将搜集到的数据图片简单筛选下,整合在一个文件夹下
可以使用ReNamer进行图片批量重命名
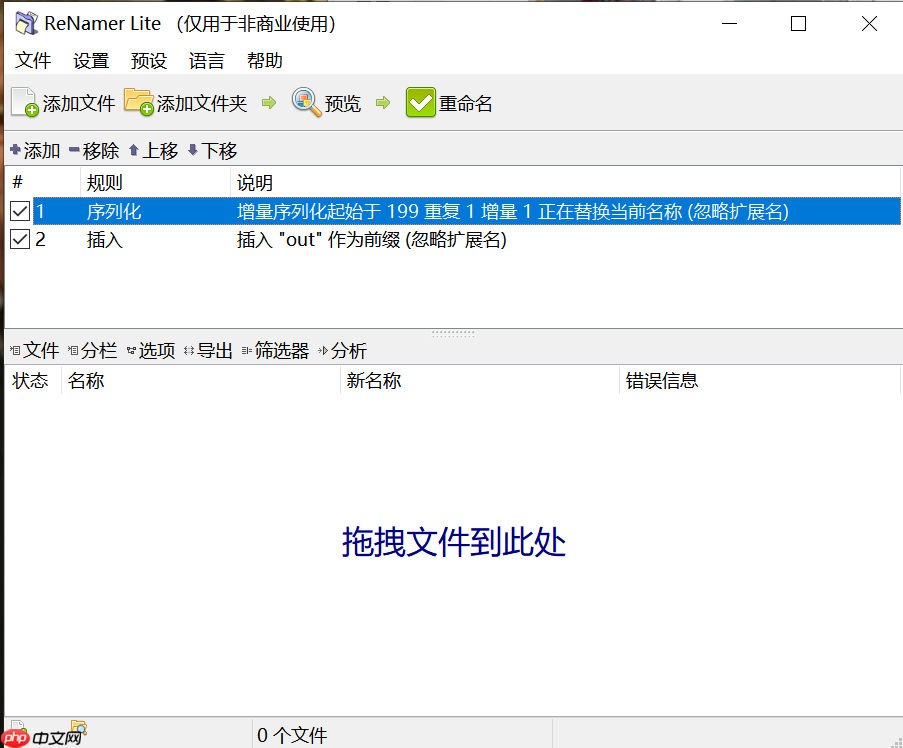
将图片文件夹压缩得到.zip文件
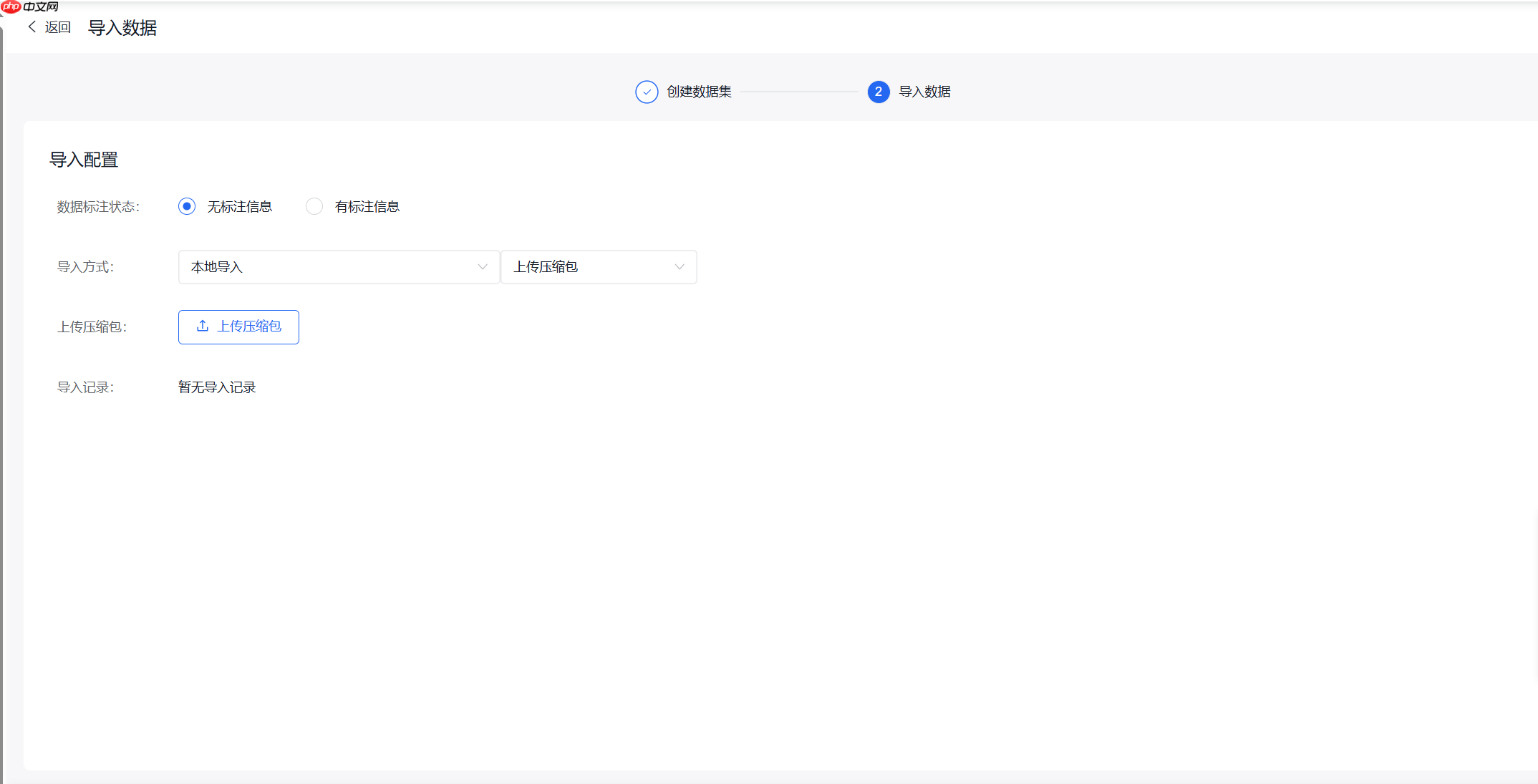
(1)导入数据
将图片压缩包上传至EazyData
从网上收集到的数据可能有不符合要求的内容,请手动将部分图片进行删除,后续清洗无法处理这些图片
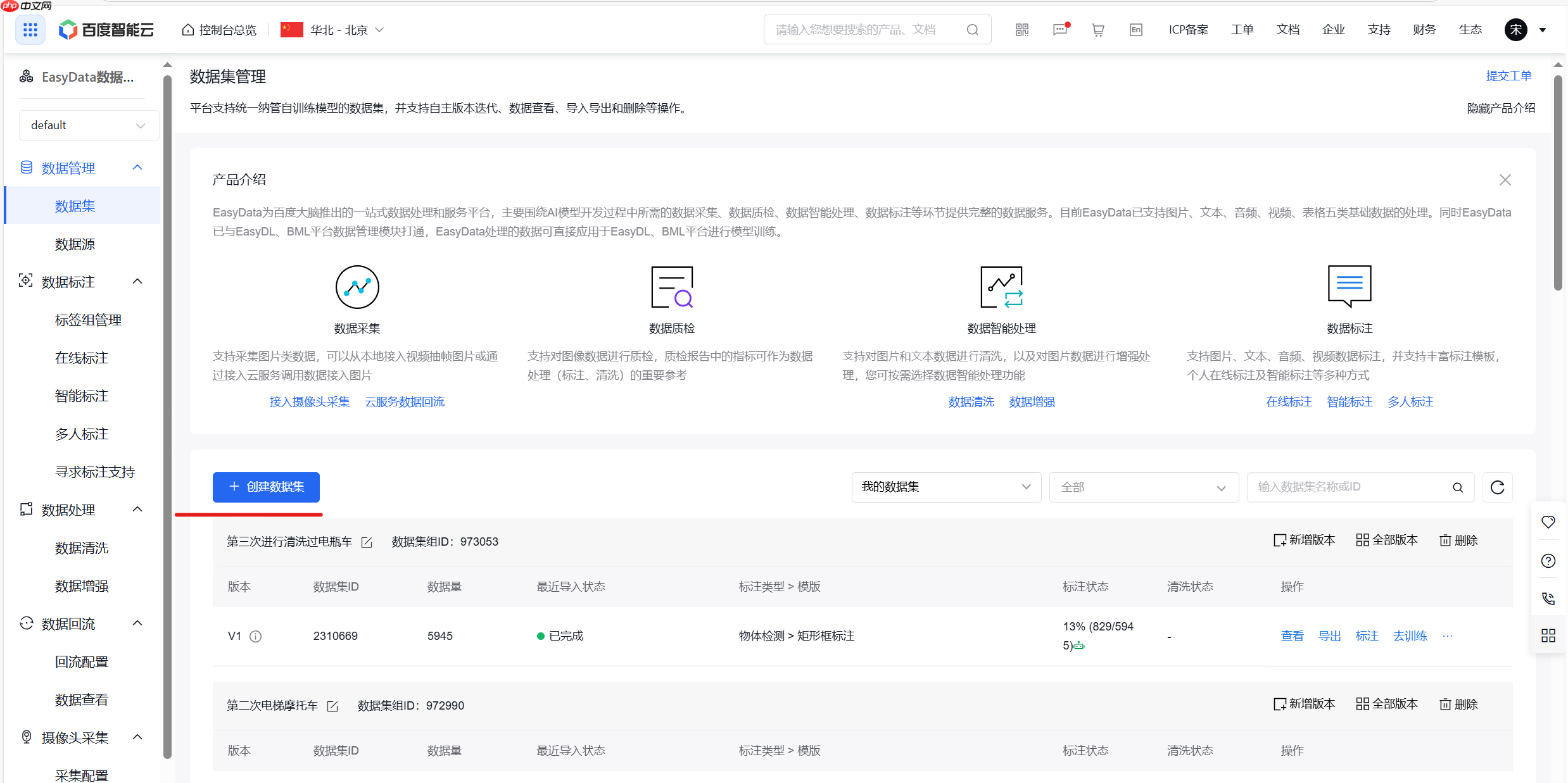
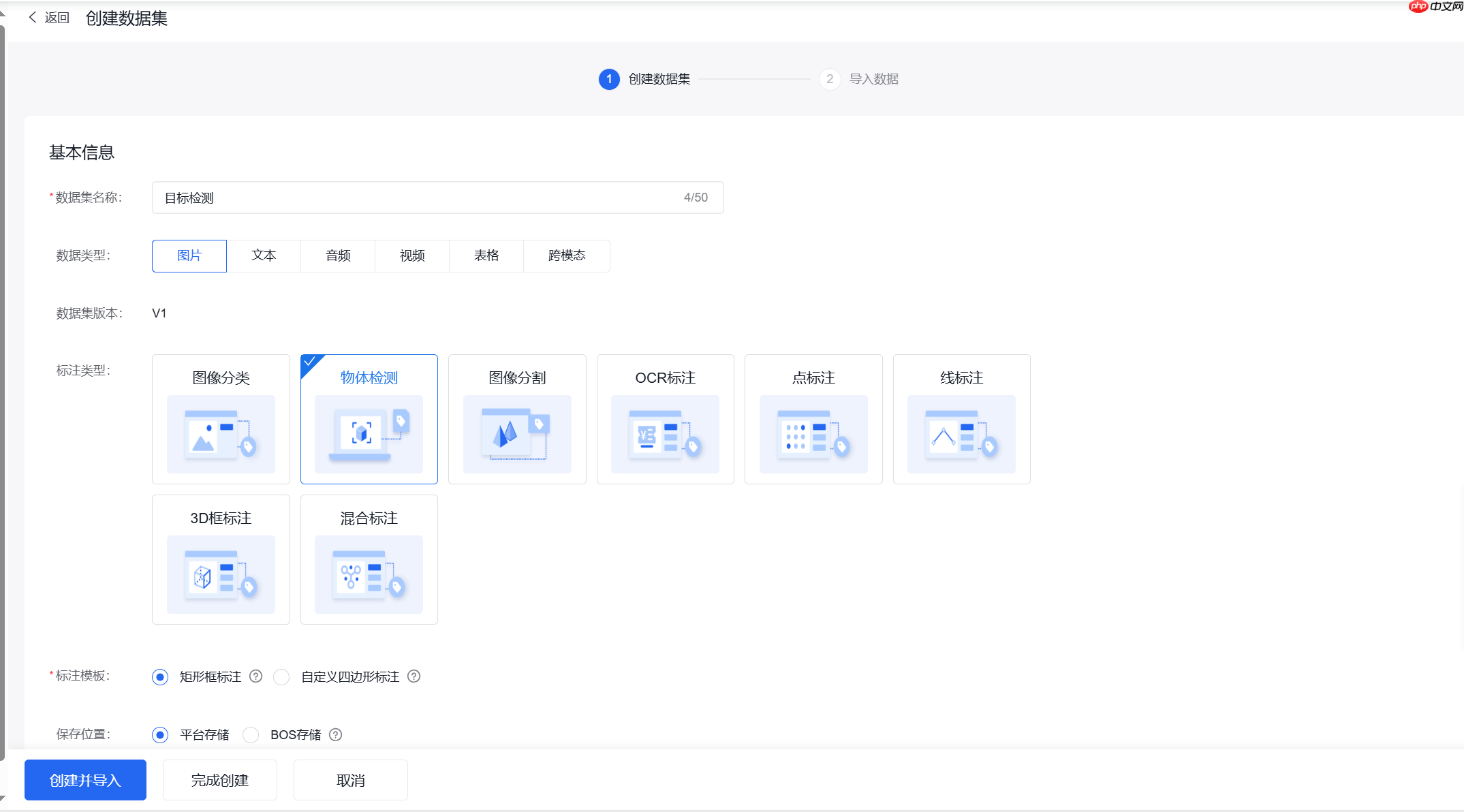
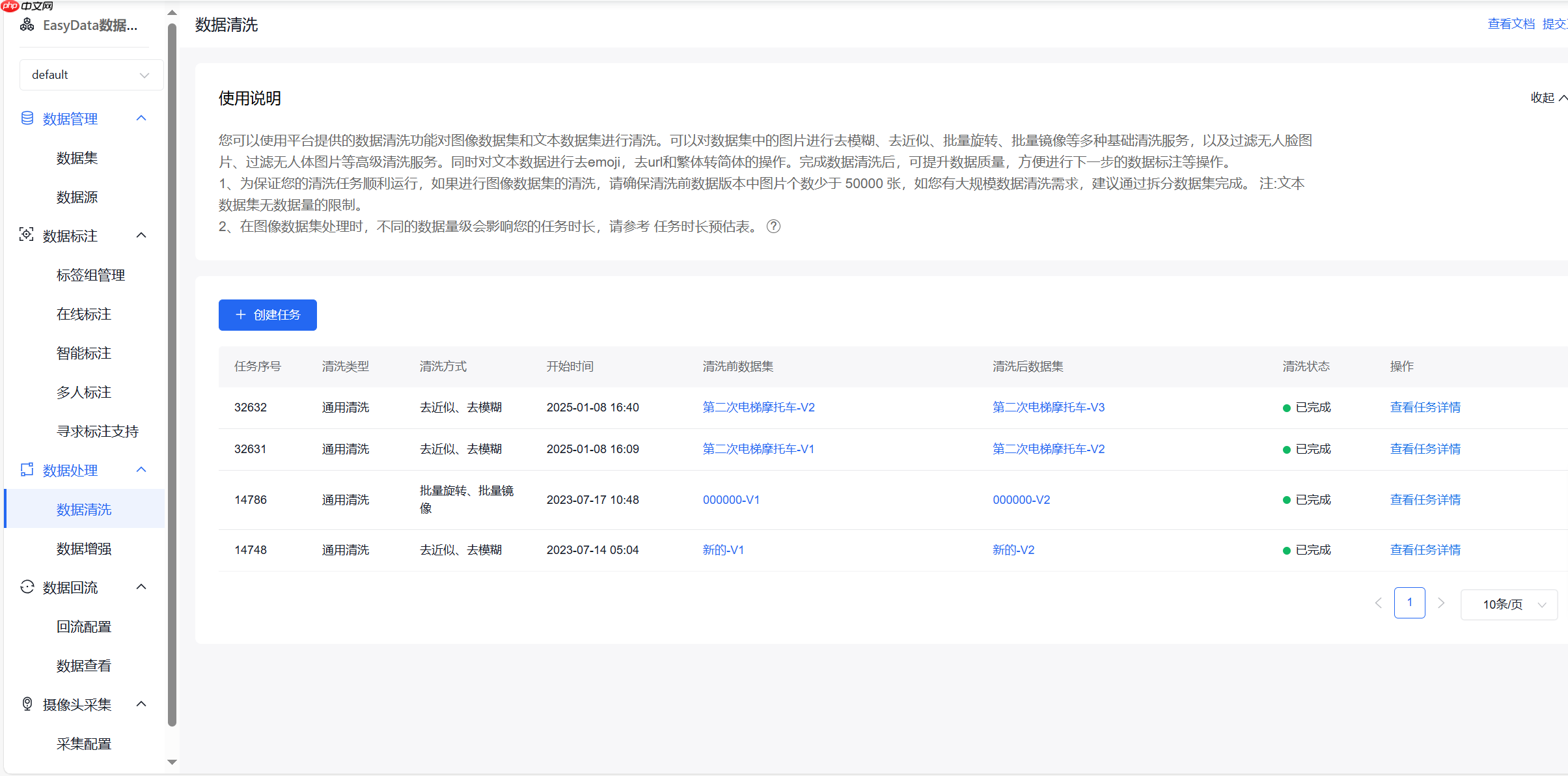
(2)数据清洗
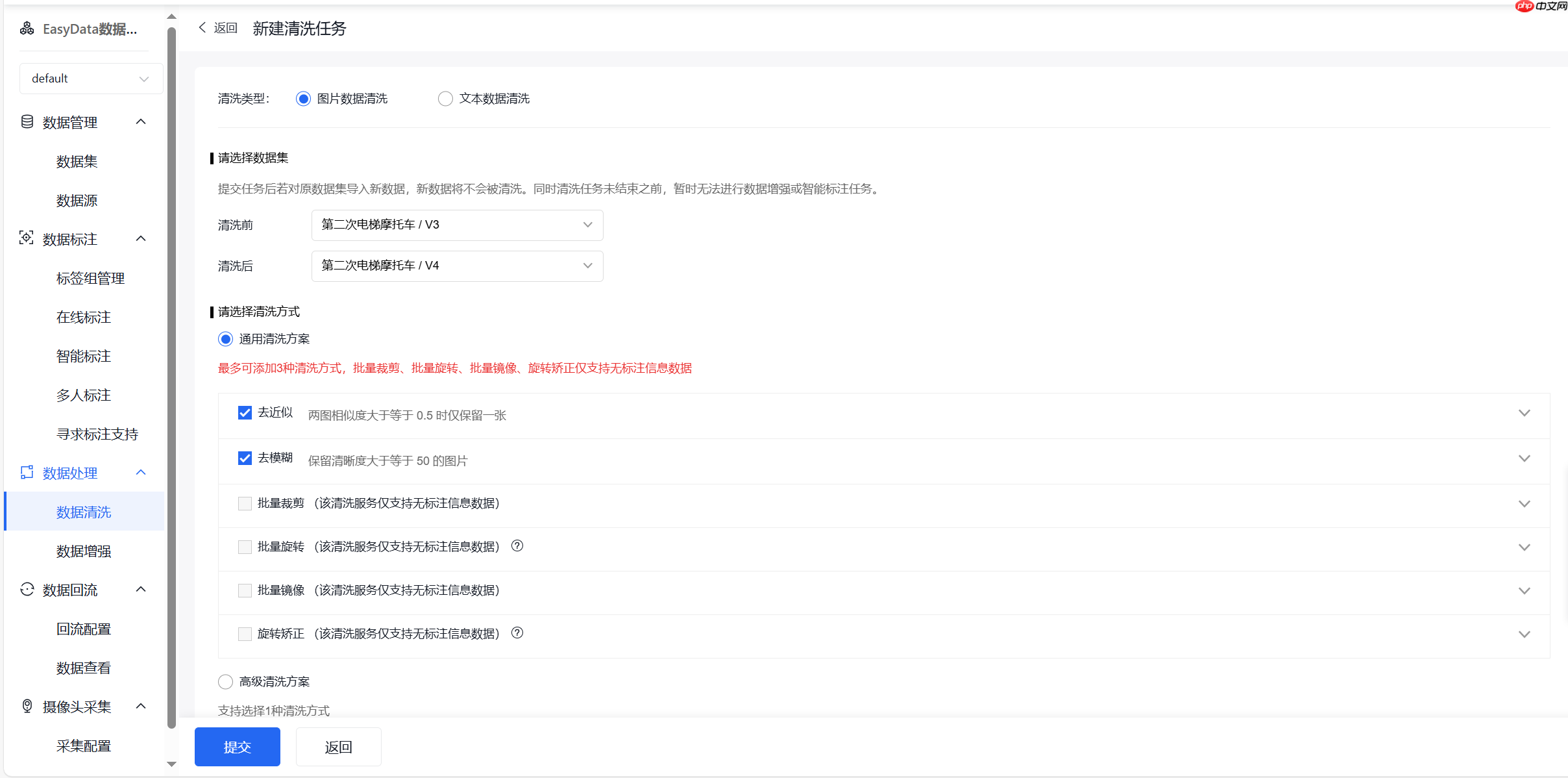
创建清洗任务
选择合适的清洗方式,去近似以及去模糊可以选择具体的相似度和模糊度
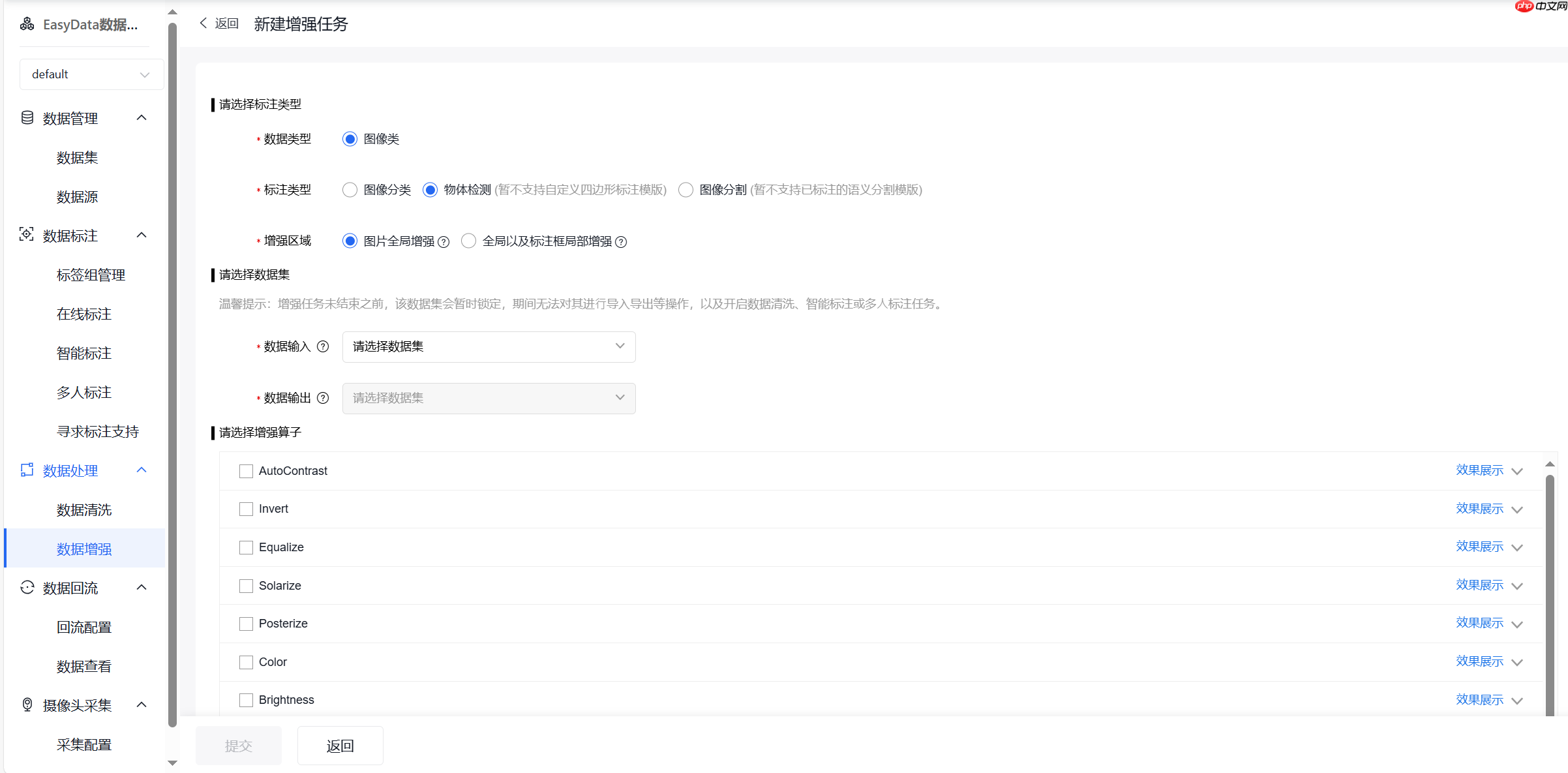
(3)数据增强
这次例子没有使用数据增强原因是数据数量应该够用,倘若数据过少可以尝试使用数据增强进行处理。具体操作请自行摸索了。
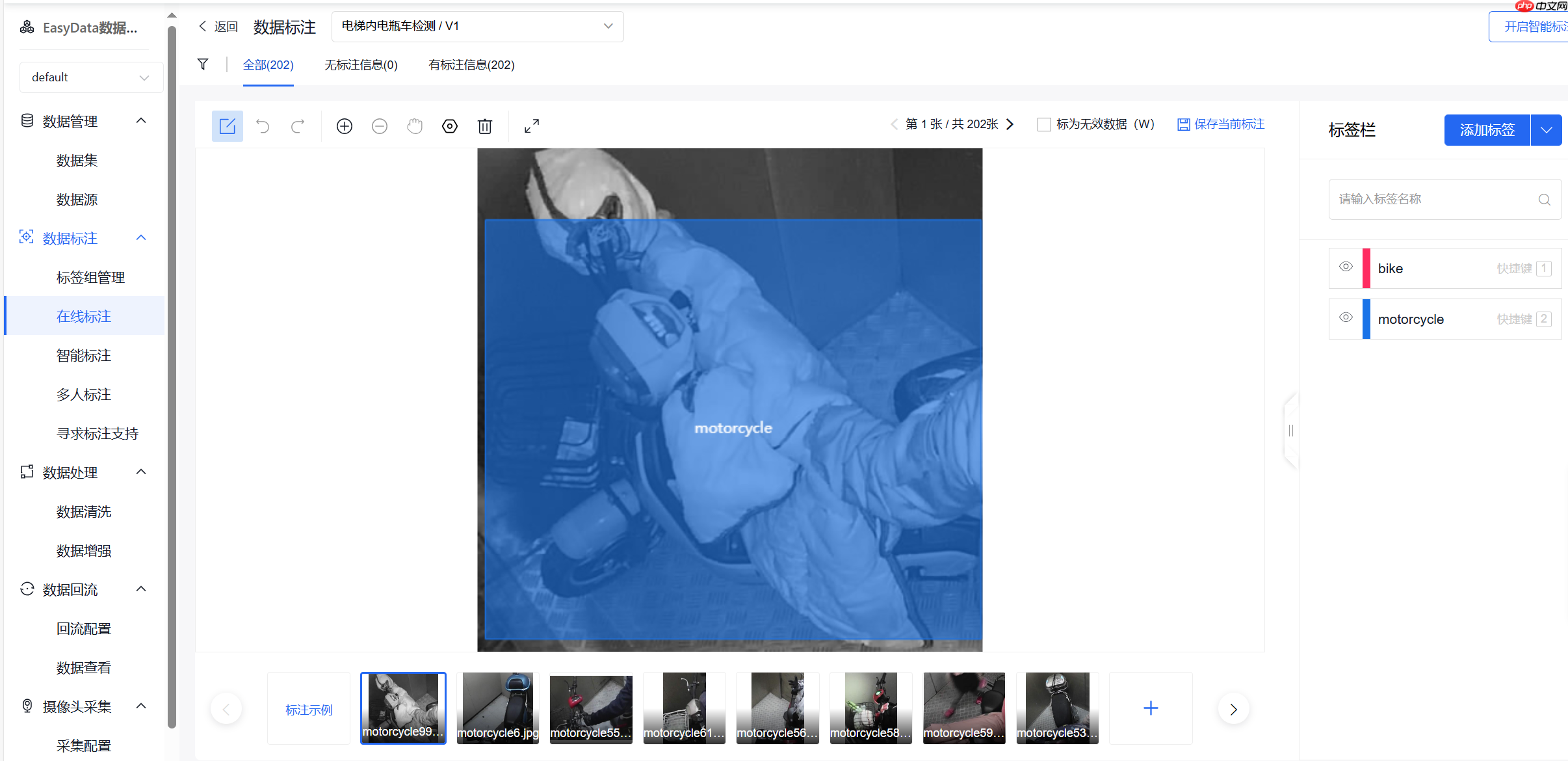
(4)标注数据
首先在右侧添加标签
然后就可以在图片内部进行画框,快捷键写标签了,按s保存此张
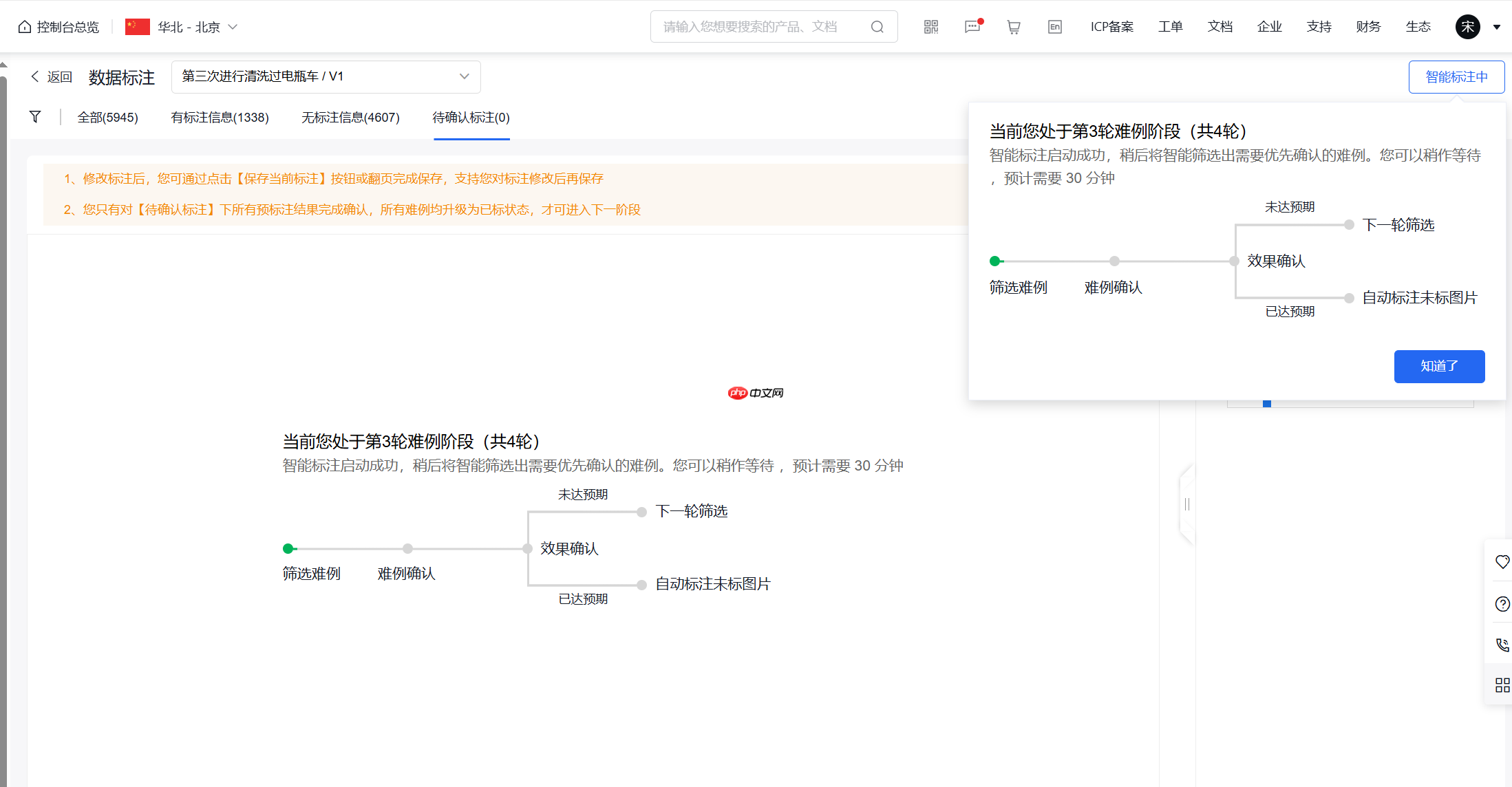
如果数据集过多可以使用智能标签
需要每样标签都有至少十个才能启动
建议是每个样式的数据都标注一些再启动
智能标注流程如下
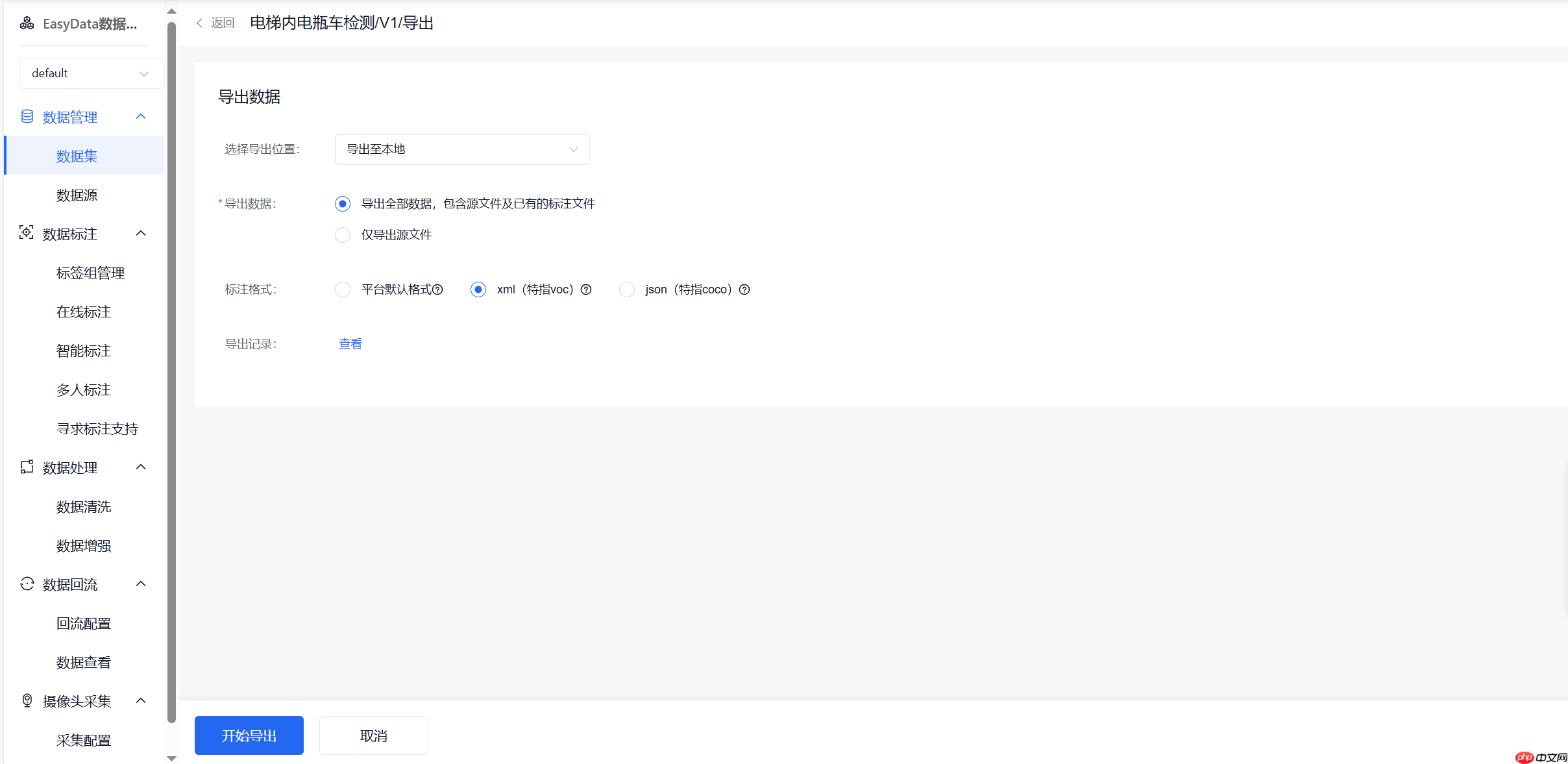
(5)导出
选择xml格式导出
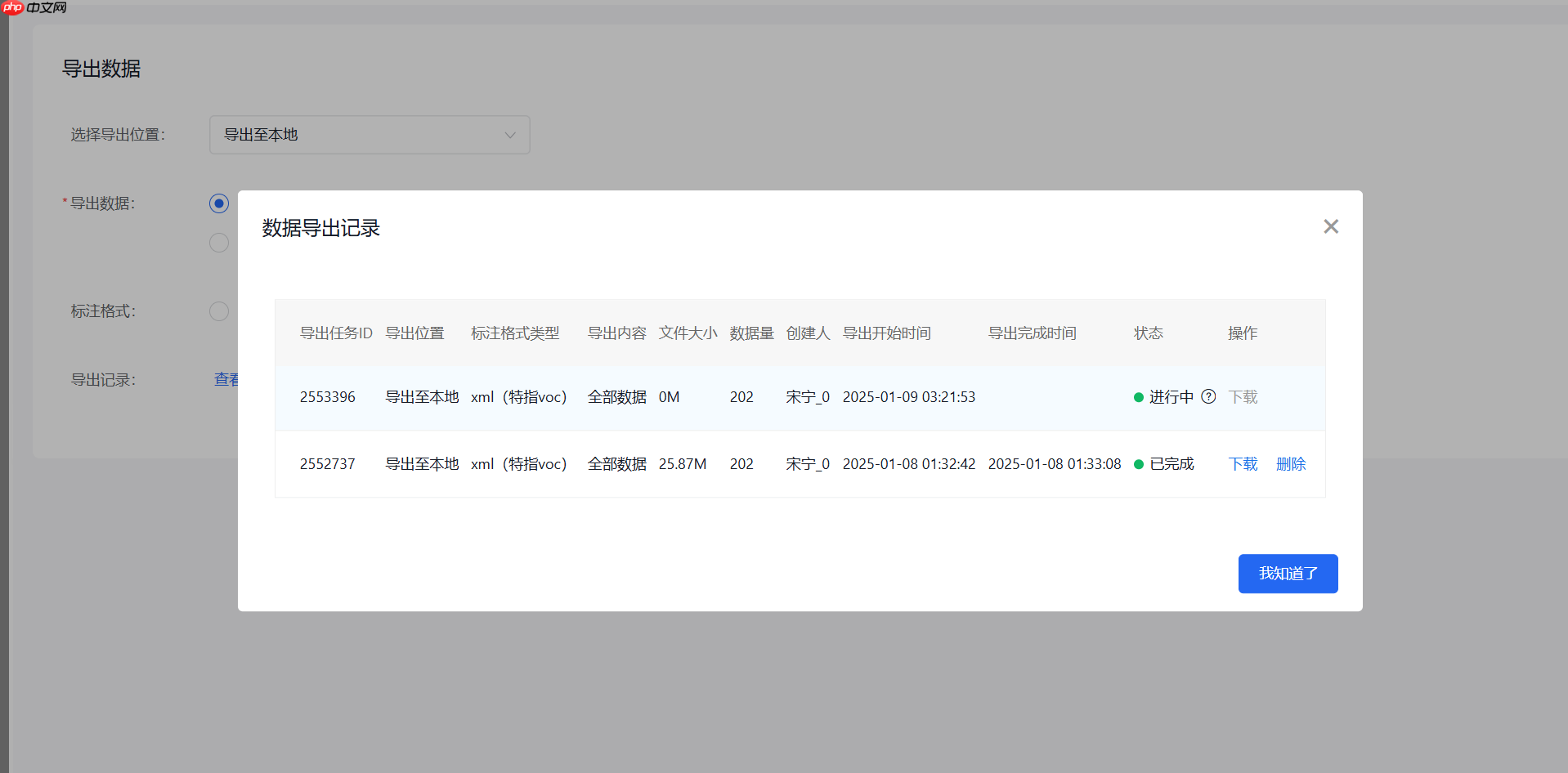
将压缩包的名称以及内部文件夹名称重命名为合适的名称
将annotations和images文件夹首字母改为小写
在左侧data目录下上传重命名后的数据集
!ls ~/data
# 解压PaddleDetection压缩包%cd /home/aistudio/data/data267567 !unzip -q PaddleDetection-release-2.6.zip -d /home/aistudio
# 安装requirements中的依赖%cd ~/PaddleDetection-release-2.6!pip install -r requirements.txt#安装过慢可以打开requirements.txt文件,注释掉opencv-python <= 4.6.0(在前面加“#”)# 然后将此命令前的“#”删掉重新运行# !pip install opencv-python <= 4.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple# 编译安装paddledet!python setup.py install %cd ~
# 移动到当前挂载的数据集目录# 解压数据集到指定目录下%cd /home/aistudio/data/data313161/ !unzip -q lift.zip -d /home/aistudio
/home/aistudio/data/data313161
[lift.zip]
End-of-central-directory signature not found. Either this file is not
a zipfile, or it constitutes one disk of a multi-part archive. In the
latter case the central directory and zipfile comment will be found on
the last disk(s) of this archive.
note: lift.zip may be a plain executable, not an archive
unzip: cannot find zipfile directory in one of lift.zip or
lift.zip.zip, and cannot find lift.zip.ZIP, period.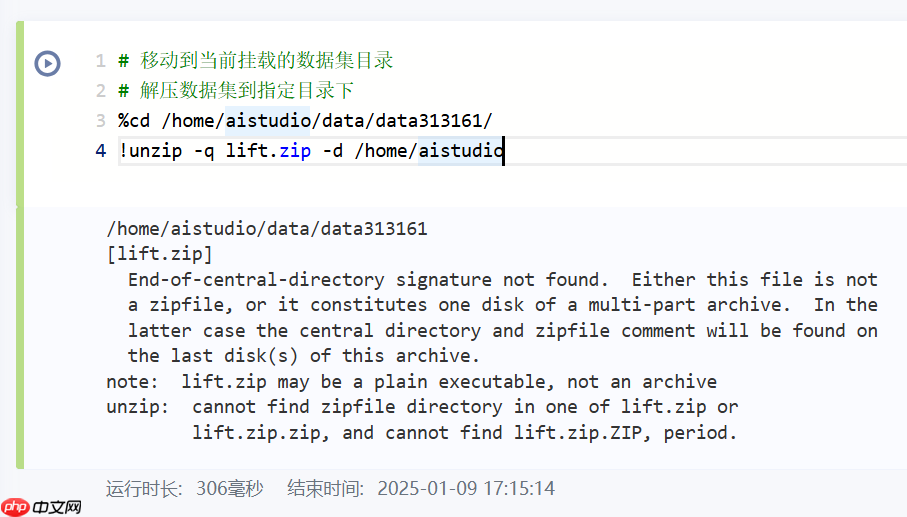
如果出现以上错误,请运行下面的代码
%cd /home/aistudio/ !unzip -q lift.zip -d /home/aistudio
这里训练集和验证集是按4:1划分的,可以将全部的数据集都用作训练
import os#生成train.txt、val.txtxml_dir = '/home/aistudio/lift/annotations'img_dir = '/home/aistudio/lift/images'path_list = list()for img in os.listdir(img_dir):
img_path = os.path.join(img_dir,img)
xml_path = os.path.join(xml_dir,img.replace('jpg', 'xml'))
path_list.append((img_path, xml_path))
train_f = open('/home/aistudio/lift/train.txt','w')
val_f = open('/home/aistudio/lift/val.txt','w')
for i ,content in enumerate(path_list):
img, xml = content
text = img + ' ' + xml + '\n'
if i % 5 == 0:
val_f.write(text) else:
train_f.write(text)
train_f.close()
val_f.close()在运行下面代码块前,请修改label_list.txt文件
内容为标签名称(每个标签单独一行如图所示)**
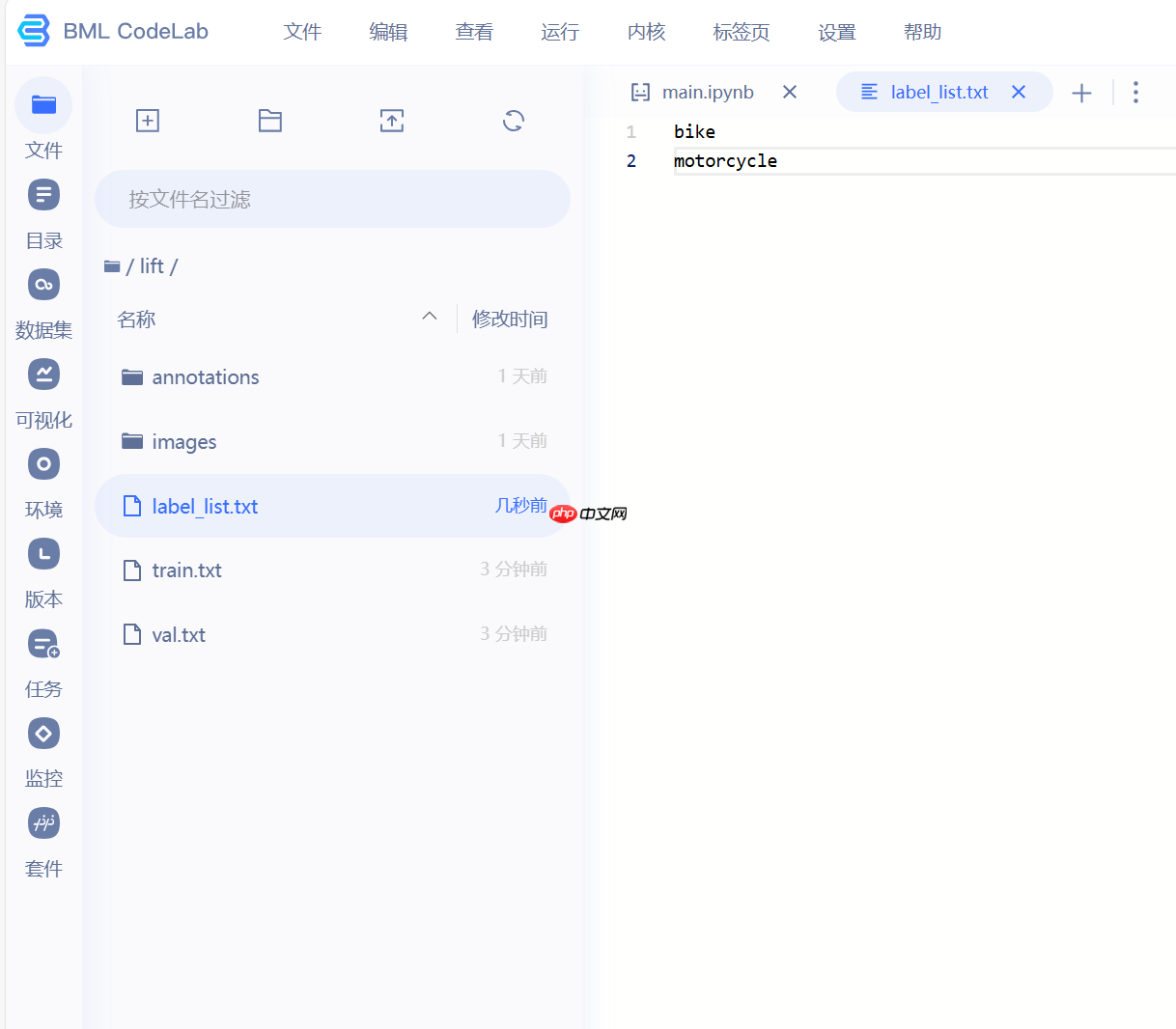
!cp ~/label_list.txt ~/lift
%cd ~/PaddleDetection-release-2.6# 生成训练集!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/lift/annotations/ \
--voc_anno_list /home/aistudio/lift/train.txt \
--voc_label_list /home/aistudio/lift/label_list.txt \
--voc_out_name /home/aistudio/lift/train.json# 生成验证集!python tools/x2coco.py \
--dataset_type voc \
--voc_anno_dir /home/aistudio/lift/annotations/ \
--voc_anno_list /home/aistudio/lift/val.txt \
--voc_label_list /home/aistudio/lift/label_list.txt \
--voc_out_name /home/aistudio/lift/val.json/home/aistudio/PaddleDetection-release-2.6 Start converting ! 100%|██████████████████████████████████████| 161/161 [00:00<00:00, 26787.38it/s] Start converting ! 100%|████████████████████████████████████████| 41/41 [00:00<00:00, 23877.60it/s]
import osfrom unicodedata import nameimport xml.etree.ElementTree as ETimport globdef count_num(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml') dict = {} # 新建字典,用于存放各类标签名及其对应的数目
for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot() # 遍历文件的所有标签
for obj in root.iter('object'):
name = obj.find('name').text if(name in dict.keys()): dict[name] += 1 # 如果标签不是第一次出现,则+1
else: dict[name] = 1 # 如果标签是第一次出现,则将该标签名对应的value初始化为1
# 打印结果
print("各类标签的数量分别为:") for key in dict.keys():
print(key + ': ' + str(dict[key]))
indir='/home/aistudio/lift/annotations' # xml文件所在的目录count_num(indir) # 调用函数统计各类标签数目各类标签的数量分别为: motorcycle: 184 bike: 24
第一次运行卡了,可以尝试重新运行一次,下面应该是要有图的
import osimport matplotlib.pyplot as pltfrom unicodedata import nameimport xml.etree.ElementTree as ETimport globdef ratio(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml') # count_0, count_1, count_2, count_3 = 0, 0, 0, 0 # 举反例,不要这么写
count = [0 for i in range(20)] for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot() # 遍历文件的所有检测框
for obj in root.iter('object'):
xmin = obj.find('bndbox').find('xmin').text
ymin = obj.find('bndbox').find('ymin').text
xmax = obj.find('bndbox').find('xmax').text
ymax = obj.find('bndbox').find('ymax').text
Aspect_ratio = (int(ymax)-int(ymin)) / (int(xmax)-int(xmin)) if int(Aspect_ratio/0.25) < 19:
count[int(Aspect_ratio/0.25)] += 1
else:
count[-1] += 1
sign = [0.25*i for i in range(20)]
plt.bar(x=sign, height=count) print(count)
indir='/home/aistudio/lift/annotations/' # xml文件所在的目录ratio(indir)[0, 8, 22, 36, 27, 33, 30, 23, 15, 8, 4, 2, 0, 0, 0, 0, 0, 0, 0, 0]
<Figure size 640x480 with 1 Axes>
import osfrom unicodedata import nameimport xml.etree.ElementTree as ETimport globdef Image_size(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
width_heights = [] for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text) if [width, height] not in width_heights: width_heights.append([width, height]) print("数据集中,有{}种不同的尺寸,分别是:".format(len(width_heights))) for item in width_heights: print(item)
indir='/home/aistudio/lift/annotations/' # xml文件所在的目录Image_size(indir)import osfrom unicodedata import nameimport xml.etree.ElementTree as ETimport globdef distribution(indir):
# 提取xml文件列表
os.chdir(indir)
annotations = os.listdir('.')
annotations = glob.glob(str(annotations) + '*.xml')
data_x, data_y = [], [] for i, file in enumerate(annotations): # 遍历xml文件
# actual parsing
in_file = open(file, encoding = 'utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
width = int(root.find('size').find('width').text)
height = int(root.find('size').find('height').text) # 遍历文件的所有检测框
for obj in root.iter('object'):
xmin = int(obj.find('bndbox').find('xmin').text)
ymin = int(obj.find('bndbox').find('ymin').text)
xmax = int(obj.find('bndbox').find('xmax').text)
ymax = int(obj.find('bndbox').find('ymax').text)
x = (xmin + (xmax-xmin)) / width
y = (ymin + (ymax-ymin)) / height
data_x.append(x)
data_y.append(y)
plt.scatter(data_x, data_y, s=1, alpha=0.1)
indir='/home/aistudio/lift/annotations/' # xml文件所在的目录distribution(indir)<Figure size 640x480 with 1 Axes>
修改模型配置文件中的第一行,将PaddleDetection/configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml第一行的coco_detection.yml修改为coco_lift.yml
%cd /home/aistudio !cp coco_lift.yml /home/aistudio/PaddleDetection-release-2.6/configs/datasets/
/home/aistudio
具体参数需自行调整,默认使用官方的,建议调整下base_lr,在/home/aistudio/PaddleDetection-release-2.6/configs/ppyoloe/base/optimizer_80e.yml路径下,由于我们的单卡,可以将默认的数值改为原先的1/8
这里采用的模型是ppyoloe+_m
%cd /home/aistudio/PaddleDetection-release-2.6# 模型训练 # 如果要恢复训练,则加上 -r output/ppyoloe_plus_crn_m_80e_coco/best_model# 如果要边训练边评估,则加上--eval# 训练时的日志输出将保存在--vdl_log_dir所指的路径下# 模型压缩则加上--slim_config configs/slim/xxx/{SLIM_CONFIG.yml}({SLIM_CONFIG.yml}为指定压缩策略配置文件)!python tools/train.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml --eval \
--use_vdl=true \
--vdl_log_dir=VisualDL# 当训练完成,如有需要,可以删除所有的checkpoint,只保留best_model%cd ~/PaddleDetection-release-2.6/output/ppyoloe_plus_crn_m_80e_coco
!find . -type f -name '[0-9]*'!find . -type f -name '[0-9]*' -exec rm -f {} \;
!echo "delete checkpoints complete!"可以运行了看一下对每张图片的识别,比对后可以针对性进行数据增强
%cd /home/aistudio/PaddleDetection-release-2.6# infer_img表示预测改路径的单张图片# infer_dir表示对该路径下的所有图片进行预测# draw_threshold表示置信度大于该值的框才画出来# 生成的图片保存在/home/aistudio/work/PaddleDetection/infer_output!python tools/infer.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
--infer_dir=/home/aistudio/lift/images \
--output_dir=infer_output/ \
--draw_threshold=0.5 \
-o weights=/home/aistudio/PaddleDetection-release-2.6/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams出现full_graph问题就打开trainer.py把full_graph=True删掉即可
%cd /home/aistudio/PaddleDetection-release-2.6# 将"-o weights"里的模型路径换成你自己训好的模型!python tools/export_model.py \
-c configs/ppyoloe/ppyoloe_plus_crn_m_80e_coco.yml \
-o weights=/home/aistudio/PaddleDetection-release-2.6/output/ppyoloe_plus_crn_m_80e_coco/best_model.pdparams \
TestReader.fuse_normalize=true# 创建model文件夹if not os.path.exists('/home/aistudio/model/'):
os.makedirs('/home/aistudio/model/') #创建路径# 将检测模型拷贝到model文件夹中!cp -r /home/aistudio/PaddleDetection-release-2.6/output_inference/ppyoloe_plus_crn_m_80e_coco/* /home/aistudio/model/# 打包代码%cd /home/aistudio/ !zip -r -q -o model.zip model/
/home/aistudio
以上就是手把手教你用PaddleDetection套件训练目标检测模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 641
641























