
这篇论文《towards a better tradeoff between effectiveness and efficiency in pre-ranking: a learnable feature selection based approach》向我们展示了如何在粗排模型中平衡模型的效率和效果。文中提出了基于可学习特征选择的fscd方法,并在真实的电商系统中进行了应用。
简介
 如图(a)所示,由于系统时延的限制,推荐系统通常是多阶段的。图(b)中,论文指出,简单的representation-focused(RF)模型会严重限制模型的表达能力(如传统的双塔模型,最后一层向量点积,就是简单的RF模型),主要是因为缺乏特征交叉。因此,我们能否在特征上进行优化,只保留效果好的特征,同时保证模型推断效率更高,使用与精排相同的高交互性(interaction-focused, IF)的模型呢?答案是肯定的!
如图(a)所示,由于系统时延的限制,推荐系统通常是多阶段的。图(b)中,论文指出,简单的representation-focused(RF)模型会严重限制模型的表达能力(如传统的双塔模型,最后一层向量点积,就是简单的RF模型),主要是因为缺乏特征交叉。因此,我们能否在特征上进行优化,只保留效果好的特征,同时保证模型推断效率更高,使用与精排相同的高交互性(interaction-focused, IF)的模型呢?答案是肯定的!
FSCD
 粗排模型使用精排模型并保持高效率,就意味着在某些方面需要做出牺牲,而这无疑是在特征上进行的。因此,IF的粗排模型使用的是精排模型的特征子集。如图所示,FSCD方法通过梯度优化来保证效果,通过特征维度的正则化来保证效率。在训练过程中,可以挖掘出一批有用的特征。
粗排模型使用精排模型并保持高效率,就意味着在某些方面需要做出牺牲,而这无疑是在特征上进行的。因此,IF的粗排模型使用的是精排模型的特征子集。如图所示,FSCD方法通过梯度优化来保证效果,通过特征维度的正则化来保证效率。在训练过程中,可以挖掘出一批有用的特征。
对于每个特征,都有一个可学习的dropout参数Z? ∈ {0, 1},并且符合伯努利分布:
 该分布的超参数由特征复杂度cj决定,而cj由特征的计算复杂度oj、向量维度ej和key的数量nj共同决定。
该分布的超参数由特征复杂度cj决定,而cj由特征的计算复杂度oj、向量维度ej和key的数量nj共同决定。
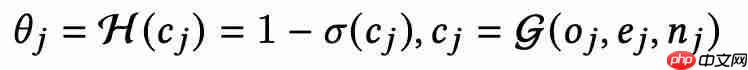
 最终的损失函数如下所示:
最终的损失函数如下所示:
 我们可以看到每个zj还会乘上正则化系数:
我们可以看到每个zj还会乘上正则化系数:
 由于zj的伯努利分布不可导,可以近似为:
由于zj的伯努利分布不可导,可以近似为:
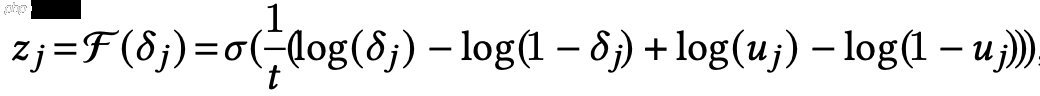 实验
实验
 参考文献
参考文献
1、Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach
https://www.php.cn/link/2c19c8daab0288cfce5172b551ff6d00
2、https://www.php.cn/link/8631f219500638a09ee08a3033f25f43
以上就是用Dropout思想做特征选择保证效果,还兼顾了线上性能?的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 884
884























