本文基于《Attention U-Net: Learning Where to Look for the Pancreas》,实现了用于宠物图像分割的Attention U-Net模型。通过划分数据集,构建含注意力门的网络结构,用RMSProp优化器和交叉熵损失训练,经15轮后在测试集上预测,结果展示了模型对宠物图像的分割效果,验证了其有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文:Attention U-Net: Learning Where to Look for the Pancreas

import osimport ioimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image as PilImageimport paddleimport paddle.nn as nnimport paddle.nn.functional as F
paddle.set_device('gpu')
paddle.__version__'2.1.0'
此处数据处理部分借鉴了『跟着雨哥学AI』系列06:趣味案例——基于U-Net的宠物图像分割
# 解压缩!tar -xf data/data50154/images.tar.gz !tar -xf data/data50154/annotations.tar.gz
IMAGE_SIZE = (160, 160)
train_images_path = "images/"label_images_path = "annotations/trimaps/"image_count = len([os.path.join(train_images_path, image_name)
for image_name in os.listdir(train_images_path)
if image_name.endswith('.jpg')])print("用于训练的图片样本数量:", image_count)# 对数据集进行处理,划分训练集、测试集def _sort_images(image_dir, image_type):
"""
对文件夹内的图像进行按照文件名排序
"""
files = [] for image_name in os.listdir(image_dir): if image_name.endswith('.{}'.format(image_type)) \ and not image_name.startswith('.'):
files.append(os.path.join(image_dir, image_name)) return sorted(files)def write_file(mode, images, labels):
with open('./{}.txt'.format(mode), 'w') as f: for i in range(len(images)):
f.write('{}\t{}\n'.format(images[i], labels[i]))
images = _sort_images(train_images_path, 'jpg')
labels = _sort_images(label_images_path, 'png')
eval_num = int(image_count * 0.15)
write_file('train', images[:-eval_num], labels[:-eval_num])
write_file('test', images[-eval_num:], labels[-eval_num:])
write_file('predict', images[-eval_num:], labels[-eval_num:])用于训练的图片样本数量: 7390
with open('./train.txt', 'r') as f:
i = 0
for line in f.readlines():
image_path, label_path = line.strip().split('\t')
image = np.array(PilImage.open(image_path))
label = np.array(PilImage.open(label_path))
if i > 2: break
# 进行图片的展示
plt.figure()
plt.subplot(1,2,1),
plt.title('Train Image')
plt.imshow(image.astype('uint8'))
plt.axis('off')
plt.subplot(1,2,2),
plt.title('Label')
plt.imshow(label.astype('uint8'), cmap='gray')
plt.axis('off')
plt.show()
i = i + 1/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_min = np.asscalar(a_min.astype(scaled_dtype)) /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead a_max = np.asscalar(a_max.astype(scaled_dtype))
<Figure size 432x288 with 2 Axes>
<Figure size 432x288 with 2 Axes>
<Figure size 432x288 with 2 Axes>
import randomfrom paddle.io import Datasetfrom paddle.vision.transforms import transforms as Tclass PetDataset(Dataset):
"""
数据集定义
"""
def __init__(self, mode='train'):
"""
构造函数
"""
self.image_size = IMAGE_SIZE
self.mode = mode.lower()
assert self.mode in ['train', 'test', 'predict'], \ "mode should be 'train' or 'test' or 'predict', but got {}".format(self.mode)
self.train_images = []
self.label_images = [] with open('./{}.txt'.format(self.mode), 'r') as f: for line in f.readlines():
image, label = line.strip().split('\t')
self.train_images.append(image)
self.label_images.append(label)
def _load_img(self, path, color_mode='rgb', transforms=[]):
"""
统一的图像处理接口封装,用于规整图像大小和通道
"""
with open(path, 'rb') as f:
img = PilImage.open(io.BytesIO(f.read())) if color_mode == 'grayscale': # if image is not already an 8-bit, 16-bit or 32-bit grayscale image
# convert it to an 8-bit grayscale image.
if img.mode not in ('L', 'I;16', 'I'):
img = img.convert('L') elif color_mode == 'rgba': if img.mode != 'RGBA':
img = img.convert('RGBA') elif color_mode == 'rgb': if img.mode != 'RGB':
img = img.convert('RGB') else: raise ValueError('color_mode must be "grayscale", "rgb", or "rgba"')
return T.Compose([
T.Resize(self.image_size)
] + transforms)(img) def __getitem__(self, idx):
"""
返回 image, label
"""
train_image = self._load_img(self.train_images[idx],
transforms=[
T.Transpose(),
T.Normalize(mean=127.5, std=127.5)
]) # 加载原始图像
label_image = self._load_img(self.label_images[idx],
color_mode='grayscale',
transforms=[T.Grayscale()]) # 加载Label图像
# 返回image, label
train_image = np.array(train_image, dtype='float32')
label_image = np.array(label_image, dtype='int64') return train_image, label_image
def __len__(self):
"""
返回数据集总数
"""
return len(self.train_images)class conv_block(nn.Layer):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU(),
nn.Conv2D(ch_out, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
) def forward(self, x):
x = self.conv(x) return xclass up_conv(nn.Layer):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
) def forward(self, x):
x = self.up(x) return xclass single_conv(nn.Layer):
def __init__(self, ch_in, ch_out):
super(single_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2D(ch_in, ch_out, kernel_size=3, stride=1, padding=1),
nn.BatchNorm(ch_out),
nn.ReLU()
) def forward(self, x):
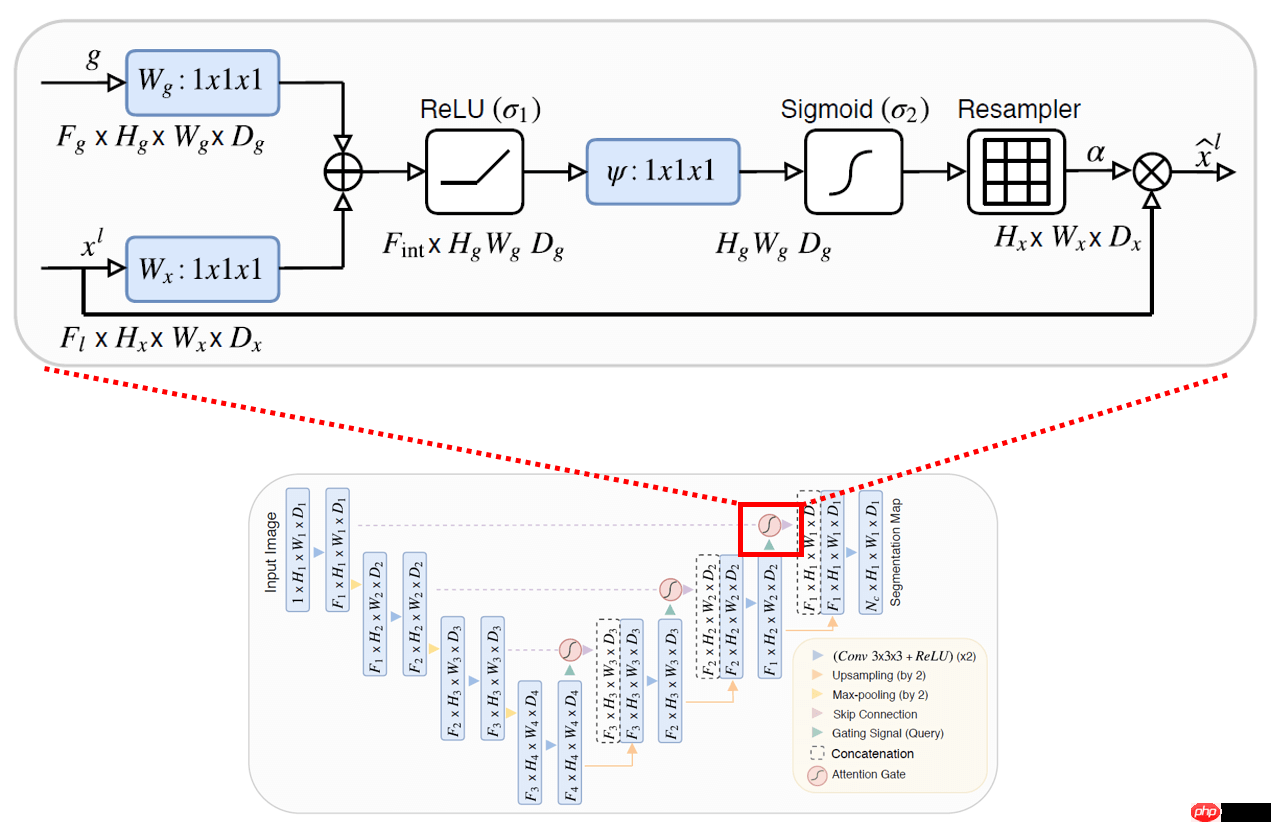
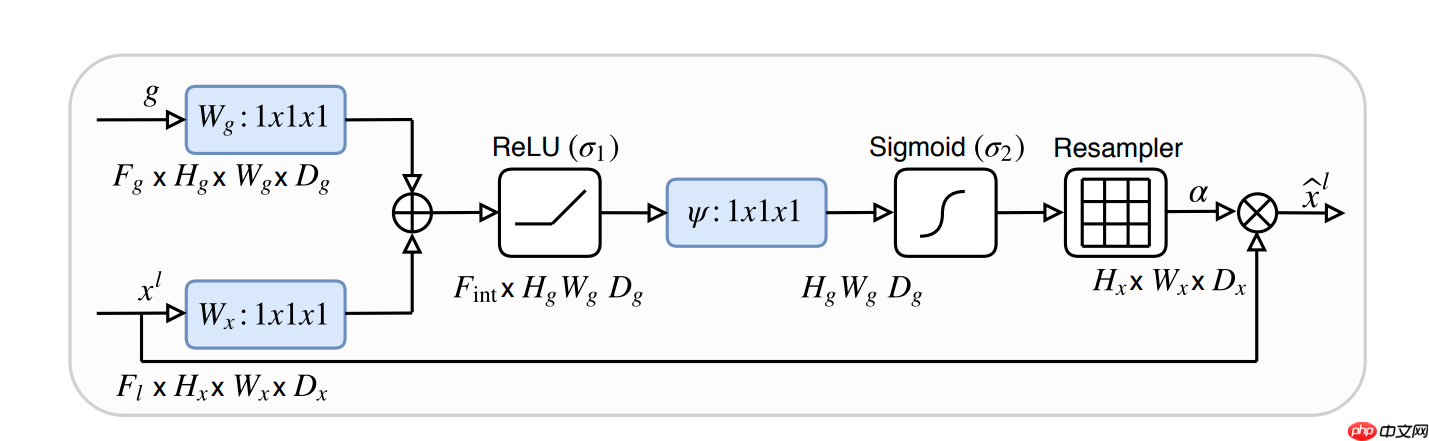
x = self.conv(x) return xclass Attention_block(nn.Layer):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2D(F_g, F_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2D(F_l, F_int, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(F_int)
)
self.psi = nn.Sequential(
nn.Conv2D(F_int, 1, kernel_size=1, stride=1, padding=0),
nn.BatchNorm(1),
nn.Sigmoid()
)
self.relu = nn.ReLU() def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi) return x * psiclass AttU_Net(nn.Layer):
def __init__(self, img_ch=3, output_ch=1):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Maxpool3 = nn.MaxPool2D(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2D(64, output_ch, kernel_size=1, stride=1, padding=0) def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool1(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool2(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool3(x4)
x5 = self.Conv5(x5) # decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = paddle.concat(x=[x4, d5], axis=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = paddle.concat(x=[x3, d4], axis=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = paddle.concat(x=[x2, d3], axis=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = paddle.concat(x=[x1, d2], axis=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2) return d1num_classes = 4network = AttU_Net(img_ch=3, output_ch=num_classes) model = paddle.Model(network) model.summary((-1, 3,) + IMAGE_SIZE)
-----------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=============================================================================
Conv2D-1 [[1, 3, 160, 160]] [1, 64, 160, 160] 1,792
BatchNorm-1 [[1, 64, 160, 160]] [1, 64, 160, 160] 256
ReLU-1 [[1, 64, 160, 160]] [1, 64, 160, 160] 0
Conv2D-2 [[1, 64, 160, 160]] [1, 64, 160, 160] 36,928
BatchNorm-2 [[1, 64, 160, 160]] [1, 64, 160, 160] 256
ReLU-2 [[1, 64, 160, 160]] [1, 64, 160, 160] 0
conv_block-1 [[1, 3, 160, 160]] [1, 64, 160, 160] 0
MaxPool2D-1 [[1, 64, 160, 160]] [1, 64, 80, 80] 0
Conv2D-3 [[1, 64, 80, 80]] [1, 128, 80, 80] 73,856
BatchNorm-3 [[1, 128, 80, 80]] [1, 128, 80, 80] 512
ReLU-3 [[1, 128, 80, 80]] [1, 128, 80, 80] 0
Conv2D-4 [[1, 128, 80, 80]] [1, 128, 80, 80] 147,584
BatchNorm-4 [[1, 128, 80, 80]] [1, 128, 80, 80] 512
ReLU-4 [[1, 128, 80, 80]] [1, 128, 80, 80] 0
conv_block-2 [[1, 64, 80, 80]] [1, 128, 80, 80] 0
MaxPool2D-2 [[1, 128, 80, 80]] [1, 128, 40, 40] 0
Conv2D-5 [[1, 128, 40, 40]] [1, 256, 40, 40] 295,168
BatchNorm-5 [[1, 256, 40, 40]] [1, 256, 40, 40] 1,024
ReLU-5 [[1, 256, 40, 40]] [1, 256, 40, 40] 0
Conv2D-6 [[1, 256, 40, 40]] [1, 256, 40, 40] 590,080
BatchNorm-6 [[1, 256, 40, 40]] [1, 256, 40, 40] 1,024
ReLU-6 [[1, 256, 40, 40]] [1, 256, 40, 40] 0
conv_block-3 [[1, 128, 40, 40]] [1, 256, 40, 40] 0
MaxPool2D-3 [[1, 256, 40, 40]] [1, 256, 20, 20] 0
Conv2D-7 [[1, 256, 20, 20]] [1, 512, 20, 20] 1,180,160
BatchNorm-7 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,048
ReLU-7 [[1, 512, 20, 20]] [1, 512, 20, 20] 0
Conv2D-8 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,359,808
BatchNorm-8 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,048
ReLU-8 [[1, 512, 20, 20]] [1, 512, 20, 20] 0
conv_block-4 [[1, 256, 20, 20]] [1, 512, 20, 20] 0
MaxPool2D-4 [[1, 512, 20, 20]] [1, 512, 10, 10] 0
Conv2D-9 [[1, 512, 10, 10]] [1, 1024, 10, 10] 4,719,616
BatchNorm-9 [[1, 1024, 10, 10]] [1, 1024, 10, 10] 4,096
ReLU-9 [[1, 1024, 10, 10]] [1, 1024, 10, 10] 0
Conv2D-10 [[1, 1024, 10, 10]] [1, 1024, 10, 10] 9,438,208
BatchNorm-10 [[1, 1024, 10, 10]] [1, 1024, 10, 10] 4,096
ReLU-10 [[1, 1024, 10, 10]] [1, 1024, 10, 10] 0
conv_block-5 [[1, 512, 10, 10]] [1, 1024, 10, 10] 0
Upsample-1 [[1, 1024, 10, 10]] [1, 1024, 20, 20] 0
Conv2D-11 [[1, 1024, 20, 20]] [1, 512, 20, 20] 4,719,104
BatchNorm-11 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,048
ReLU-11 [[1, 512, 20, 20]] [1, 512, 20, 20] 0
up_conv-1 [[1, 1024, 10, 10]] [1, 512, 20, 20] 0
Conv2D-12 [[1, 512, 20, 20]] [1, 256, 20, 20] 131,328
BatchNorm-12 [[1, 256, 20, 20]] [1, 256, 20, 20] 1,024
Conv2D-13 [[1, 512, 20, 20]] [1, 256, 20, 20] 131,328
BatchNorm-13 [[1, 256, 20, 20]] [1, 256, 20, 20] 1,024
ReLU-12 [[1, 256, 20, 20]] [1, 256, 20, 20] 0
Conv2D-14 [[1, 256, 20, 20]] [1, 1, 20, 20] 257
BatchNorm-14 [[1, 1, 20, 20]] [1, 1, 20, 20] 4
Sigmoid-1 [[1, 1, 20, 20]] [1, 1, 20, 20] 0
Attention_block-1 [] [1, 512, 20, 20] 0
Conv2D-15 [[1, 1024, 20, 20]] [1, 512, 20, 20] 4,719,104
BatchNorm-15 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,048
ReLU-13 [[1, 512, 20, 20]] [1, 512, 20, 20] 0
Conv2D-16 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,359,808
BatchNorm-16 [[1, 512, 20, 20]] [1, 512, 20, 20] 2,048
ReLU-14 [[1, 512, 20, 20]] [1, 512, 20, 20] 0
conv_block-6 [[1, 1024, 20, 20]] [1, 512, 20, 20] 0
Upsample-2 [[1, 512, 20, 20]] [1, 512, 40, 40] 0
Conv2D-17 [[1, 512, 40, 40]] [1, 256, 40, 40] 1,179,904
BatchNorm-17 [[1, 256, 40, 40]] [1, 256, 40, 40] 1,024
ReLU-15 [[1, 256, 40, 40]] [1, 256, 40, 40] 0
up_conv-2 [[1, 512, 20, 20]] [1, 256, 40, 40] 0
Conv2D-18 [[1, 256, 40, 40]] [1, 128, 40, 40] 32,896
BatchNorm-18 [[1, 128, 40, 40]] [1, 128, 40, 40] 512
Conv2D-19 [[1, 256, 40, 40]] [1, 128, 40, 40] 32,896
BatchNorm-19 [[1, 128, 40, 40]] [1, 128, 40, 40] 512
ReLU-16 [[1, 128, 40, 40]] [1, 128, 40, 40] 0
Conv2D-20 [[1, 128, 40, 40]] [1, 1, 40, 40] 129
BatchNorm-20 [[1, 1, 40, 40]] [1, 1, 40, 40] 4
Sigmoid-2 [[1, 1, 40, 40]] [1, 1, 40, 40] 0
Attention_block-2 [] [1, 256, 40, 40] 0
Conv2D-21 [[1, 512, 40, 40]] [1, 256, 40, 40] 1,179,904
BatchNorm-21 [[1, 256, 40, 40]] [1, 256, 40, 40] 1,024
ReLU-17 [[1, 256, 40, 40]] [1, 256, 40, 40] 0
Conv2D-22 [[1, 256, 40, 40]] [1, 256, 40, 40] 590,080
BatchNorm-22 [[1, 256, 40, 40]] [1, 256, 40, 40] 1,024
ReLU-18 [[1, 256, 40, 40]] [1, 256, 40, 40] 0
conv_block-7 [[1, 512, 40, 40]] [1, 256, 40, 40] 0
Upsample-3 [[1, 256, 40, 40]] [1, 256, 80, 80] 0
Conv2D-23 [[1, 256, 80, 80]] [1, 128, 80, 80] 295,040
BatchNorm-23 [[1, 128, 80, 80]] [1, 128, 80, 80] 512
ReLU-19 [[1, 128, 80, 80]] [1, 128, 80, 80] 0
up_conv-3 [[1, 256, 40, 40]] [1, 128, 80, 80] 0
Conv2D-24 [[1, 128, 80, 80]] [1, 64, 80, 80] 8,256
BatchNorm-24 [[1, 64, 80, 80]] [1, 64, 80, 80] 256
Conv2D-25 [[1, 128, 80, 80]] [1, 64, 80, 80] 8,256
BatchNorm-25 [[1, 64, 80, 80]] [1, 64, 80, 80] 256
ReLU-20 [[1, 64, 80, 80]] [1, 64, 80, 80] 0
Conv2D-26 [[1, 64, 80, 80]] [1, 1, 80, 80] 65
BatchNorm-26 [[1, 1, 80, 80]] [1, 1, 80, 80] 4
Sigmoid-3 [[1, 1, 80, 80]] [1, 1, 80, 80] 0
Attention_block-3 [] [1, 128, 80, 80] 0
Conv2D-27 [[1, 256, 80, 80]] [1, 128, 80, 80] 295,040
BatchNorm-27 [[1, 128, 80, 80]] [1, 128, 80, 80] 512
ReLU-21 [[1, 128, 80, 80]] [1, 128, 80, 80] 0
Conv2D-28 [[1, 128, 80, 80]] [1, 128, 80, 80] 147,584
BatchNorm-28 [[1, 128, 80, 80]] [1, 128, 80, 80] 512
ReLU-22 [[1, 128, 80, 80]] [1, 128, 80, 80] 0
conv_block-8 [[1, 256, 80, 80]] [1, 128, 80, 80] 0
Upsample-4 [[1, 128, 80, 80]] [1, 128, 160, 160] 0
Conv2D-29 [[1, 128, 160, 160]] [1, 64, 160, 160] 73,792
BatchNorm-29 [[1, 64, 160, 160]] [1, 64, 160, 160] 256
ReLU-23 [[1, 64, 160, 160]] [1, 64, 160, 160] 0
up_conv-4 [[1, 128, 80, 80]] [1, 64, 160, 160] 0
Conv2D-30 [[1, 64, 160, 160]] [1, 32, 160, 160] 2,080
BatchNorm-30 [[1, 32, 160, 160]] [1, 32, 160, 160] 128
Conv2D-31 [[1, 64, 160, 160]] [1, 32, 160, 160] 2,080
BatchNorm-31 [[1, 32, 160, 160]] [1, 32, 160, 160] 128
ReLU-24 [[1, 32, 160, 160]] [1, 32, 160, 160] 0
Conv2D-32 [[1, 32, 160, 160]] [1, 1, 160, 160] 33
BatchNorm-32 [[1, 1, 160, 160]] [1, 1, 160, 160] 4
Sigmoid-4 [[1, 1, 160, 160]] [1, 1, 160, 160] 0
Attention_block-4 [] [1, 64, 160, 160] 0
Conv2D-33 [[1, 128, 160, 160]] [1, 64, 160, 160] 73,792
BatchNorm-33 [[1, 64, 160, 160]] [1, 64, 160, 160] 256
ReLU-25 [[1, 64, 160, 160]] [1, 64, 160, 160] 0
Conv2D-34 [[1, 64, 160, 160]] [1, 64, 160, 160] 36,928
BatchNorm-34 [[1, 64, 160, 160]] [1, 64, 160, 160] 256
ReLU-26 [[1, 64, 160, 160]] [1, 64, 160, 160] 0
conv_block-9 [[1, 128, 160, 160]] [1, 64, 160, 160] 0
Conv2D-35 [[1, 64, 160, 160]] [1, 4, 160, 160] 260
=============================================================================
Total params: 34,894,392
Trainable params: 34,863,144
Non-trainable params: 31,248
-----------------------------------------------------------------------------
Input size (MB): 0.29
Forward/backward pass size (MB): 563.67
Params size (MB): 133.11
Estimated Total Size (MB): 697.07
-----------------------------------------------------------------------------{'total_params': 34894392, 'trainable_params': 34863144}train_dataset = PetDataset(mode='train') # 训练数据集val_dataset = PetDataset(mode='test') # 验证数据集optim = paddle.optimizer.RMSProp(learning_rate=0.001,
rho=0.9,
momentum=0.0,
epsilon=1e-07,
centered=False,
parameters=model.parameters())
model.prepare(optim, paddle.nn.CrossEntropyLoss(axis=1))
model.fit(train_dataset,
val_dataset,
epochs=15,
batch_size=32,
verbose=1)predict_dataset = PetDataset(mode='predict') predict_results = model.predict(predict_dataset)
Predict begin... step 1108/1108 [==============================] - 20ms/step Predict samples: 1108
plt.figure(figsize=(10, 10))
i = 0mask_idx = 0with open('./predict.txt', 'r') as f: for line in f.readlines():
image_path, label_path = line.strip().split('\t')
resize_t = T.Compose([
T.Resize(IMAGE_SIZE)
])
image = resize_t(PilImage.open(image_path))
label = resize_t(PilImage.open(label_path))
image = np.array(image).astype('uint8')
label = np.array(label).astype('uint8') if i > 8:
break
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.title('Input Image')
plt.axis("off")
plt.subplot(3, 3, i + 2)
plt.imshow(label, cmap='gray')
plt.title('Label')
plt.axis("off")
# 模型只有一个输出,通过predict_results[0]来取出1000个预测的结果
# 映射原始图片的index来取出预测结果,提取mask进行展示
data = predict_results[0][mask_idx][0].transpose((1, 2, 0))
mask = np.argmax(data, axis=-1)
plt.subplot(3, 3, i + 3)
plt.imshow(mask.astype('uint8'), cmap='gray')
plt.title('Predict')
plt.axis("off")
i += 3
mask_idx += 1plt.show()<Figure size 720x720 with 9 Axes>
以上就是基于Attention U-Net的宠物图像分割的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 392
392




















