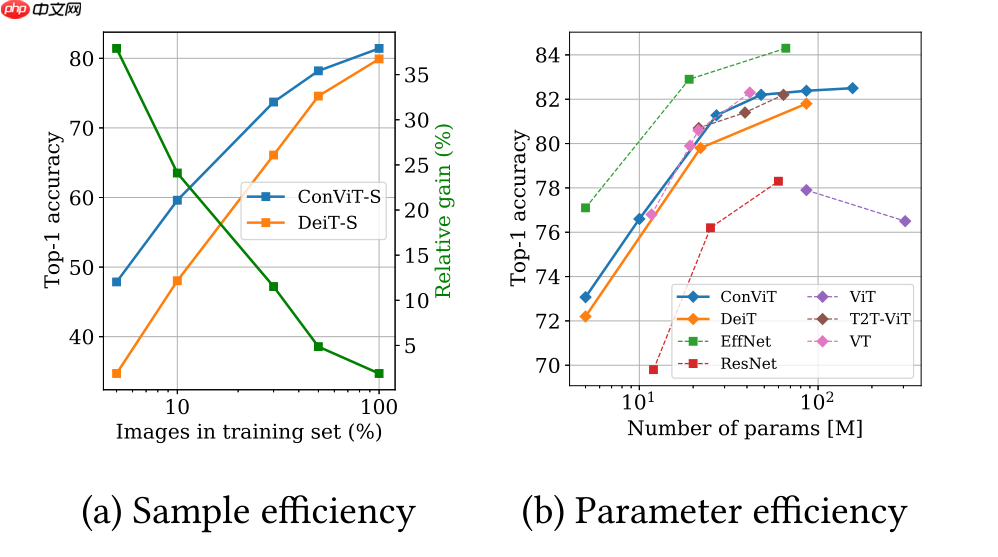
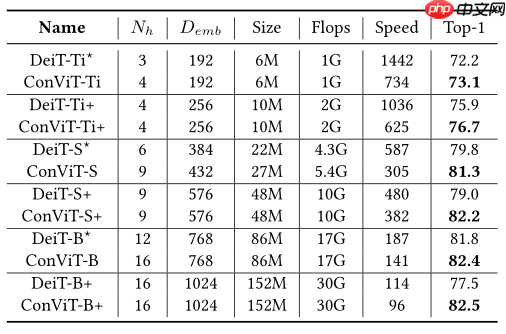
卷积神经网络具有归纳偏置,使得训练可以节约样本,但是缺点是模型天花板低,当数据集小时候,CNN展现比ViT更好的性能,当数据集充足时候,ViT展现比CNN更好的性能,基于此本文提出GPSA模块,将CNN具有的归纳偏置带入ViT,在ImageNet上取得了比DeiT更好的性能
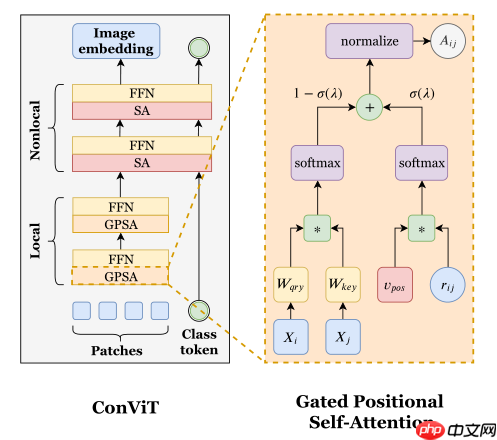
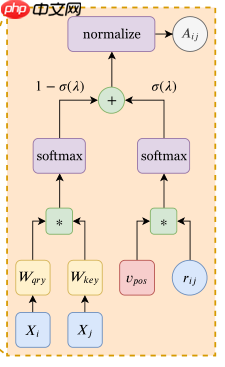
网络结构图如下
import paddleimport paddle.nn as nnimport paddle.nn.functional as Ffrom functools import partialimport numpy as np
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
zeros_ = nn.initializer.Constant(value=0.)
ones_ = nn.initializer.Constant(value=1.)
trunc_normal_ = nn.initializer.TruncatedNormal(std=.02)def to_2tuple(x):
return tuple([x] * 2)def drop_path(x, drop_prob = 0., training = False):
if drop_prob == 0. or not training: return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = paddle.to_tensor(keep_prob) + paddle.rand(shape)
random_tensor = paddle.floor(random_tensor)
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class Identity(nn.Layer):
def __init__(self, *args, **kwargs):
super(Identity, self).__init__()
def forward(self, input):
return inputclass Mlp(nn.Layer):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass PatchEmbed(nn.Layer):
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None, flatten=True):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2D(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else Identity() def forward(self, x):
B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], \ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x) if self.flatten:
x = x.flatten(2).transpose((0, 2, 1)) # BCHW -> BNC
x = self.norm(x) return xclass HybridEmbed(nn.Layer):
def __init__(self, backbone, img_size=224, patch_size=1, feature_size=None, in_chans=3, embed_dim=768):
super().__init__() assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.backbone = backbone if feature_size is None: with paddle.no_grad():
training = backbone.training if training:
backbone.eval()
o = self.backbone(paddle.zeros([1, in_chans, img_size[0], img_size[1]])) if isinstance(o, (list, tuple)):
o = o[-1]
feature_dim = o.shape[1]
backbone.train(training) else:
feature_size = to_2tuple(feature_size) if hasattr(self.backbone, 'feature_info'):
feature_dim = self.backbone.feature_info.channels()[-1] else:
feature_dim = self.backbone.num_features assert feature_size[0] % patch_size[0] == 0 and feature_size[1] % patch_size[1] == 0
self.num_patches = feature_size[0] // patch_size[0] * feature_size[1] // patch_size[1]
self.proj = nn.Conv2D(feature_dim, embed_dim, kernel_size=patch_size, stride=patch_size) def forward(self, x):
x = self.backbone(x) if isinstance(x, (list, tuple)):
x = x[-1]
x = self.proj(x).flatten(2).transpose([0, 2, 1]) return xdef repeat(x, rep):
return paddle.to_tensor(np.tile(x.numpy(), rep))def repeat_interleave(x, rep, axis):
return paddle.to_tensor(np.repeat(x.numpy(), rep, axis=axis))def einsum(str, distances, attn_map):
d = distances.numpy()
a = attn_map.numpy()
out = np.einsum(str, (d, a))
return paddle.to_tensor(out)class GPSA(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,
locality_strength=1., use_local_init=True):
super().__init__()
self.num_heads = num_heads
self.dim = dim
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.v = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.pos_proj = nn.Linear(3, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
self.locality_strength = locality_strength
self.gating_param = self.create_parameter(shape=[self.num_heads], default_initializer=ones_)
self.add_parameter("gating_param", self.gating_param)
def forward(self, x):
B, N, C = x.shape if not hasattr(self, 'rel_indices') or self.rel_indices.shape[1]!=N:
self.get_rel_indices(N)
attn = self.get_attention(x)
v = self.v(x).reshape([B, N, self.num_heads, C // self.num_heads]).transpose([0, 2, 1, 3])
x = (attn @ v).transpose([0, 2, 1, 3])
x = x.reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x) return x def get_attention(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape([B, N, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
q, k = qk[0], qk[1]
pos_score = self.rel_indices.expand([B, -1, -1,-1])
pos_score = self.pos_proj(pos_score).transpose([0,3,1,2])
patch_score = (q @ k.transpose([0, 1, 3, 2])) * self.scale
patch_score = F.softmax(patch_score, axis=-1)
pos_score = F.softmax(pos_score, axis=-1)
gating = self.gating_param.reshape([1, -1, 1, 1])
attn = (1. - F.sigmoid(gating)) * patch_score + F.sigmoid(gating) * pos_score
attn /= attn.sum(axis=-1).unsqueeze(-1)
attn = self.attn_drop(attn) return attn def get_attention_map(self, x, return_map = False):
attn_map = self.get_attention(x).mean(0)
distances = self.rel_indices.squeeze()[:,:,-1]**.5
dist = einsum('nm,hnm->h', distances, attn_map) # einsum
dist /= distances.shape[0] if return_map: return dist, attn_map else: return dist def get_rel_indices(self, num_patches):
img_size = int(num_patches**.5)
rel_indices = paddle.zeros([1, num_patches, num_patches, 3])
ind = paddle.arange(img_size).reshape([1,-1]) - paddle.arange(img_size).reshape([-1, 1])
indx = repeat(ind, [img_size, img_size])
indy = repeat_interleave(ind, img_size, axis=0)
indy = repeat_interleave(indy, img_size, axis=1)
indd = indx**2 + indy**2
rel_indices[:,:,:,2] = indd.unsqueeze(0)
rel_indices[:,:,:,1] = indy.unsqueeze(0)
rel_indices[:,:,:,0] = indx.unsqueeze(0)
self.rel_indices = rel_indices def local_init(self):
self.v.weight.set_value(paddle.eye(self.dim))
locality_distance = 1 # max(1,1/locality_strength**.5)
kernel_size = int(self.num_heads ** .5)
center = (kernel_size - 1) / 2 if kernel_size % 2 == 0 else kernel_size // 2
for h1 in range(kernel_size): for h2 in range(kernel_size):
position = h1 + kernel_size * h2
self.pos_proj.weight[2, position] = -1
self.pos_proj.weight[1, position] = 2 * (h1 - center) * locality_distance
self.pos_proj.weight[0, position] = 2 * (h2 - center) * locality_distance
self.pos_proj.weight.set_value(self.pos_proj.weight * self.locality_strength)class MHSA(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop) def get_attention_map(self, x, return_map = False):
B, N, C = x.shape
qkv = self.qkv(x).reshape([B, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
q, k, v = qkv[0], qkv[1], qkv[2]
attn_map = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn_map = F.softmax(attn_map, axis=-1).mean(0)
img_size = int(N**.5)
ind = paddle.arange(img_size).reshape([1,-1]) - paddle.arange(img_size).reshape([-1, 1])
indx = repeat(ind, [img_size, img_size])
indy = repeat_interleave(ind, img_size, axis=0)
indy = repeat_interleave(indy, img_size, axis=1)
indd = indx**2 + indy**2
distances = indd**.5
dist = einsum('nm,hnm->h', distances, attn_map) # einsum
dist /= N
if return_map: return dist, attn_map else: return dist
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape([B, N, 3, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0,2,1,3]).reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x) return x
class Block(nn.Layer):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, use_gpsa=True, **kwargs):
super().__init__()
self.norm1 = norm_layer(dim)
self.use_gpsa = use_gpsa if self.use_gpsa:
self.attn = GPSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs) else:
self.attn = MHSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs)
self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x))) return x
class VisionTransformer(nn.Layer):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=48, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, global_pool=None,
local_up_to_layer=10, locality_strength=1., use_pos_embed=True):
super().__init__()
embed_dim *= num_heads
self.num_classes = num_classes
self.local_up_to_layer = local_up_to_layer
self.num_features = self.embed_dim = embed_dim
self.use_pos_embed = use_pos_embed if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim) else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.num_patches = num_patches
self.cls_token = self.create_parameter(shape=[1, 1, embed_dim], default_initializer=nn.initializer.TruncatedNormal(mean=0.0, std=.02))
self.add_parameter("cls_token", self.cls_token)
self.pos_drop = nn.Dropout(p=drop_rate) if self.use_pos_embed:
self.pos_embed = self.create_parameter(shape=[1, num_patches, embed_dim], default_initializer=nn.initializer.TruncatedNormal(mean=0.0, std=.02))
self.add_parameter("pos_embed", self.pos_embed)
dpr = [x for x in paddle.linspace(0, drop_path_rate, depth)]
self.blocks = nn.LayerList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
use_gpsa=True,
locality_strength=locality_strength) if i<local_up_to_layer else
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
use_gpsa=False) for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else Identity()
self.apply(self._init_weights) for n, m in self.named_sublayers(): if hasattr(m, 'local_init'):
m.local_init() def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight) if isinstance(m, nn.Linear) and m.bias is not None:
zeros_(m.bias) elif isinstance(m, nn.LayerNorm):
zeros_(m.bias)
ones_(m.weight) def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand([B, -1, -1]) if self.use_pos_embed:
x = x + self.pos_embed
x = self.pos_drop(x) for u,blk in enumerate(self.blocks): if u == self.local_up_to_layer :
x = paddle.concat((cls_tokens, x), axis=1)
x = blk(x)
x = self.norm(x) return x[:, 0] def forward(self, x):
x = self.forward_features(x)
x = self.head(x) return xdef convit_tiny(**kwargs):
model = VisionTransformer(
num_heads=4,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef convit_small(**kwargs):
model = VisionTransformer(
num_heads=9,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modeldef convit_base(**kwargs):
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, epsilon=1e-6), **kwargs) return modelpaddle.Model(convit_base()).summary((1, 3, 224, 224))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 768, 14, 14] 590,592
Identity-1 [[1, 196, 768]] [1, 196, 768] 0
PatchEmbed-1 [[1, 3, 224, 224]] [1, 196, 768] 0
Dropout-1 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-1 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-1 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-4 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-2 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-2 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-3 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-3 [[1, 196, 768]] [1, 196, 768] 0
GPSA-1 [[1, 196, 768]] [1, 196, 768] 16
Identity-2 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-2 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-5 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-1 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-4 [[1, 196, 768]] [1, 196, 768] 0
Linear-6 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-1 [[1, 196, 768]] [1, 196, 768] 0
Block-1 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-3 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-7 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-10 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-5 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-8 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-9 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-6 [[1, 196, 768]] [1, 196, 768] 0
GPSA-2 [[1, 196, 768]] [1, 196, 768] 16
Identity-3 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-4 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-11 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-2 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-7 [[1, 196, 768]] [1, 196, 768] 0
Linear-12 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-2 [[1, 196, 768]] [1, 196, 768] 0
Block-2 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-5 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-13 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-16 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-8 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-14 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-15 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-9 [[1, 196, 768]] [1, 196, 768] 0
GPSA-3 [[1, 196, 768]] [1, 196, 768] 16
Identity-4 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-6 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-17 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-3 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-10 [[1, 196, 768]] [1, 196, 768] 0
Linear-18 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-3 [[1, 196, 768]] [1, 196, 768] 0
Block-3 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-7 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-19 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-22 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-11 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-20 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-21 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-12 [[1, 196, 768]] [1, 196, 768] 0
GPSA-4 [[1, 196, 768]] [1, 196, 768] 16
Identity-5 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-8 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-23 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-4 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-13 [[1, 196, 768]] [1, 196, 768] 0
Linear-24 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-4 [[1, 196, 768]] [1, 196, 768] 0
Block-4 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-9 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-25 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-28 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-14 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-26 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-27 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-15 [[1, 196, 768]] [1, 196, 768] 0
GPSA-5 [[1, 196, 768]] [1, 196, 768] 16
Identity-6 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-10 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-29 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-5 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-16 [[1, 196, 768]] [1, 196, 768] 0
Linear-30 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-5 [[1, 196, 768]] [1, 196, 768] 0
Block-5 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-11 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-31 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-34 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-17 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-32 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-33 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-18 [[1, 196, 768]] [1, 196, 768] 0
GPSA-6 [[1, 196, 768]] [1, 196, 768] 16
Identity-7 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-12 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-35 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-6 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-19 [[1, 196, 768]] [1, 196, 768] 0
Linear-36 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-6 [[1, 196, 768]] [1, 196, 768] 0
Block-6 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-13 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-37 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-40 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-20 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-38 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-39 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-21 [[1, 196, 768]] [1, 196, 768] 0
GPSA-7 [[1, 196, 768]] [1, 196, 768] 16
Identity-8 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-14 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-41 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-7 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-22 [[1, 196, 768]] [1, 196, 768] 0
Linear-42 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-7 [[1, 196, 768]] [1, 196, 768] 0
Block-7 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-15 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-43 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-46 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-23 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-44 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-45 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-24 [[1, 196, 768]] [1, 196, 768] 0
GPSA-8 [[1, 196, 768]] [1, 196, 768] 16
Identity-9 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-16 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-47 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-8 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-25 [[1, 196, 768]] [1, 196, 768] 0
Linear-48 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-8 [[1, 196, 768]] [1, 196, 768] 0
Block-8 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-17 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-49 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-52 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-26 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-50 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-51 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-27 [[1, 196, 768]] [1, 196, 768] 0
GPSA-9 [[1, 196, 768]] [1, 196, 768] 16
Identity-10 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-18 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-53 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-9 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-28 [[1, 196, 768]] [1, 196, 768] 0
Linear-54 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-9 [[1, 196, 768]] [1, 196, 768] 0
Block-9 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-19 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-55 [[1, 196, 768]] [1, 196, 1536] 1,179,648
Linear-58 [[1, 196, 196, 3]] [1, 196, 196, 16] 64
Dropout-29 [[1, 16, 196, 196]] [1, 16, 196, 196] 0
Linear-56 [[1, 196, 768]] [1, 196, 768] 589,824
Linear-57 [[1, 196, 768]] [1, 196, 768] 590,592
Dropout-30 [[1, 196, 768]] [1, 196, 768] 0
GPSA-10 [[1, 196, 768]] [1, 196, 768] 16
Identity-11 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-20 [[1, 196, 768]] [1, 196, 768] 1,536
Linear-59 [[1, 196, 768]] [1, 196, 3072] 2,362,368
GELU-10 [[1, 196, 3072]] [1, 196, 3072] 0
Dropout-31 [[1, 196, 768]] [1, 196, 768] 0
Linear-60 [[1, 196, 3072]] [1, 196, 768] 2,360,064
Mlp-10 [[1, 196, 768]] [1, 196, 768] 0
Block-10 [[1, 196, 768]] [1, 196, 768] 0
LayerNorm-21 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-61 [[1, 197, 768]] [1, 197, 2304] 1,769,472
Dropout-32 [[1, 16, 197, 197]] [1, 16, 197, 197] 0
Linear-62 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-33 [[1, 197, 768]] [1, 197, 768] 0
MHSA-1 [[1, 197, 768]] [1, 197, 768] 0
Identity-12 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-22 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-63 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-11 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-34 [[1, 197, 768]] [1, 197, 768] 0
Linear-64 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-11 [[1, 197, 768]] [1, 197, 768] 0
Block-11 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-23 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-65 [[1, 197, 768]] [1, 197, 2304] 1,769,472
Dropout-35 [[1, 16, 197, 197]] [1, 16, 197, 197] 0
Linear-66 [[1, 197, 768]] [1, 197, 768] 590,592
Dropout-36 [[1, 197, 768]] [1, 197, 768] 0
MHSA-2 [[1, 197, 768]] [1, 197, 768] 0
Identity-13 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-24 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-67 [[1, 197, 768]] [1, 197, 3072] 2,362,368
GELU-12 [[1, 197, 3072]] [1, 197, 3072] 0
Dropout-37 [[1, 197, 768]] [1, 197, 768] 0
Linear-68 [[1, 197, 3072]] [1, 197, 768] 2,360,064
Mlp-12 [[1, 197, 768]] [1, 197, 768] 0
Block-12 [[1, 197, 768]] [1, 197, 768] 0
LayerNorm-25 [[1, 197, 768]] [1, 197, 768] 1,536
Linear-69 [[1, 768]] [1, 1000] 769,000
===========================================================================
Total params: 86,388,744
Trainable params: 86,388,744
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 398.67
Params size (MB): 329.55
Estimated Total Size (MB): 728.79
---------------------------------------------------------------------------{'total_params': 86388744, 'trainable_params': 86388744}采用Cifar10数据集,无过多的数据增强
import paddle.vision.transforms as Tfrom paddle.vision.datasets import Cifar10
paddle.set_device('gpu')#数据准备transform = T.Compose([
T.Resize(size=(224,224)),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225],data_format='HWC'),
T.ToTensor()
])
train_dataset = Cifar10(mode='train', transform=transform)
val_dataset = Cifar10(mode='test', transform=transform)Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz Begin to download Download finished
model=paddle.Model(convit_small(num_classes=10))
由于时间篇幅只训练6轮,感兴趣的同学可以继续训练
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
visualdl=paddle.callbacks.VisualDL(log_dir='visual_log') # 开启训练可视化model.fit(
train_data=train_dataset,
eval_data=val_dataset,
batch_size=64,
epochs=6,
verbose=1,
callbacks=[visualdl]
)
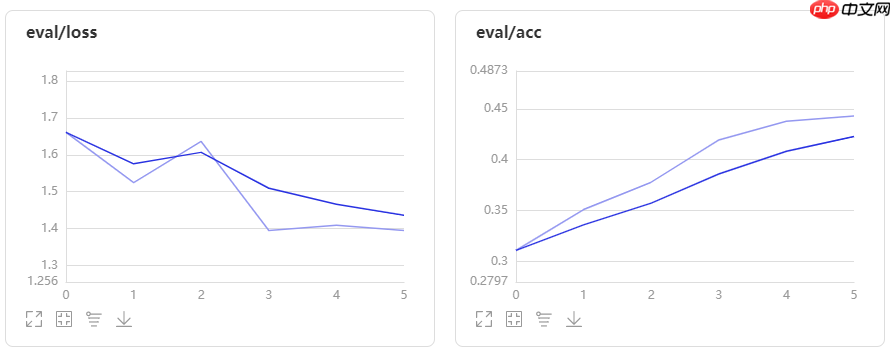
本项目给出了模型预训练权重,在 ImageNet 验证集效果如下
| Architecture | Top-1 Acc | Top-2 Acc |
|---|---|---|
| convit_tiny | 72.95 % | 91.68 % |
| convit_small | 81.34 % | 95.78 % |
| convit_base | 82.27 % | 95.92 % |
# convit tiny model = convit_tiny()
model.set_state_dict(paddle.load('data/data93780/convit_tiny.pdparams'))# convit small model = convit_small()
model.set_state_dict(paddle.load('data/data93780/convit_small.pdparams'))# convit basemodel = convit_base()
model.set_state_dict(paddle.load('data/data93780/convit_base.pdparams'))实验表明,相比DeiT,因为增加了CNN归纳偏置优点,少样本下ConViT性能更好
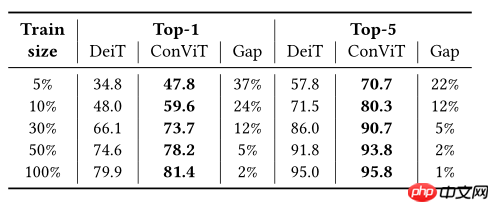
数据不充分情况下,具有归纳偏置的CNN性能比ViT好,数据充足时候,ViT性能要比CNN好
ConViT结合了卷积归纳偏置优点,但train from scratch问题依旧存在
以上就是ConViT:引入归纳偏置的ViT的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 428
428























