本项目围绕深度学习中重要的学习率超参数展开,旨在掌握Paddle2.0学习率API使用、分析不同学习率性能及尝试自定义学习率。使用蜜蜂黄蜂分类数据集,对Paddle2.0的13种自带学习率及自定义的CLR、Adjust_lr进行训练测试,结果显示自定义CLR效果最佳,LinearWarmup等也值得尝试。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

对于深度学习中的学习率是一个重要的超参数。在本项目中我们将从三个不同方面来理解学习率:
那么什么是学习率呢?
我们知道,深度学习的目标是找到可以满足我们任务的函数,而要找到这个函数就需要确定这个函数的参数。为了达到这个目的我们需要首先设计 一个损失函数,然后让我们的数据输入到待确定参数的备选函数中时这个损失函数可以有最小值。所以,我们就要不断的调整备选函数的参数值,这个调整的过程就是所谓的梯度下降。而参数值调整的幅度大小可以由学习率来控制。由此可见,学习率是深度学习中非常重要的一个概念。值得庆幸的是,深度学习框架Paddle提供了很多可以拿来就用的学习率函数。本项目就来研究一下这些Paddle中的学习率函数。对于想要自力更生设计学习率函数的同学,本项目也提供了如何进行自定义学习率函数供参考交流。
本项目使用的数据集是蜜蜂黄蜂分类数据集。包含4个类别:蜜蜂、黄蜂、其它昆虫和其它类别。 共7939张图片,其中蜜蜂3183张,黄蜂4943张,其它昆虫2439张,其它类别856张
!unzip -q data/data65386/beesAndwasps.zip -d work/dataset
import osimport randomfrom matplotlib import pyplot as pltfrom PIL import Image
imgs = []
paths = os.listdir('work/dataset')for path in paths:
img_path = os.path.join('work/dataset', path) if os.path.isdir(img_path):
img_paths = os.listdir(img_path)
img = Image.open(os.path.join(img_path, random.choice(img_paths)))
imgs.append((img, path))
f, ax = plt.subplots(2, 3, figsize=(12,12))for i, img in enumerate(imgs[:]):
ax[i//3, i%3].imshow(img[0])
ax[i//3, i%3].axis('off')
ax[i//3, i%3].set_title('label: %s' % img[1])
plt.show()
plt.show()<Figure size 864x864 with 6 Axes>
!python code/preprocess.py
finished data preprocessing
Paddle2.0 中定义了如下13种不同的学习率算法。本项目在比较不同的学习率算法性能时将采用相同的优化器算法Momentum。
| 序号 | 名称 | 功能 |
|---|---|---|
| 1 | CosineAnnealingDecay | 余弦退火 学习率 |
| 2 | ExponentialDecay | 指数衰减 学习率 |
| 3 | InverseTimeDecay | 逆时间衰减 学习率 |
| 4 | LambdaDecay | Lambda衰减 学习率 |
| 5 | LinearWarmup | 线性热身 学习率 |
| 6 | LRScheduler | 学习率基类 |
| 7 | MultiStepDecay | 多阶段衰减 学习率 |
| 8 | NaturalExpDecay | 自然指数衰减 学习率 |
| 9 | NoamDecay | Noam衰减 学习率 |
| 10 | PiecewiseDecay | 分段衰减 学习率 |
| 11 | PolynomialDecay | 多项式衰减 学习率 |
| 12 | ReduceOnPlateau | Loss自适应 学习率 |
| 13 | StepDecay | 阶段衰减 学习率 |
使用方法为:paddle.optimizer.lr.CosineAnnealingDecay(learning_rate, T_max, eta_min=0, last_epoch=- 1, verbose=False)
该算法来自于论文SGDR: Stochastic Gradient Descent with Warm Restarts。
这差不多是最有名的学习率算法了。
更新公式如下:
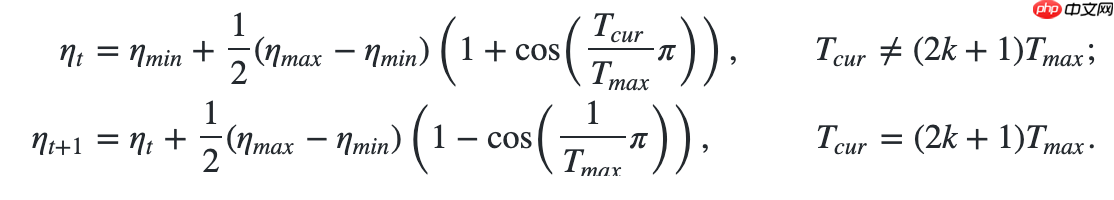
## 开始训练!python code/train.py --lr 'CosineAnnealingDecay'
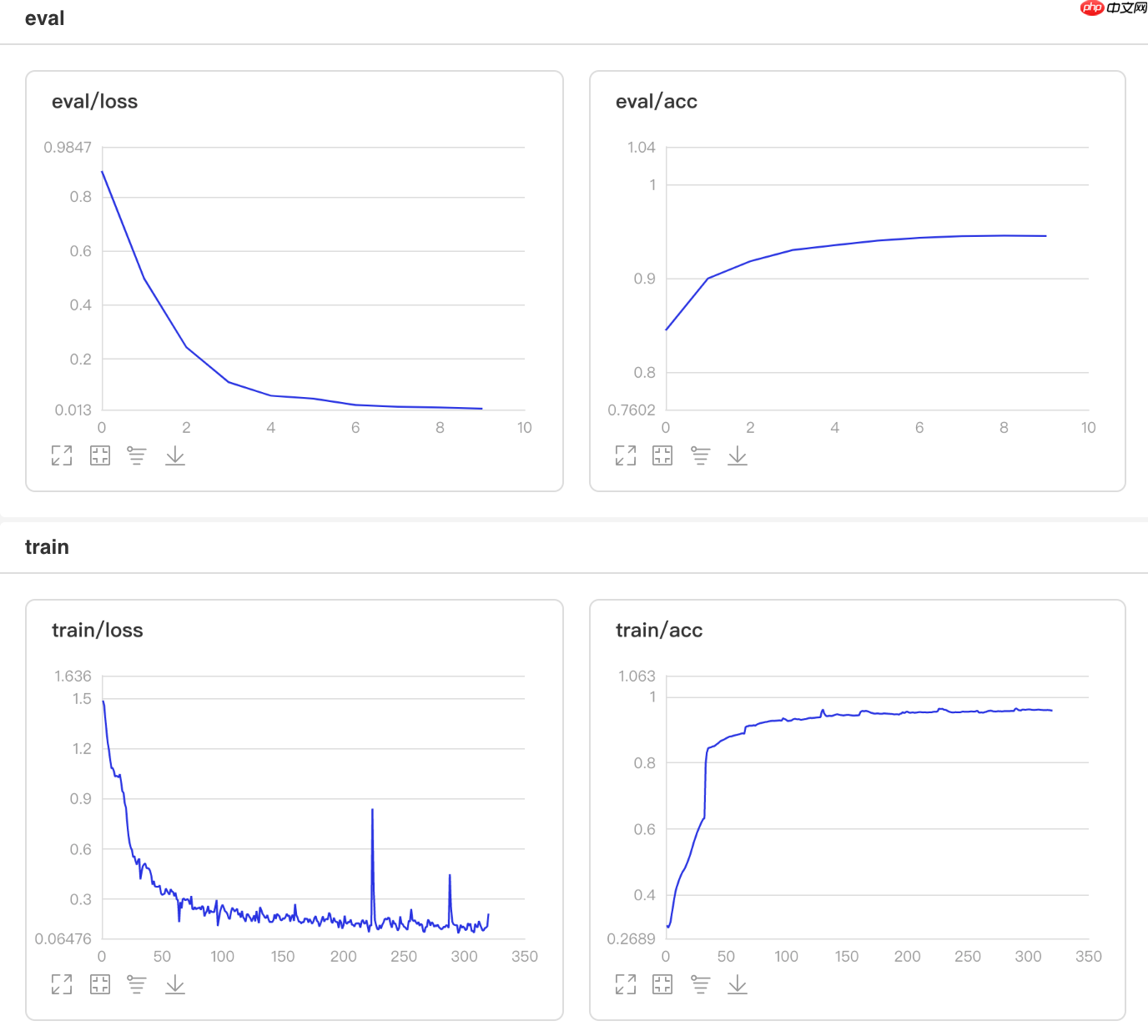
图1 CosineAnnealingDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'CosineAnnealingDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:14:08.330015 4460 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:14:08.335014 4460 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9472 - 734ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.ExponentialDecay(learning_rate, gamma, last_epoch=-1, verbose=False)
该接口提供一种学习率按指数函数衰减的策略。
更新公式如下:
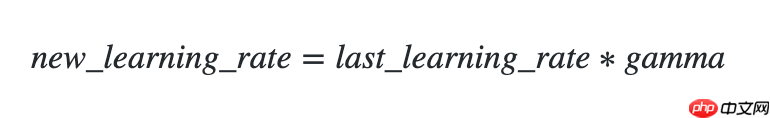
## 开始训练!python code/train.py --lr 'ExponentialDecay'
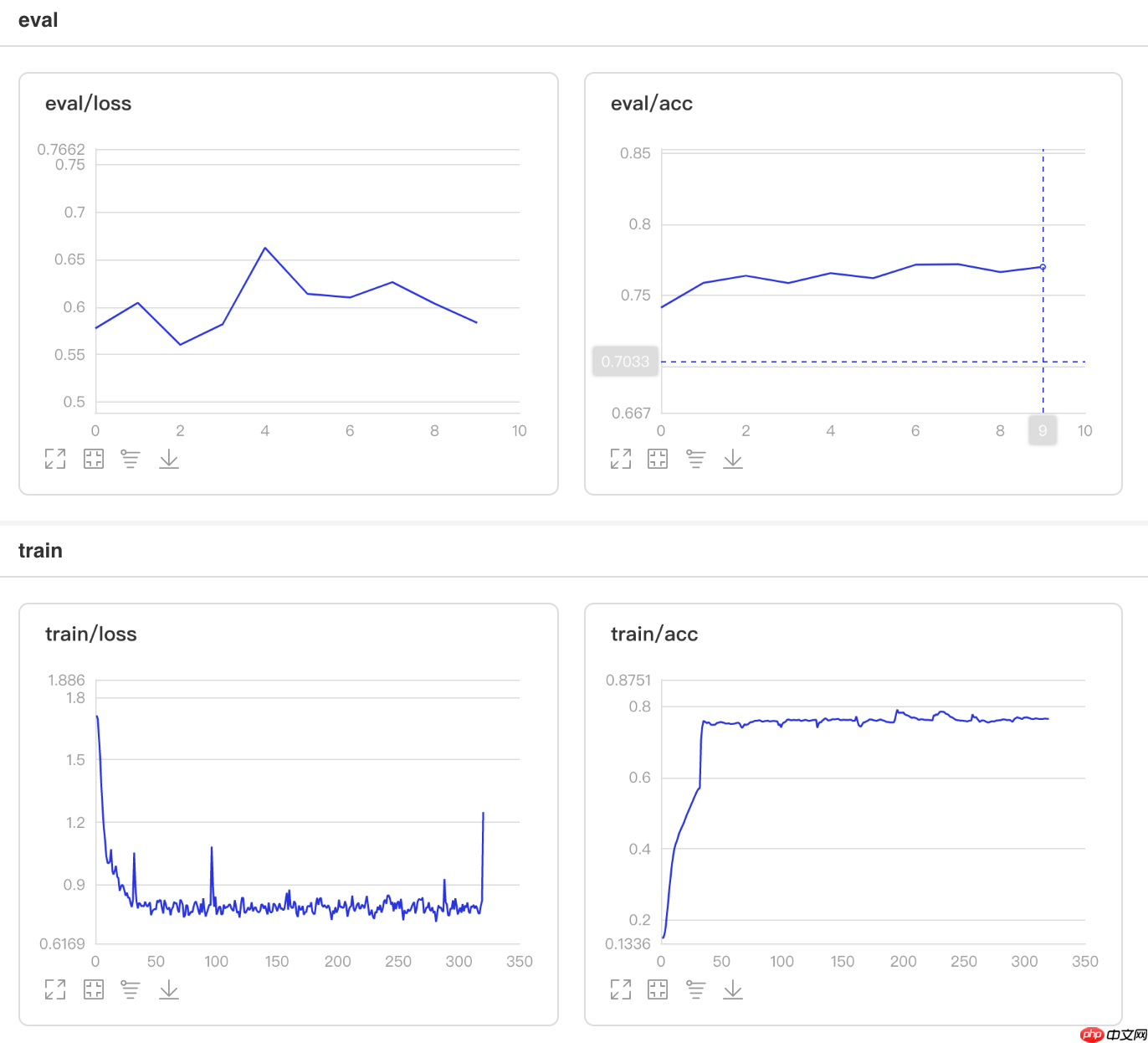
图2 ExponentialDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'ExponentialDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:11:58.334306 4184 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:11:58.339387 4184 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.7686 - 854ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.InverseTimeDecay(learning_rate, gamma, last_epoch=- 1, verbose=False)
该接口提供逆时间衰减学习率的策略,即学习率与当前衰减次数成反比。
更新公式如下:
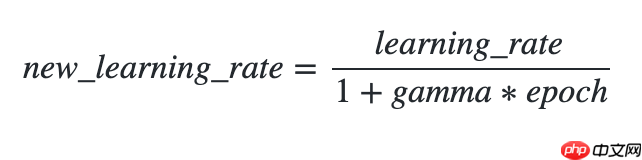
## 开始训练!python code/train.py --lr 'InverseTimeDecay'
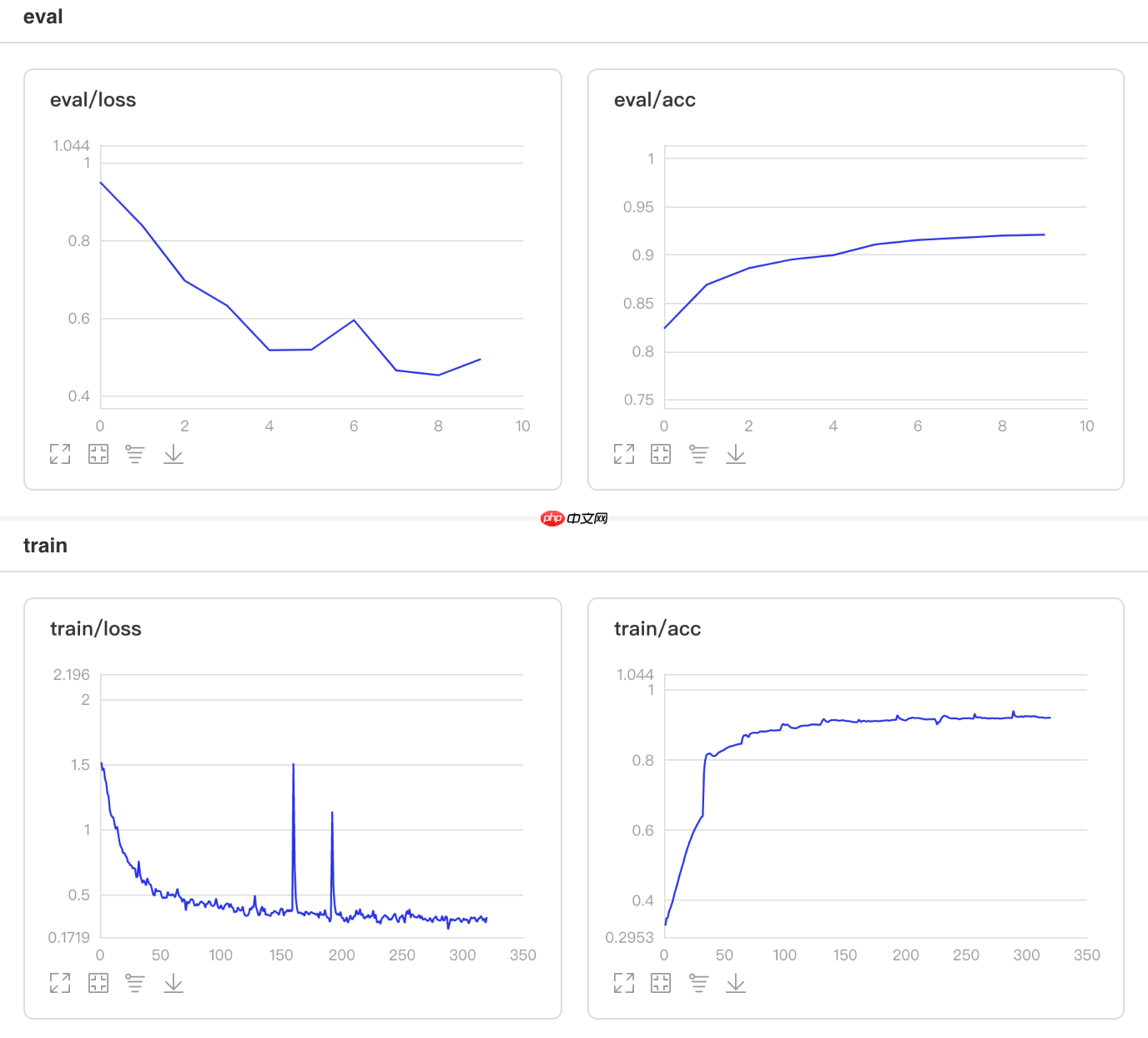
图3 InverseTimeDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'InverseTimeDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:07:21.973084 3618 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:07:21.977885 3618 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9183 - 729ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.LambdaDecay(learning_rate, lr_lambda, last_epoch=-1, verbose=False)
该接口提供lambda函数设置学习率的策略,lr_lambda 为一个lambda函数,其通过epoch计算出一个因子,该因子会乘以初始学习率。
更新公式如下:
lr_lambda = lambda epoch: 0.95 ** epoch
## 开始训练!python code/train.py --lr 'LambdaDecay'
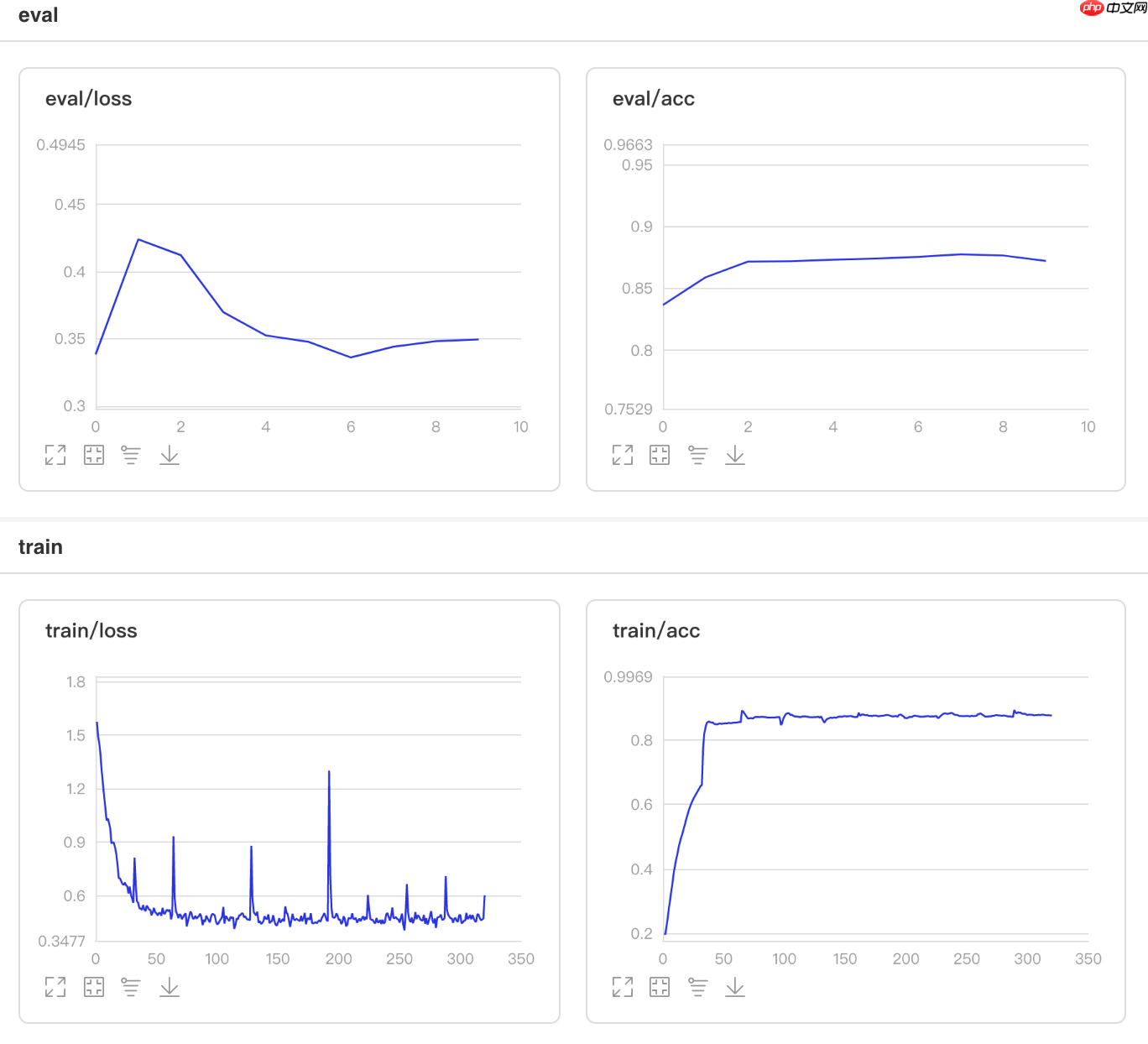
图4 LambdaDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'LambdaDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:04:35.426102 3249 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:04:35.431219 3249 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.8667 - 731ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.LinearWarmup(learing_rate, warmup_steps, start_lr, end_lr, last_epoch=-1, verbose=False)
该算法来自于论文SGDR: Stochastic Gradient Descent with Warm Restarts。
该接口提供一种学习率优化策略-线性学习率热身(warm up)对学习率进行初步调整。在正常调整学习率之前,先逐步增大学习率。
热身时,学习率更新公式如下:
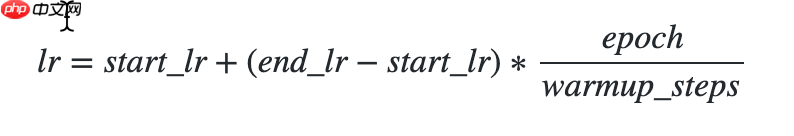
## 开始训练!python code/train.py --lr 'LinearWarmup'
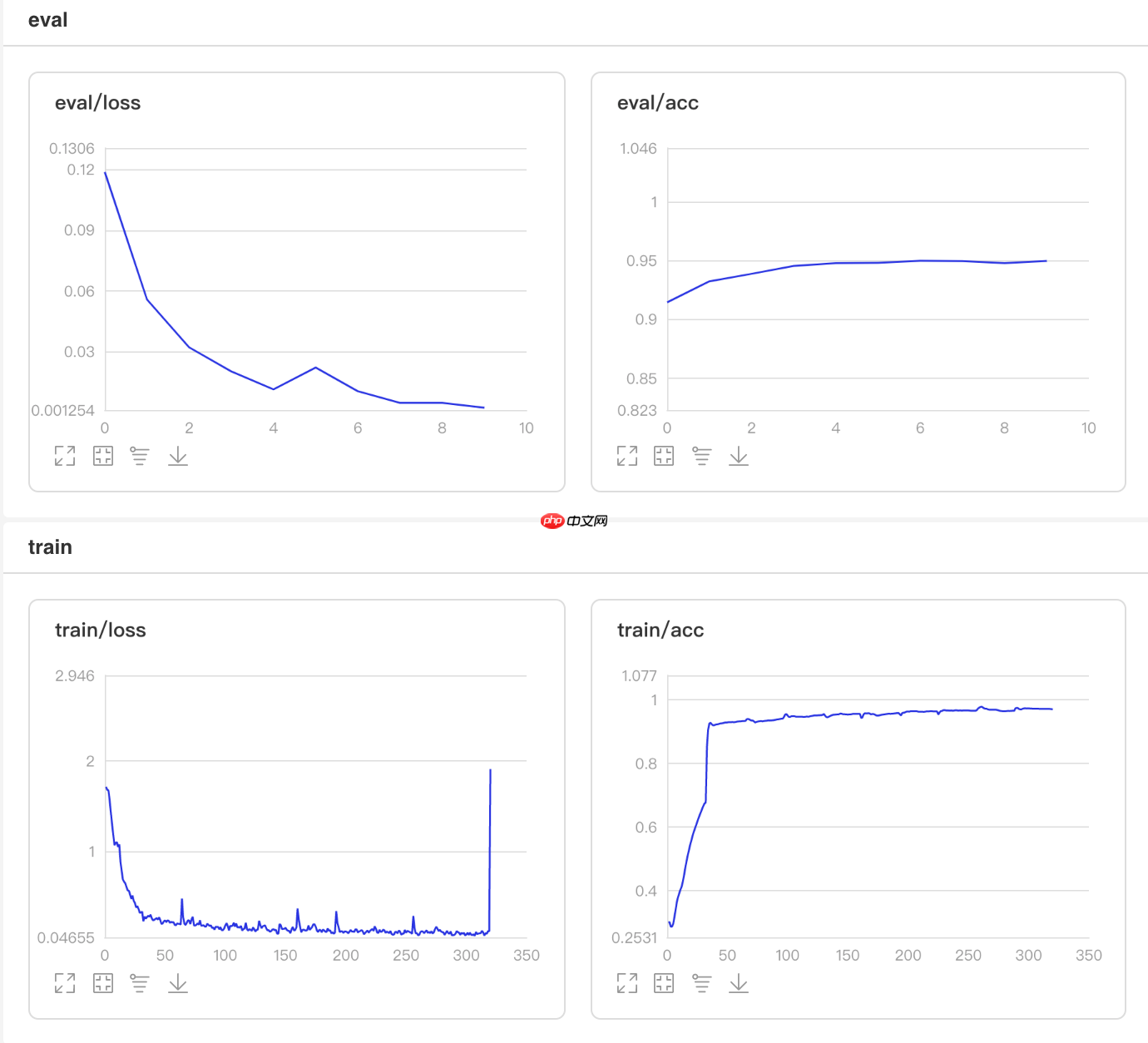
图5 LinearWarmup训练验证图
## 查看测试集上的效果!python code/test.py --lr 'LinearWarmup'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 22:02:36.454607 2972 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 22:02:36.459585 2972 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9563 - 760ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.MultiStepDecay(learning_rate, milestones, gamma=0.1, last_epoch=- 1, verbose=False)
该接口提供一种学习率按指定轮数进行衰减的策略。
学习率更新公式如下:

## 开始训练!python code/train.py --lr 'MultiStepDecay'
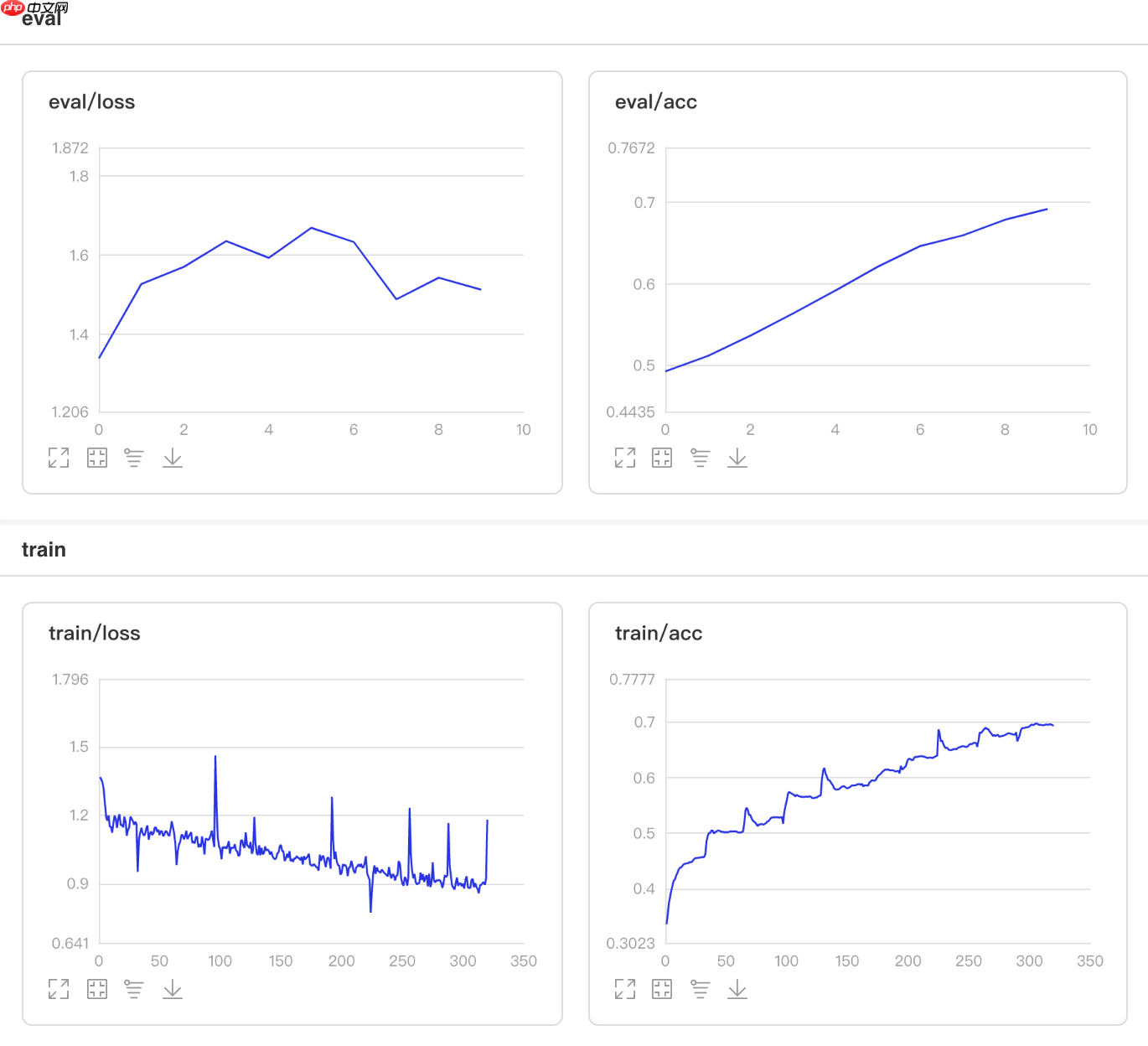
图6 MultiStepDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'MultiStepDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:59:52.387367 2630 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:59:52.392359 2630 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.6982 - 736ms/step Eval samples: 1763
## 开始训练!python code/train.py --lr 'NaturalExpDecay'
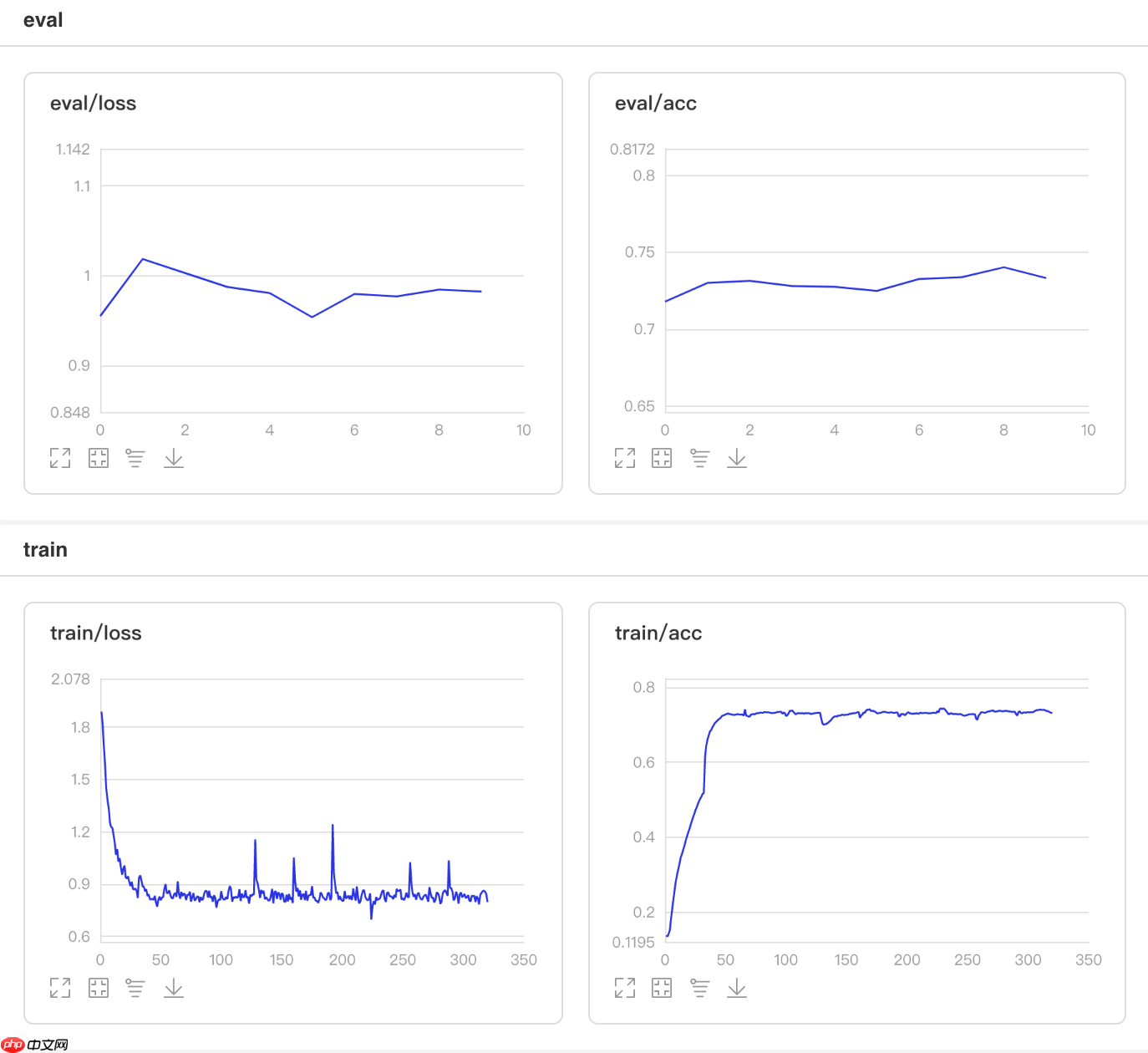
图7 NaturalExpDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'NaturalExpDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:57:41.858023 2325 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:57:41.863117 2325 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.7379 - 726ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.NoamDecay(d_model, warmup_steps, learning_rate=1.0, last_epoch=-1, verbose=False)
该接口提供Noam衰减学习率的策略。
学习率更新公式如下:
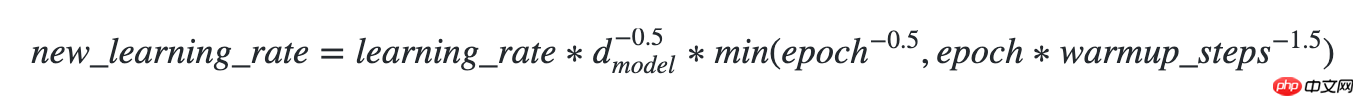
## 开始训练!python code/train.py --lr 'NoamDecay'
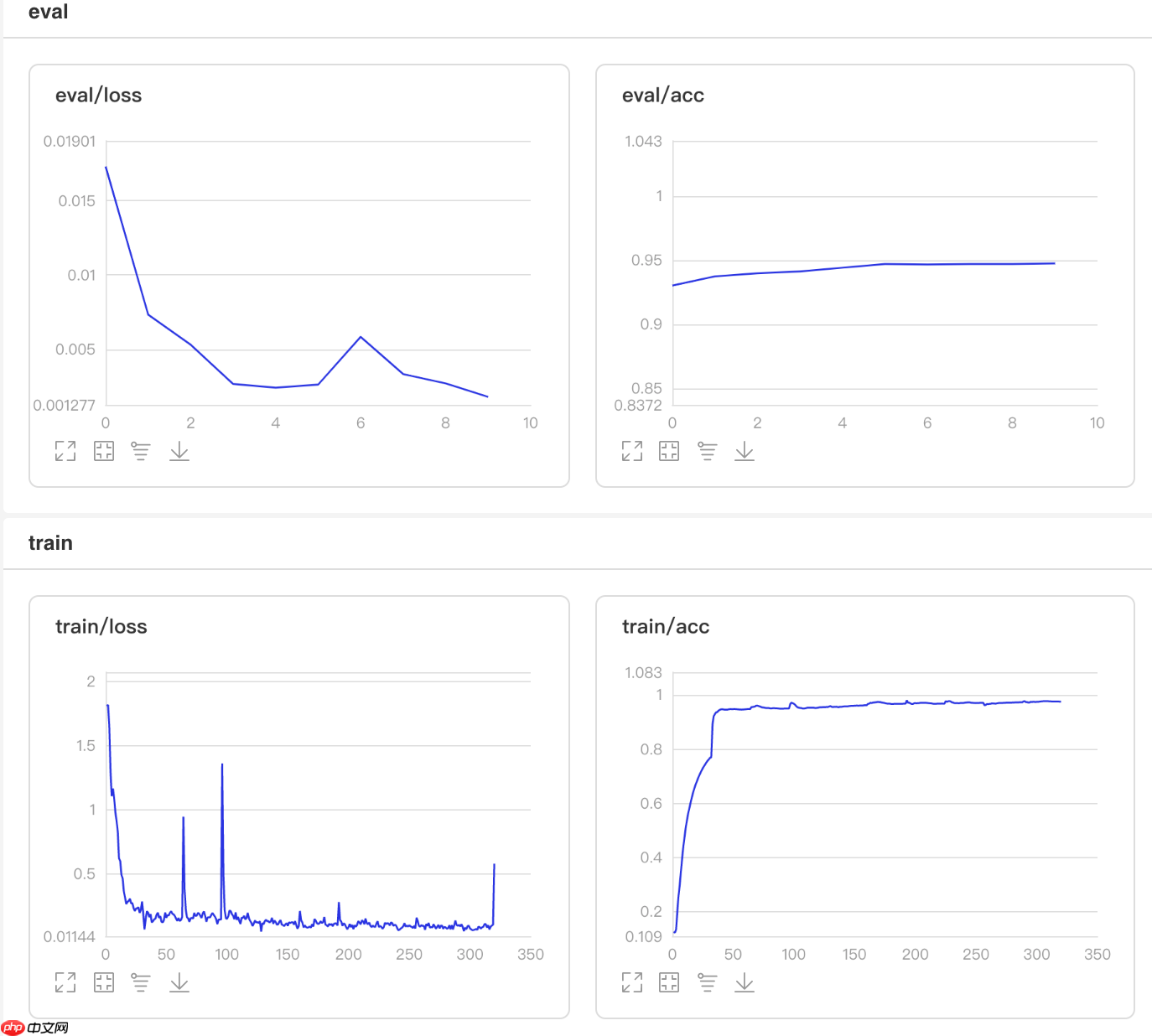
图8 NoamDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'NoamDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:55:24.339512 1995 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:55:24.344694 1995 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9490 - 749ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.PiecewiseDecay(boundaries, values, last_epoch=-1, verbose=False)
该接口提供分段设置学习率的策略。
## 开始训练!python code/train.py --lr 'PiecewiseDecay'
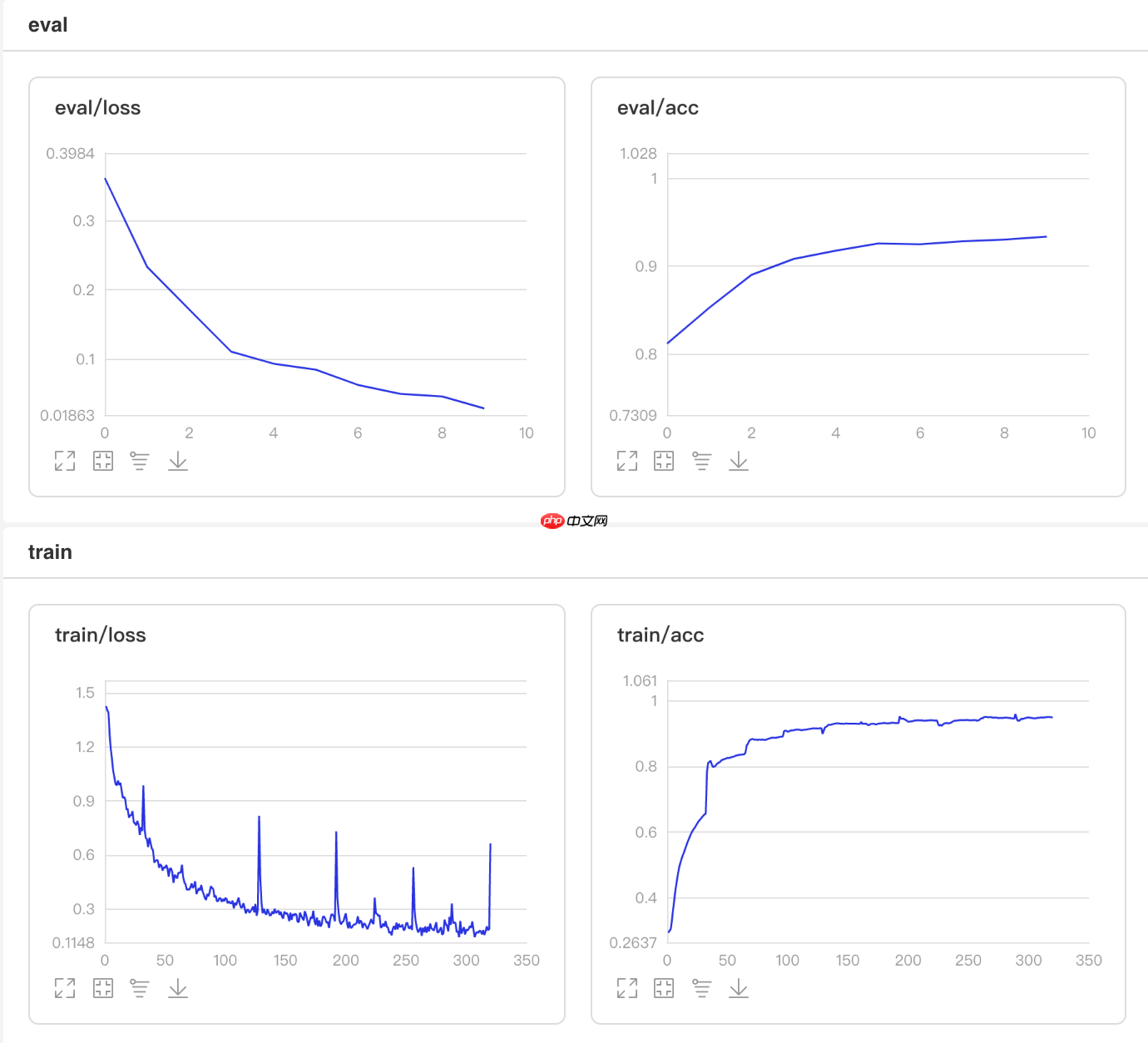
图9 PiecewiseDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'PiecewiseDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:52:38.228776 1695 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:52:38.233954 1695 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9416 - 749ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.PolynomialDecay(learning_rate, decay_steps, end_lr=0.0001, power=1.0, cycle=False, last_epoch=-1, verbose=False)
该接口提供学习率按多项式衰减的策略。通过多项式衰减函数,使得学习率值逐步从初始的learning_rate衰减到 end_lr。
## 开始训练!python code/train.py --lr 'PolynomialDecay'
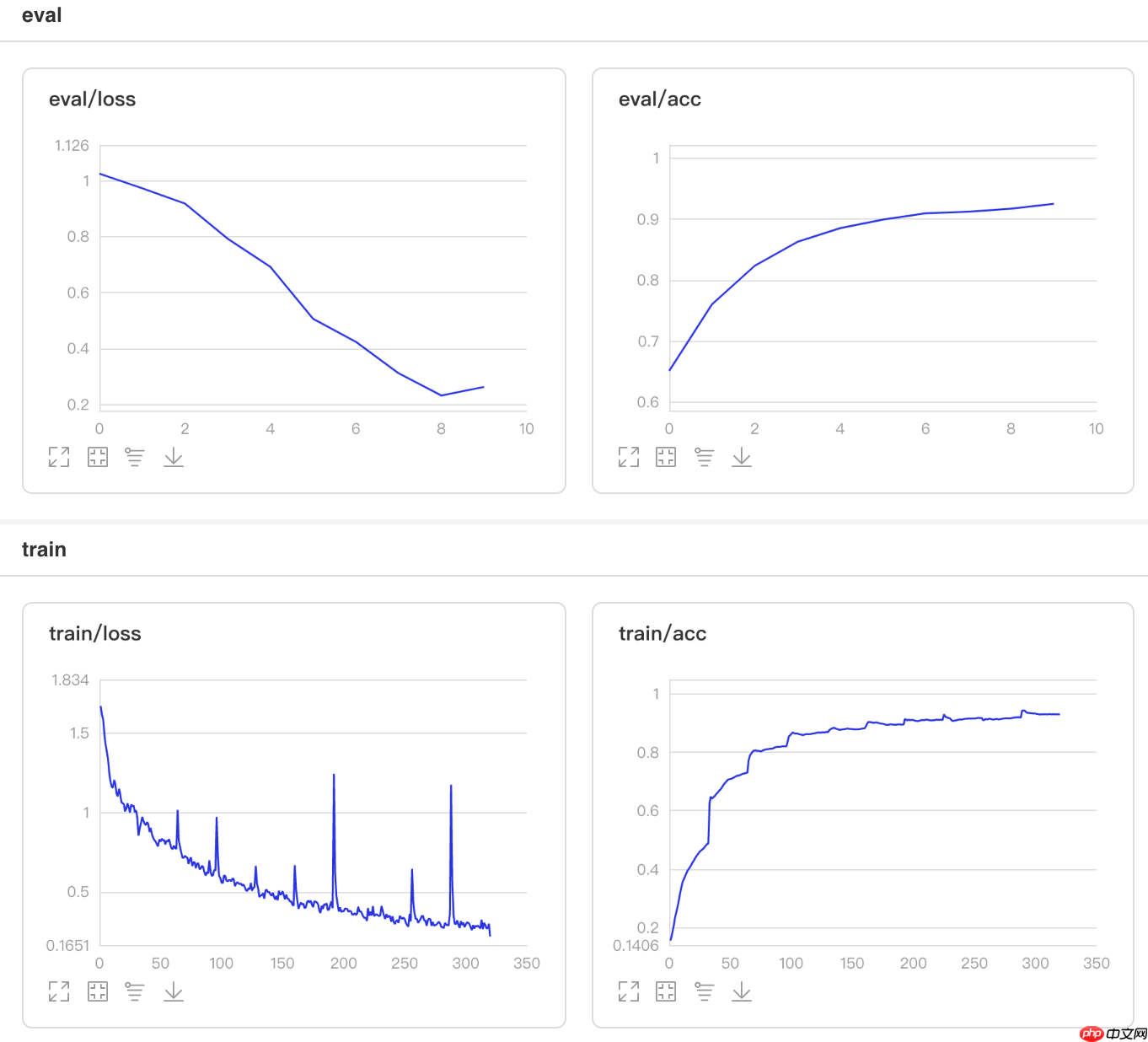
图10 PolynomialDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'PolynomialDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:50:10.634958 1327 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:50:10.639853 1327 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9325 - 753ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.ReduceOnPlateau(learning_rate, mode='min', factor=0.1, patience=10, threshold=1e-4, threshold_mode='rel', cooldown=0, min_lr=0, epsilon=1e-8, verbose=False)
该接口提供Loss自适应学习率的策略。如果 loss 停止下降超过patience个epoch,学习率将会衰减为 learning_rate * factor。每降低一次学习率后,将会进入一个时长为cooldown个epoch的冷静期,在冷静期内,将不会监控loss的变化情况,也不会衰减。在冷静期之后,会继续监控loss的上升或下降。
## 开始训练!python code/train_reduceonplateau.py
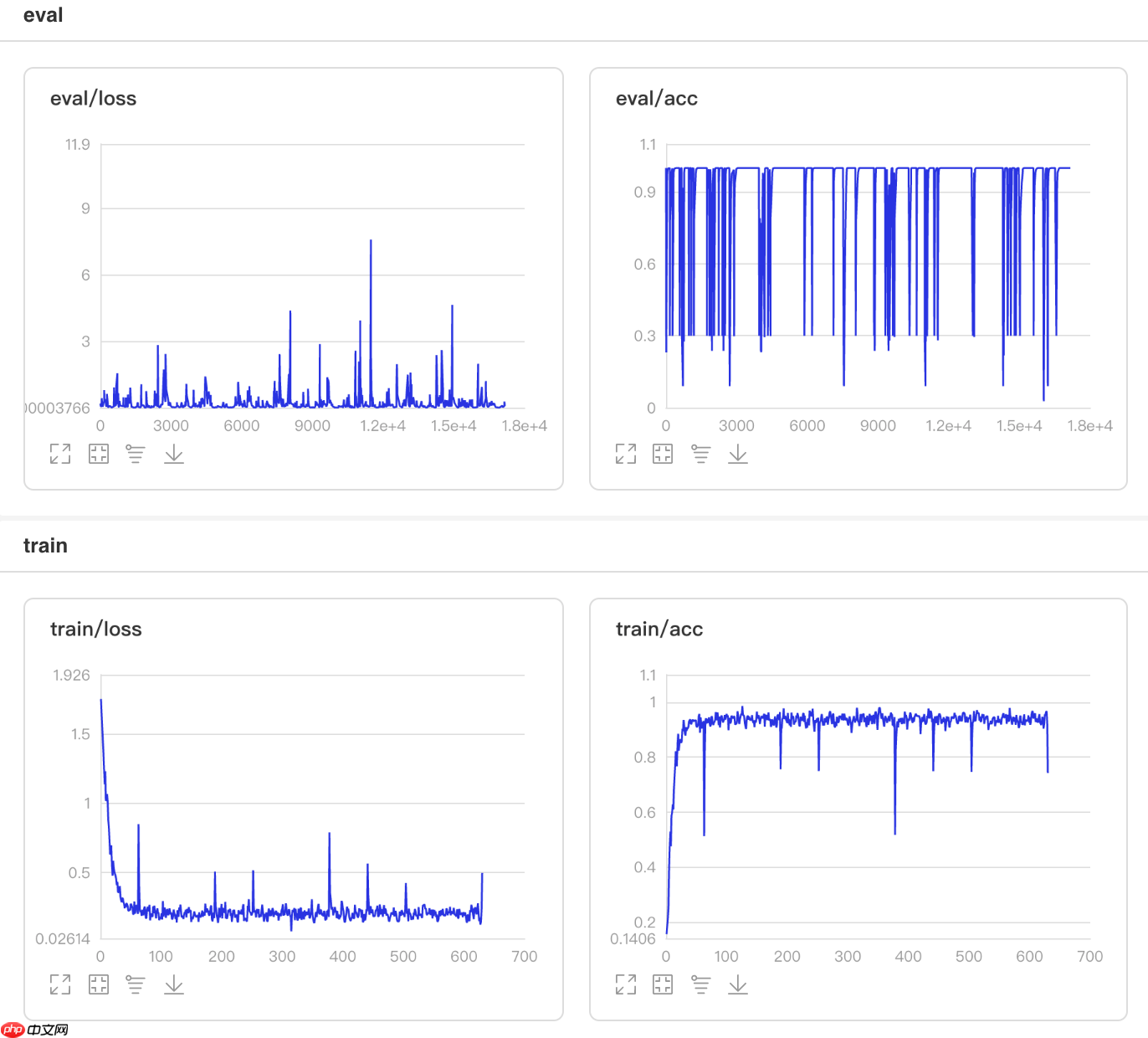
图11 ReduceOnPlateau训练验证图
## 查看测试集上的效果!python code/test.py --lr 'ReduceOnPlateau'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 00:26:51.685511 20016 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0508 00:26:51.690647 20016 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9365 - 706ms/step Eval samples: 1763
使用方法为:paddle.optimizer.lr.StepDecay(learning_rate, step_size, gamma=0.1, last_epoch=-1, verbose=False)
该接口提供一种学习率按指定间隔轮数衰减的策略。
## 开始训练!python code/train.py --lr 'StepDecay'
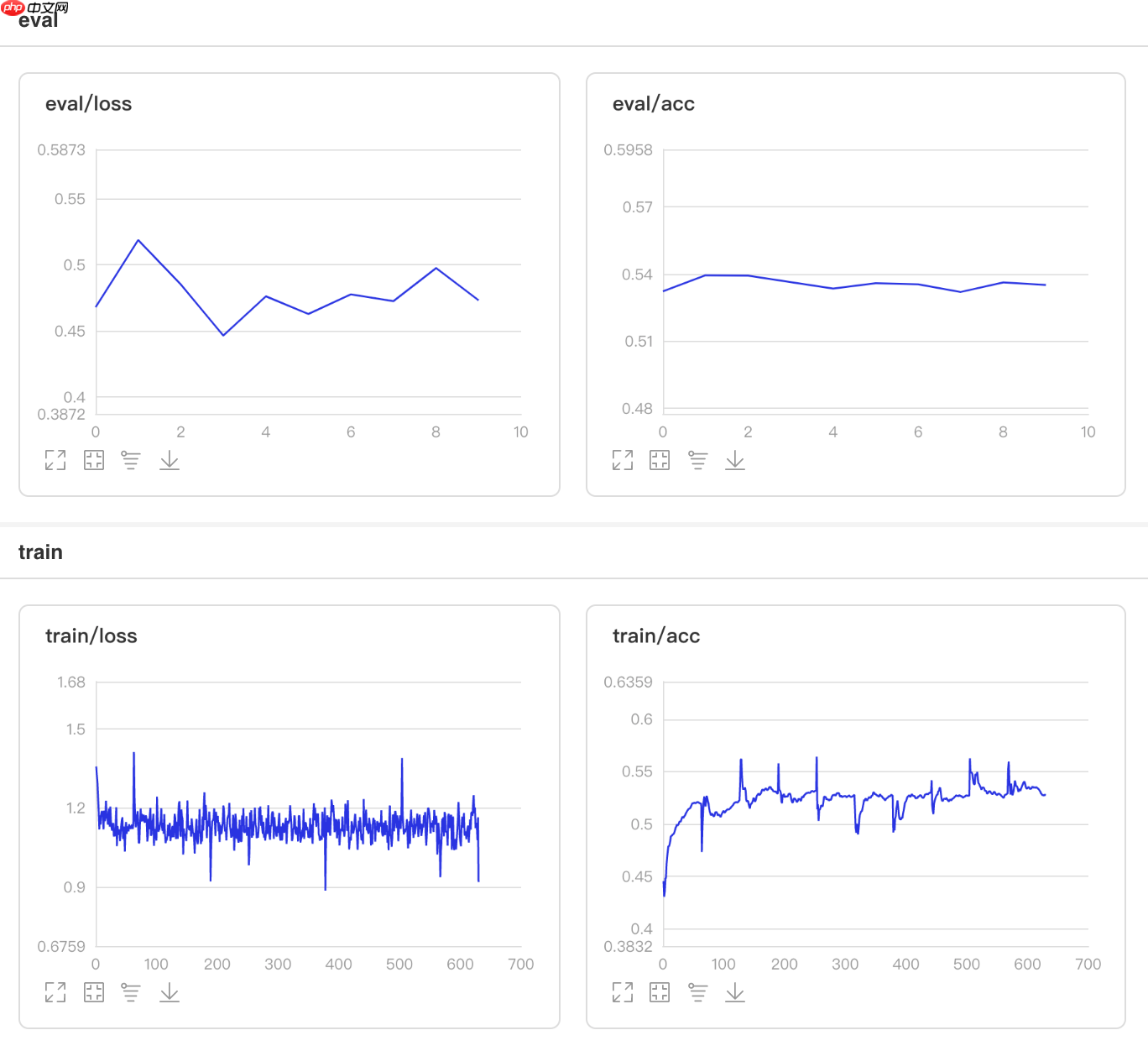
图12 StepDecay训练验证图
## 查看测试集上的效果!python code/test.py --lr 'StepDecay'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0507 23:30:52.671571 14817 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0507 23:30:52.676681 14817 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.5315 - 733ms/step Eval samples: 1763
自定义学习率除了可以使用Paddle2.0中提供的学习率算法基类paddle.optimizer.lr.LRScheduler以外,还可以完全不依赖基类自定义学习率,这里采用自定义的方法实现循环学习率算法CLR和采用基类paddle.optimizer.lr.LRScheduler实现每隔一定epoch衰减学习率的Adjust_lr。
CLR方法来自于论文Cyclical Learning Rates for Training Neural Networks
根据论文的描述,CLR方法可以在训练过程中周期性的增大和减小学习率,从而使学习率始终在最优点附近徘徊。
更新公式如下:

## 开始训练!python code/train_clr.py
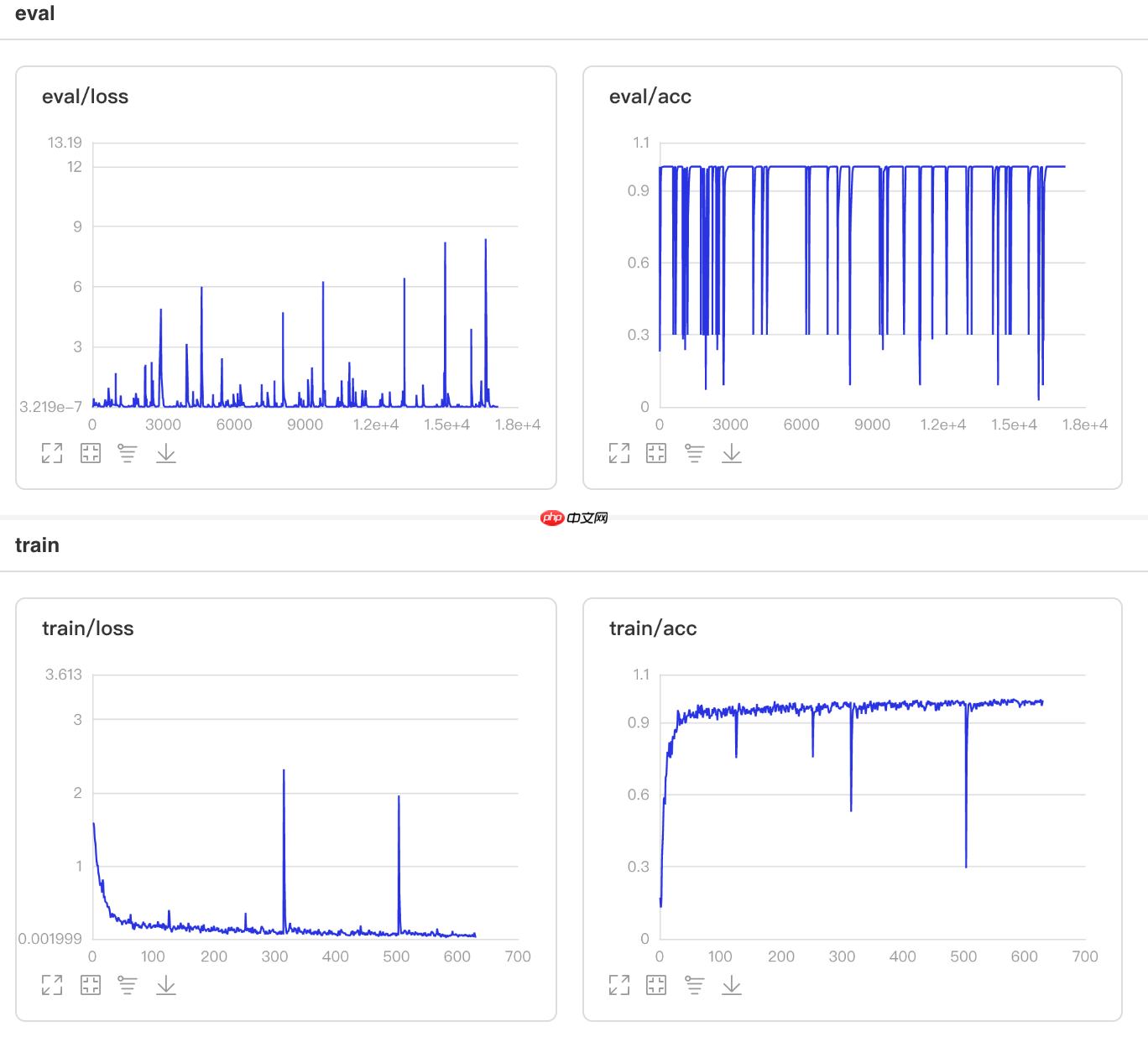
图13 CLR训练验证图
## 查看测试集上的效果!python code/test.py --lr 'clr'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0508 21:37:39.301434 105 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0508 21:37:39.306394 105 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9575 - 731ms/step Eval samples: 1763
这里实现的Adjust_lr方法的更新算法是:在整个10个epoch里,每隔2个epoch将学习率衰减为原来的0.95倍。
## 开始训练!python code/train.py --lr 'Adjust_lr'
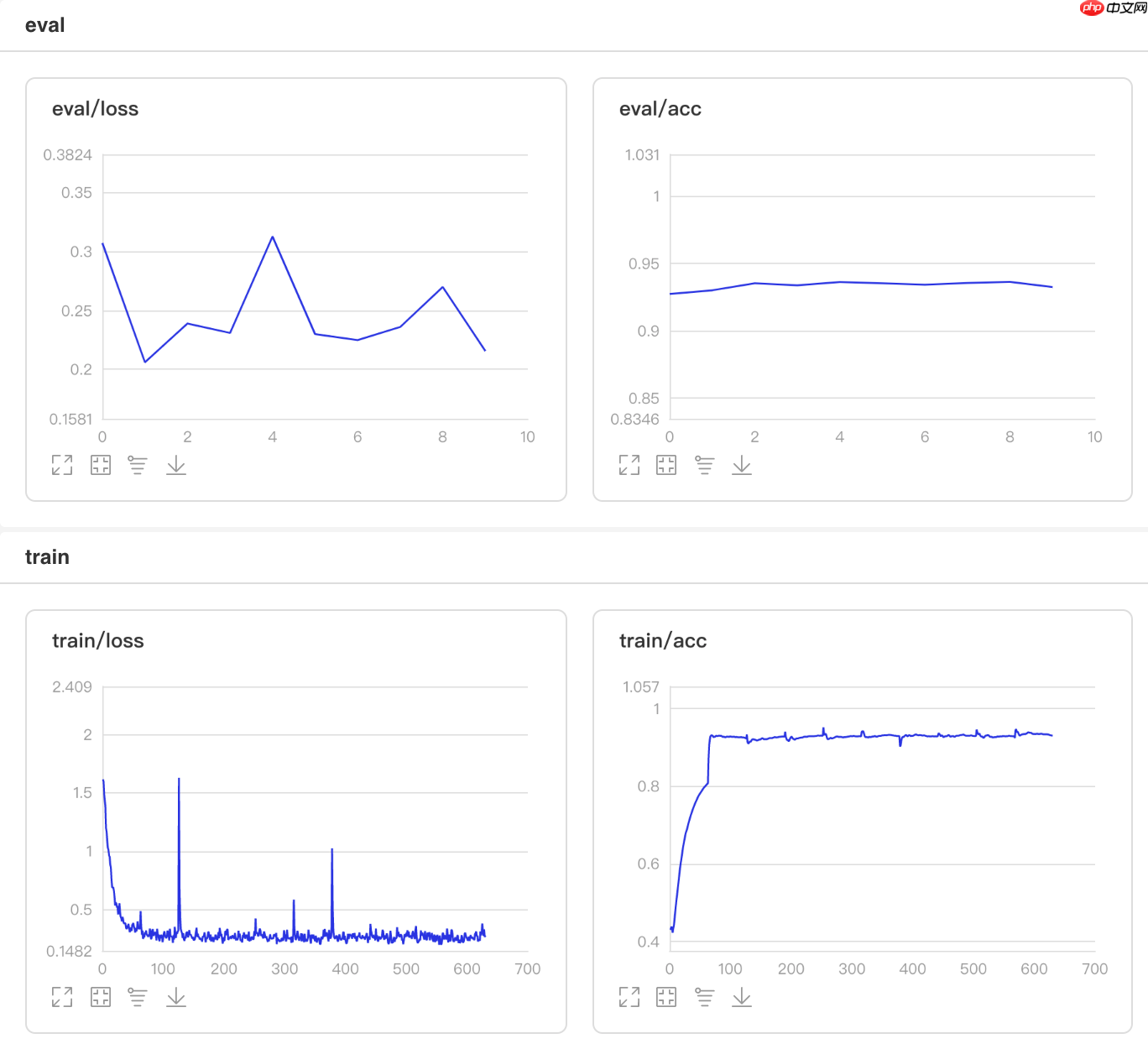
图14 Adjust_lr训练验证图
## 查看测试集上的效果!python code/test.py --lr 'Adjust_lr'
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int): W0511 21:55:19.051586 6496 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W0511 21:55:19.055864 6496 device_context.cc:372] device: 0, cuDNN Version: 7.6. Eval begin... The loss value printed in the log is the current batch, and the metric is the average value of previous step. step 28/28 [==============================] - acc: 0.9308 - 713ms/step Eval samples: 1763
本项目中所有学习率的性能比较如下图所示,其中自定义的循环学习率CLR效果最好,建议使用。其次为LinearWarmup 、NoamDecay、CosineAnnealingDecay和PiecewiseDecay,值得尝试。
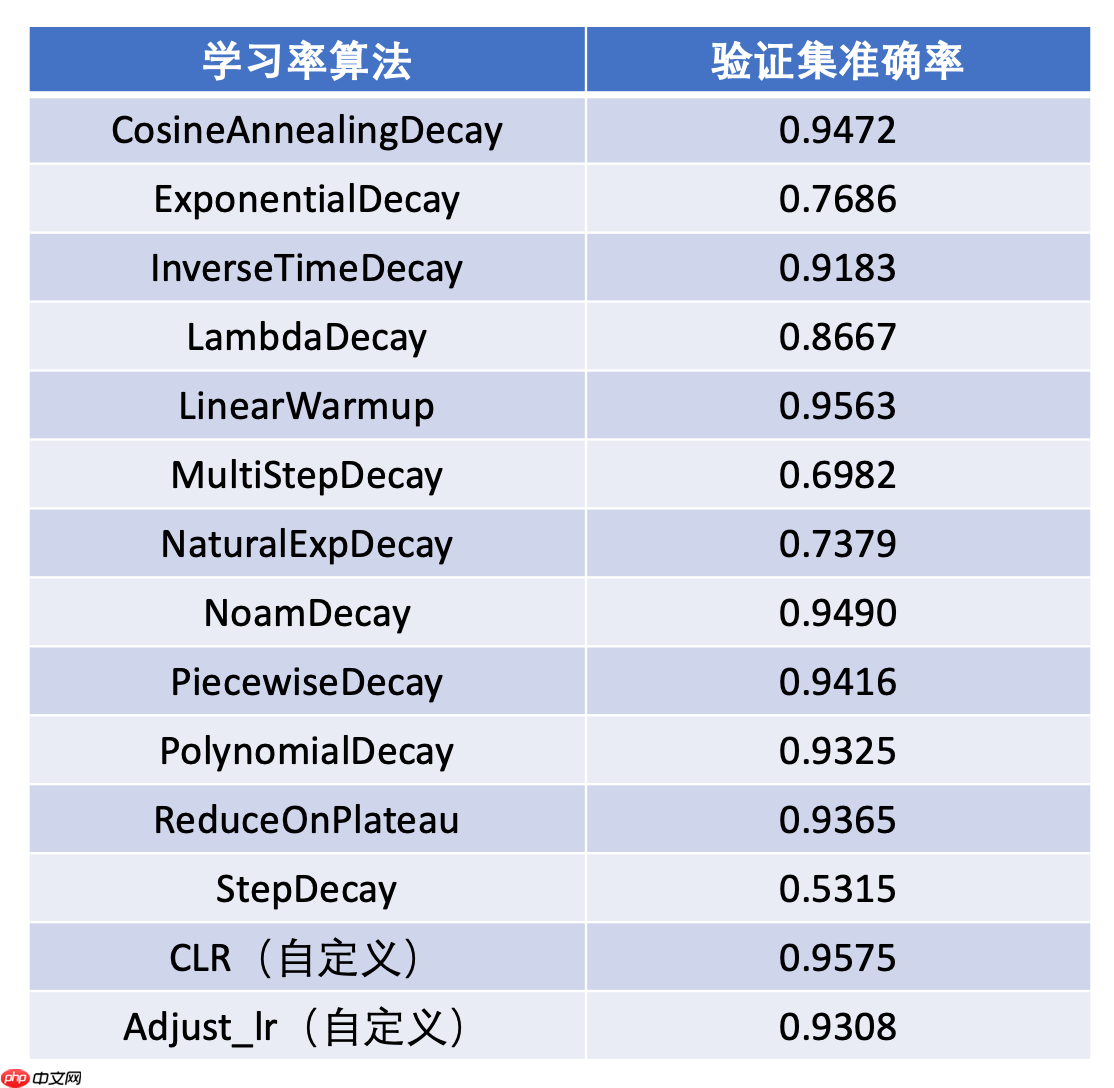
图14 学习率性能比较
以上就是一文搞懂Paddle2.0中的学习率的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 945
945























