本文围绕波士顿房价预测实验展开,介绍实验目的为掌握前馈神经网络相关知识及飞桨框架使用。实验使用波士顿房价数据集,经数据准备、模型构建、训练配置等步骤,构建前馈神经网络,用MSE损失函数和Adam优化器训练,通过R²系数评估,最终实现房价预测。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

在人类的生活中经常遇到分类与预测的问题,目标变量可能受多个因素影响,根据相关系数可以判断影响因子的重要性。房价的高低也是受多个因素影响的,如房子所处的城市是一线还是二线,房子周边交通方便程度如通不通地铁,房子周边学校和医院等,这些都影响了房子的价格。
本节实验将分析波士顿房价预测任务,这是学习人工智能课程的入门案例,本节结合前馈神经网络的理论知识,通过“波士顿房价预测”实验带领大家学习如何使用深度学习技术对回归任务进行建模。
本实验支持在实训平台或本地环境操作,建议使用实训平台。
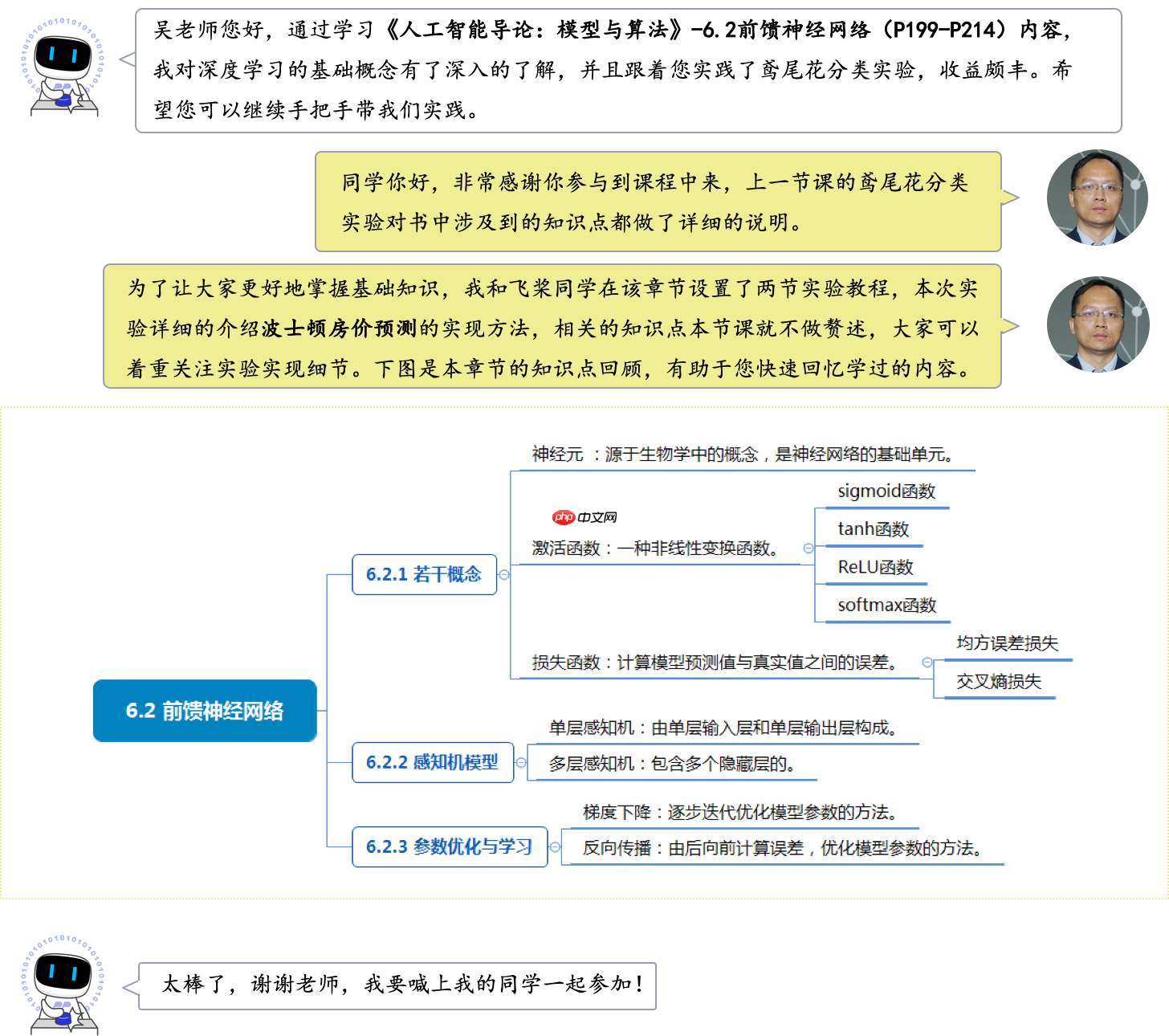
本实验的实现方案和鸢尾花分类实验的实现方案类似,构建一个简单的前馈神经网络模型,其结构如 图2 所示,对于一条输入数据,首先使用前馈神经网络提取特征,获取特征表示之后使用MSE损失函数计算真实值和预测值之间的误差,进行模型训练;在推理阶段,可直接使用模型的输出值作为最终的预测结果。
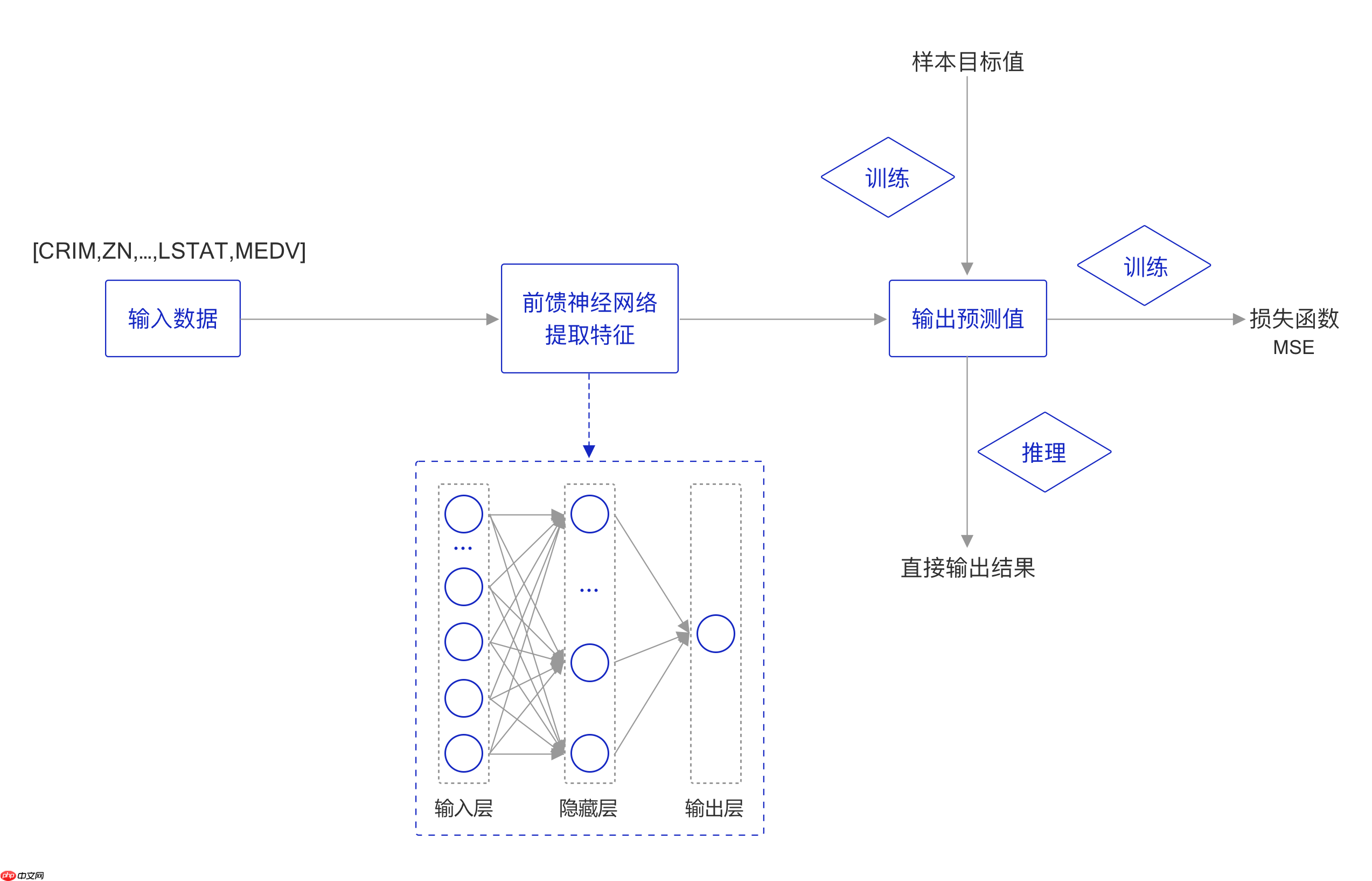
本次实验流程如 图3 所示,主要分为以下7个步骤:
本实验使用的训练数据集是经典学术数据集“波士顿房价”数据,使用飞桨核心框架构建自定义的前馈神经网络,实现房价预测的回归任务。
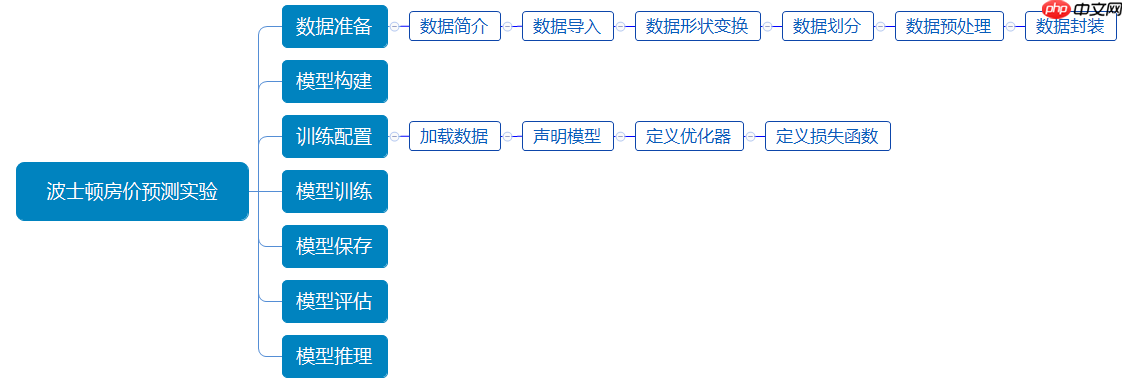
数据准备工作包含6个部分,如 图4 所示:

说明:
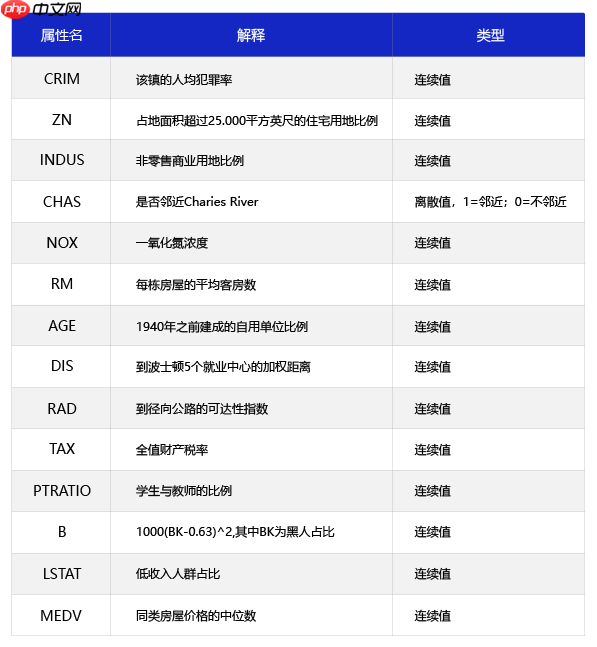
波士顿房价预测数据集来自 UCI 机器学习知识库(数据集已下线)。于1978年开始统计,数据集中的每一行数据都是对波士顿周边或城镇房价的情况描述,总共有 506 行,即 506 个样本,该数据集统计了 14 种可能影响房价的因素和该类型房屋的均价,期望构建一个基于14个因素进行房价预测的模型,如 图5 所示。
通过如下代码导入数据,了解下波士顿房价的数据集结构,数据存放在本地目录./work/datasets/housing.data文件中。
# coding=utf-8# 导入环境import osimport paddleimport randomimport numpy as npfrom sklearn.metrics import r2_score
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/layers/utils.py:26: DeprecationWarning: `np.int` is a deprecated alias for the builtin `int`. To silence this warning, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations def convert_to_list(value, n, name, dtype=np.int):
# 读入训练数据datafile = './work/datasets/housing.data'data = np.fromfile(datafile, sep=' ')print(data.shape)
(7084,)
由上一节可以看出读入的原始数据是1维的,即所有数据都连在一起。因此需要将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
# 读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推.... # 这里对原始数据做reshape,变成N x 14的形式feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE','DIS',
'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])# 查看数据x = data[0]print(x.shape)print(x)(14,) [6.320e-03 1.800e+01 2.310e+00 0.000e+00 5.380e-01 6.575e+00 6.520e+01 4.090e+00 1.000e+00 2.960e+02 1.530e+01 3.969e+02 4.980e+00 2.400e+01]
# 在这里我们简单地看一下每一项数据的分布import pandas as pdimport matplotlib.pyplot as plt data_df = pd.DataFrame(data, columns=feature_names) data_df.hist(layout=(7, 2), bins=30, figsize=(16, 30))# 可以看到部分数据分布极其不均, 在这一节我们尝试用神经网络进行拟合
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2349: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working if isinstance(obj, collections.Iterator): /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/cbook/__init__.py:2366: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working return list(data) if isinstance(data, collections.MappingView) else data
array([[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab11dad10>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab16456d0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab111c690>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab10c8f90>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab107c8d0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab107c910>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab10b0250>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab10106d0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab103be10>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab0ff06d0>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab0f9bf50>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab0f50890>],
[<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab0f031d0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x7f5ab0f2ead0>]],
dtype=object)将数据集划分成训练集和测试集,其中训练集用于确定模型的参数,测试集用于评判模型的效果。在本案例中,将80%的数据用作训练集,20%用作测试集,实现代码如下。通过打印训练集的形状,可以发现共有404个样本,每个样本含有13个特征和1个预测值。
ratio = 0.8offset = int(data.shape[0] * ratio)# 训练数据为80%training_data = data[:offset] training_data.shape
(404, 14)
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
# 计算train数据集的最大值,最小值,平均值maximums, minimums, avgs = \
training_data.max(axis=0), \
training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理for i in range(feature_num):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])为了便于模型的调用,将上述几个数据处理操作封装成 BHPData 类,实现方法如下。
class BHPData(object):
def __init__(self, data_path = './work/datasets/housing.data', ratio=0.8):
# 从文件导入数据
data = np.fromfile(data_path, sep=' ') # 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_num = 14
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num]) # 将原数据集拆分成训练集和测试集,80%的数据做训练,20%的数据做测试
offset = int(data.shape[0] * ratio) # 计算训练集的最大值,最小值,平均值
train_data = data[:offset]
maximums = train_data.max(axis=0)
minimums = train_data.min(axis=0)
avgs = train_data.sum(axis=0) / train_data.shape[0] # 记录数据的归一化参数,在预测时对数据做反归一化
global max_values global min_values global avg_values
max_values = maximums
min_values = minimums
avg_values = avgs
# 对数据进行归一化处理
for i in range(feature_num):
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) # 训练集和测试集的划分比例
data = data.astype(np.float32)
self.train_data = data[:offset]
self.test_data = data[offset:] def __call__(self, *args, **kwargs):
return self.train_data, self.test_datatrain_data, test_data = BHPData()()print(train_data.shape)print(train_data[1, :])print(test_data.shape)print(test_data[1, :])
(404, 14) [-0.02122729 -0.14232673 -0.09655922 -0.08663366 -0.12907805 0.0168406 0.14904763 0.0721009 -0.20824365 -0.23154674 -0.02406783 0.0519112 -0.06111894 -0.05723872] (102, 14) [ 0.74187917 -0.14232673 0.34131294 -0.08663366 0.3318273 -0.1245658 0.36634937 -0.2499626 0.7482781 0.65363073 0.23125131 0.01532733 0.3207795 -0.4261276 ]
接下来通过继承 paddle 的 Dataset API 来构建一个数据读取器,方便每次从数据中获取一个样本的属性和对应的标签。
# 创建数据读取器class Generate(paddle.io.Dataset):
def __init__(self, data):
super(Generate, self).__init__()
self.x = data[:, :-1]
self.y = data[:, -1:] def __getitem__(self, idx):
return self.x[idx], self.y[idx] def __len__(self):
return len(self.y)数据预处理耗时较长,推荐使用 paddle.io.DataLoader API中的 num_workers 参数,设置进程数量,实现多进程读取数据。
class paddle.io.DataLoader(dataset, batch_size=1, shuffle=False, num_workers=0)
关键参数含义如下:
通过 paddle.io.DataLoader 构建数据迭代器的代码如下:
train_data, test_data = BHPData()()
train_generate = Generate(data=train_data)
train_dataloader = paddle.io.DataLoader(train_generate,
batch_size=4,
shuffle=True)
test_generate = Generate(data=test_data)
test_dataloader = paddle.io.DataLoader(test_generate, batch_size=4)for data in train_dataloader():
x, y = data print(x, y) break/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):
Tensor(shape=[4, 13], dtype=float32, place=CUDAPinnedPlace, stop_gradient=True,
[[-0.02128843, 0.45767328, -0.26091015, -0.08663366, -0.26899573, 0.08945987, -0.56155998, 0.18599664, -0.25172192, -0.18353005, -0.25811037, 0.04108630, -0.17452954],
[-0.02072892, -0.14232673, 0.64103508, -0.08663366, 0.10137463, -0.06305976, 0.20260067, -0.17976099, -0.20824365, -0.34428161, 0.11423004, -0.00705844, 0.08043735],
[-0.02042724, -0.14232673, 0.64103508, -0.08663366, 0.10137463, -0.08701071, 0.32309499, -0.19713861, -0.20824365, -0.34428161, 0.11423004, -0.00181465, 0.17177288],
[-0.02041027, 0.19767326, -0.13546355, -0.08663366, -0.20315212, 0.12433246, -0.48123044, 0.11980525, 0.00914765, -0.04991835, -0.20491889, 0.03207066, -0.17922048]]) Tensor(shape=[4, 1], dtype=float32, place=CUDAPinnedPlace, stop_gradient=True,
[[ 0.15387239],
[-0.08612762],
[-0.11946095],
[ 0.19831683]])至此,完成了数据准备的相关工作,通过 paddle.io.Dataset 可以返回数据和标签信息,接下来将处理好的数据输入到神经网络,应用到具体算法上。
数据集准备完成,接下来需要设计训练模型,本实验构建的是简单的前馈神经网络,结构如 图7 所示:
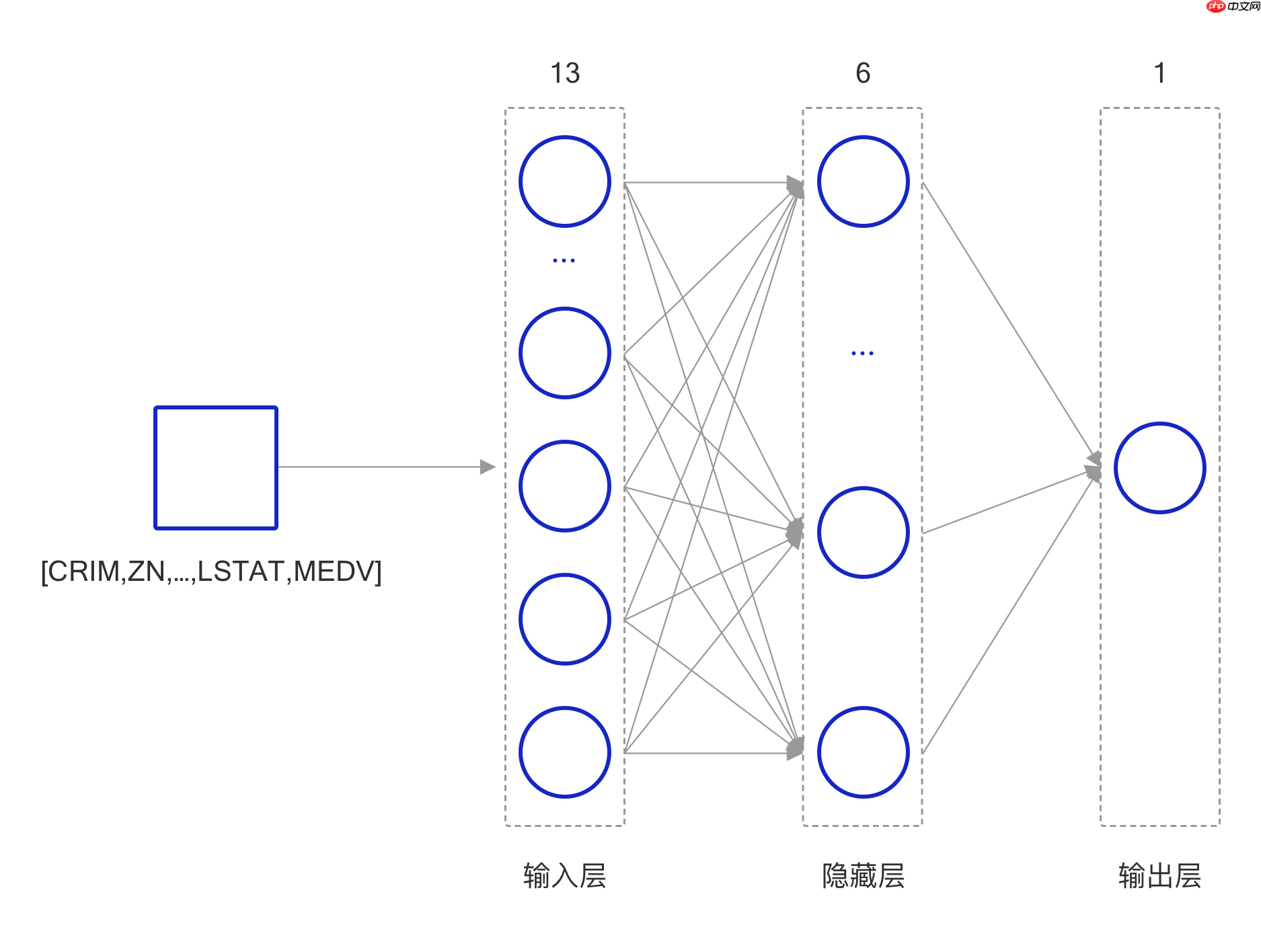
这里构建一个简单的前馈神经网络,该网络由输入层、隐藏层以及输出层构成。
由于波士顿数据集中的波士顿房价由13种因素影响,因此输入层由13个神经元构成。隐藏层由 6 个神经元组成,其中每个神经元只接收来自输入层的 13 个属性信息,经过 sigmoid 激活函数之后将信息传递给输出层,最后输出层输出预测结果。
说明:
神经元模型是神经网络中最基本的组成成分,这一概念来源于生物神经网络中,通过电位变化表示“兴奋”的生物神经元。在深度学习领域,一个神经元其实是一个计算单元。每层神经元只和相邻神经元相连,即每层神经元只接收相邻前序神经网络中神经元所传来的信息,只给相邻的后续神经层中的神经元传递信息。在前馈神经网络中,同一层的神经元之间没有任何连接。
神经网络中使用非线性函数作为激活函数,通过对多个非线性函数进行组合,实现对输入信息的非线性变换。
这里使用飞桨构建网络,在飞桨中可以使用 Layer 子类定义的方式来进行代码编写,方便复用,子类中包含两个函数:
定义的网络结构如下:
# 定义多层前馈神经网络class SingleFC(paddle.nn.Layer):
def __init__(self):
super(SingleFC, self).__init__() # 构建第一个全连接层,输入单元13个,输出单元6个
self.fc1 = paddle.nn.Linear(
in_features=13,
out_features=6,
weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(mean=0.0, std=0.01)),
bias_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(value=1.0))
) # 构建第二全连接层,输入单元6个,输出单元1个
self.fc2 = paddle.nn.Linear(
in_features=6,
out_features=1,
weight_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Normal(mean=0.0, std=0.01)),
bias_attr=paddle.ParamAttr(initializer=paddle.nn.initializer.Constant(value=1.0))
) # 定义网络使用的激活函数
self.act = paddle.nn.Sigmoid() def forward(self, inputs):
outputs = self.fc1(inputs)
outputs = self.act(outputs)
outputs = self.fc2(outputs) return outputs在定义上述网络结构的过程中,使用了飞桨中的如下 API:
class paddle.nn.Linear(in_features, out_features, weight_attr=None, bias_attr=None, name=None)
关键参数含义如下:
class paddle.nn.Sigmoid(name=None)
关键参数含义如下:
说明:
熟练掌握飞桨API的使用方法,是使用飞桨完成各类深度学习任务的基础,也是开发者必须掌握的技能。登录“飞桨官网->文档->API文档”,可以获取飞桨API文档。
lr = 0.003 # 学习率大小batch_size = 32 # 批次大小## 1. 加载数据# 获取波士顿房价预测任务的训练集和测试集train_data, test_data = BHPData()()# 构建训练数据迭代器train_generate = Generate(data=train_data) train_dataloader = paddle.io.DataLoader(train_generate, batch_size=batch_size, shuffle=True)# 构建测试数据迭代器test_generate = Generate(data=test_data) test_dataloader = paddle.io.DataLoader(test_generate, batch_size=batch_size)## 2. 定义网络model = SingleFC()## 3. 定义优化器# 定义优化器,这里使用 Adam 优化器# opt = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters(), weight_decay=paddle.regularizer.L2Decay(coeff=1e-5))opt = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters())## 4. 定义损失函数# 定义损失函数,这里使用均方差损失函数loss_fn = paddle.nn.MSELoss()
W0505 14:12:54.200083 4059 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W0505 14:12:54.205361 4059 device_context.cc:372] device: 0, cuDNN Version: 7.6.
说明:
均方误差损失函数通过计算预测值和实际值之间距离(即误差)的平方来衡量模型优劣。假设有 n 个训练数据 xi,每个训练数据 xi 的真实输出为 yi,模型对 xi 的预测值为 y^i。该模型在 n 个训练数据下所产生的均方误差损失可定义如下:
MSE=n1i=1∑n(yi−y^i)2
本次实验总共训练 10 个epoch,每个 epoch 都需要在训练集与测试集上运行,并打印出训练集和验证集上的 loss ,并且每一轮训练完成之后都对模型进行保存。
class Trainer(object):
def __init__(self, model, optimizer, loss_fn):
# 模型实例
self.model = model
# 优化器
self.optimizer = optimizer
# 损失函数
self.loss_fn = loss_fn
def save(self, epoch):
model_path = os.path.join('bhp_{}.pdparams'.format(epoch))
opt_path = os.path.join('bhp_{}.pdopt'.format(epoch))
paddle.save(self.model.state_dict(), model_path)
paddle.save(self.optimizer.state_dict(), opt_path) def train_step(self, data):
x, y = data # 获取模型预测
pred = self.model(x)
# 计算损失
loss = self.loss_fn(pred, y)
# 计算损失均值
avg_loss = paddle.mean(loss)
avg_loss.backward()
self.optimizer.step()
self.optimizer.clear_grad() return avg_loss def train_epoch(self, dataloader, epoch):
self.model.train()
# 将模型设置为训练状态
for i, data in enumerate(dataloader()): # 训练每一个批次
loss = self.train_step(data)
def val_epoch(self, dataloader):
# 将模型设置为评估状态
self.model.eval()
error_list = list() for i, data in enumerate(dataloader()):
x, y = data # 获取模型预测
pred = self.model(x)
# 计算损失
res = self.loss_fn(pred, y)
res = paddle.cast(res, dtype='float32') # 追加
error_list.extend(res.numpy())
# 计算平均误差
error = np.array(error_list).mean()
return error def train(self, epochs, train_dataloader, test_dataloader):
for i in range(epochs): # 训练每个 epoch
self.train_epoch(train_dataloader, i)
# 计算训练集平均误差
train_error = self.val_epoch(train_dataloader) # 计算测试集平均误差
test_error = self.val_epoch(test_dataloader) print('epoch is {}, train error is {}, test error is {}'.format(i, train_error, test_error)) # 保存模型
self.save(i)epoch = 150 # 模型训练的轮数设置为40# 实例化训练器trainer = Trainer(model=model, optimizer=opt, loss_fn=loss_fn)# 启动训练trainer.train(epoch, train_dataloader, test_dataloader)
epoch is 0, train error is 0.599963366985321, test error is 0.8426924347877502 epoch is 1, train error is 0.33809980750083923, test error is 0.5098757743835449 epoch is 2, train error is 0.17354761064052582, test error is 0.2805306315422058 epoch is 3, train error is 0.0864136666059494, test error is 0.14261744916439056 epoch is 4, train error is 0.04885997623205185, test error is 0.07059898972511292 epoch is 5, train error is 0.03657462075352669, test error is 0.03762945532798767 epoch is 6, train error is 0.032262854278087616, test error is 0.024152085185050964 epoch is 7, train error is 0.03038971871137619, test error is 0.018659504130482674 epoch is 8, train error is 0.028899066150188446, test error is 0.01620791107416153 epoch is 9, train error is 0.02862655743956566, test error is 0.015054404735565186 epoch is 10, train error is 0.02913896180689335, test error is 0.013866808265447617 epoch is 11, train error is 0.026866454631090164, test error is 0.013537761755287647 epoch is 12, train error is 0.025524267926812172, test error is 0.012757524847984314 epoch is 13, train error is 0.024874139577150345, test error is 0.012315462343394756 epoch is 14, train error is 0.025137420743703842, test error is 0.011885158717632294 epoch is 15, train error is 0.02358795888721943, test error is 0.01119577419012785 epoch is 16, train error is 0.022790081799030304, test error is 0.010653355158865452 epoch is 17, train error is 0.022963110357522964, test error is 0.010220974683761597 epoch is 18, train error is 0.02160964533686638, test error is 0.01010782178491354 epoch is 19, train error is 0.021636109799146652, test error is 0.009703177027404308 epoch is 20, train error is 0.02079329825937748, test error is 0.009529443457722664 epoch is 21, train error is 0.020228423178195953, test error is 0.00952425692230463 epoch is 22, train error is 0.0202083270996809, test error is 0.009253574535250664 epoch is 23, train error is 0.01902635209262371, test error is 0.008858736604452133 epoch is 24, train error is 0.019779609516263008, test error is 0.008941514417529106 epoch is 25, train error is 0.01850392110645771, test error is 0.008752807043492794 epoch is 26, train error is 0.018656877800822258, test error is 0.008564372546970844 epoch is 27, train error is 0.017408136278390884, test error is 0.008398843929171562 epoch is 28, train error is 0.017972571775317192, test error is 0.008234277367591858 epoch is 29, train error is 0.01699184440076351, test error is 0.00824739970266819 epoch is 30, train error is 0.016450442373752594, test error is 0.008105671033263206 epoch is 31, train error is 0.01594175398349762, test error is 0.007849451154470444 epoch is 32, train error is 0.015696382150053978, test error is 0.007852842099964619 epoch is 33, train error is 0.015313193202018738, test error is 0.0077778794802725315 epoch is 34, train error is 0.015577143989503384, test error is 0.007714115083217621 epoch is 35, train error is 0.014684191904962063, test error is 0.007547477260231972 epoch is 36, train error is 0.01464575994759798, test error is 0.007467261981219053 epoch is 37, train error is 0.014231939800083637, test error is 0.007276446558535099 epoch is 38, train error is 0.014693371020257473, test error is 0.0074542369693517685 epoch is 39, train error is 0.01369321160018444, test error is 0.007212171331048012 epoch is 40, train error is 0.013488874770700932, test error is 0.007128127384930849 epoch is 41, train error is 0.013302985578775406, test error is 0.007069620303809643 epoch is 42, train error is 0.01309875212609768, test error is 0.006914699450135231 epoch is 43, train error is 0.013648565858602524, test error is 0.006964618340134621 epoch is 44, train error is 0.012945810332894325, test error is 0.00689729955047369 epoch is 45, train error is 0.012512827292084694, test error is 0.006765847560018301 epoch is 46, train error is 0.012344107031822205, test error is 0.006752694025635719 epoch is 47, train error is 0.012566853314638138, test error is 0.006674342788755894 epoch is 48, train error is 0.01238404680043459, test error is 0.006759702693670988 epoch is 49, train error is 0.011963210068643093, test error is 0.006513678468763828 epoch is 50, train error is 0.011829029768705368, test error is 0.006576716899871826 epoch is 51, train error is 0.012480816803872585, test error is 0.006711541675031185 epoch is 52, train error is 0.011524318717420101, test error is 0.0065663764253258705 epoch is 53, train error is 0.011767768301069736, test error is 0.006488143466413021 epoch is 54, train error is 0.011314027942717075, test error is 0.0063834888860583305 epoch is 55, train error is 0.011330046691000462, test error is 0.0064504509791731834 epoch is 56, train error is 0.011437342502176762, test error is 0.00652934517711401 epoch is 57, train error is 0.01096153911203146, test error is 0.006485152058303356 epoch is 58, train error is 0.010843802243471146, test error is 0.006537457928061485 epoch is 59, train error is 0.010733425617218018, test error is 0.006397902965545654 epoch is 60, train error is 0.010750968009233475, test error is 0.006448397878557444 epoch is 61, train error is 0.010654319077730179, test error is 0.006545177195221186 epoch is 62, train error is 0.010641138069331646, test error is 0.006431879010051489 epoch is 63, train error is 0.010702414438128471, test error is 0.006383201573044062 epoch is 64, train error is 0.010693429037928581, test error is 0.0066276174038648605 epoch is 65, train error is 0.01061268337070942, test error is 0.006604975555092096 epoch is 66, train error is 0.01019358728080988, test error is 0.006642032414674759 epoch is 67, train error is 0.010240346193313599, test error is 0.006903493776917458 epoch is 68, train error is 0.01010087039321661, test error is 0.006634954363107681 epoch is 69, train error is 0.010075286962091923, test error is 0.00654292106628418 epoch is 70, train error is 0.010370890609920025, test error is 0.006924394518136978 epoch is 71, train error is 0.010067077353596687, test error is 0.00691407173871994 epoch is 72, train error is 0.009950746782124043, test error is 0.006728621199727058 epoch is 73, train error is 0.010253815911710262, test error is 0.0069692423567175865 epoch is 74, train error is 0.009924779646098614, test error is 0.00686108972877264 epoch is 75, train error is 0.009849654510617256, test error is 0.00717760156840086 epoch is 76, train error is 0.00988010037690401, test error is 0.006960241124033928 epoch is 77, train error is 0.009678185917437077, test error is 0.007125238887965679 epoch is 78, train error is 0.009605849161744118, test error is 0.007260611280798912 epoch is 79, train error is 0.009793161414563656, test error is 0.007028559222817421 epoch is 80, train error is 0.00965217687189579, test error is 0.007394989486783743 epoch is 81, train error is 0.009604934602975845, test error is 0.007633998990058899 epoch is 82, train error is 0.00951390154659748, test error is 0.007243459112942219 epoch is 83, train error is 0.009534905664622784, test error is 0.007501265034079552 epoch is 84, train error is 0.009721447713673115, test error is 0.007445911876857281 epoch is 85, train error is 0.009561392478644848, test error is 0.007831376977264881 epoch is 86, train error is 0.010300512425601482, test error is 0.0075280386954545975 epoch is 87, train error is 0.00958352629095316, test error is 0.00777842290699482 epoch is 88, train error is 0.01072693895548582, test error is 0.00827138964086771 epoch is 89, train error is 0.009930072352290154, test error is 0.00801372155547142 epoch is 90, train error is 0.009442511945962906, test error is 0.007989486679434776 epoch is 91, train error is 0.009330598637461662, test error is 0.008058872073888779 epoch is 92, train error is 0.009473074227571487, test error is 0.008141078986227512 epoch is 93, train error is 0.009439191780984402, test error is 0.008543258532881737 epoch is 94, train error is 0.009346096776425838, test error is 0.00818675197660923 epoch is 95, train error is 0.009339812211692333, test error is 0.008142609149217606 epoch is 96, train error is 0.009184868074953556, test error is 0.008209834806621075 epoch is 97, train error is 0.009192023426294327, test error is 0.008473049849271774 epoch is 98, train error is 0.00940775778144598, test error is 0.009201787412166595 epoch is 99, train error is 0.009219285100698471, test error is 0.008753028698265553 epoch is 100, train error is 0.009256680496037006, test error is 0.008449957706034184 epoch is 101, train error is 0.009189369156956673, test error is 0.009115401655435562 epoch is 102, train error is 0.009441361762583256, test error is 0.008994992822408676 epoch is 103, train error is 0.0095262061804533, test error is 0.009081844240427017 epoch is 104, train error is 0.009209765121340752, test error is 0.008994463831186295 epoch is 105, train error is 0.009223194792866707, test error is 0.00882701762020588 epoch is 106, train error is 0.009170174598693848, test error is 0.009324111975729465 epoch is 107, train error is 0.009193419478833675, test error is 0.009253758937120438 epoch is 108, train error is 0.009091896936297417, test error is 0.00976922269910574 epoch is 109, train error is 0.009573767893016338, test error is 0.009716514497995377 epoch is 110, train error is 0.009480045177042484, test error is 0.009336842224001884 epoch is 111, train error is 0.009601003490388393, test error is 0.009362908080220222 epoch is 112, train error is 0.009096958674490452, test error is 0.008994433097541332 epoch is 113, train error is 0.009103701449930668, test error is 0.010191493667662144 epoch is 114, train error is 0.00905767921358347, test error is 0.009461130015552044 epoch is 115, train error is 0.00944032333791256, test error is 0.009980068542063236 epoch is 116, train error is 0.008994565345346928, test error is 0.009975654073059559 epoch is 117, train error is 0.009057198651134968, test error is 0.00977921299636364 epoch is 118, train error is 0.008943511173129082, test error is 0.009862364269793034 epoch is 119, train error is 0.009014508686959743, test error is 0.009694363921880722 epoch is 120, train error is 0.009022625163197517, test error is 0.010179572738707066 epoch is 121, train error is 0.008987467736005783, test error is 0.00953140202909708 epoch is 122, train error is 0.009381490759551525, test error is 0.009843004867434502 epoch is 123, train error is 0.008944964967668056, test error is 0.010047188960015774 epoch is 124, train error is 0.008994393050670624, test error is 0.009673993103206158 epoch is 125, train error is 0.008988423272967339, test error is 0.010246098041534424 epoch is 126, train error is 0.009040430188179016, test error is 0.009910888969898224 epoch is 127, train error is 0.00895601138472557, test error is 0.01015312597155571 epoch is 128, train error is 0.008882192894816399, test error is 0.009992312639951706 epoch is 129, train error is 0.008902640081942081, test error is 0.009837262332439423 epoch is 130, train error is 0.009032582864165306, test error is 0.010566397570073605 epoch is 131, train error is 0.008877186104655266, test error is 0.009863805957138538 epoch is 132, train error is 0.008912201039493084, test error is 0.010056287050247192 epoch is 133, train error is 0.008990713395178318, test error is 0.010298013687133789 epoch is 134, train error is 0.008885025046765804, test error is 0.01002080924808979 epoch is 135, train error is 0.009013487957417965, test error is 0.010105510242283344 epoch is 136, train error is 0.008897285908460617, test error is 0.01005212776362896 epoch is 137, train error is 0.009018302895128727, test error is 0.010412894189357758 epoch is 138, train error is 0.008922673761844635, test error is 0.010210921987891197 epoch is 139, train error is 0.008960590697824955, test error is 0.01030883938074112 epoch is 140, train error is 0.008797199465334415, test error is 0.01027711108326912 epoch is 141, train error is 0.008947267197072506, test error is 0.010475846007466316 epoch is 142, train error is 0.008998454548418522, test error is 0.010314736515283585 epoch is 143, train error is 0.008940584026277065, test error is 0.010578487999737263 epoch is 144, train error is 0.008874653838574886, test error is 0.010532774962484837 epoch is 145, train error is 0.009294978342950344, test error is 0.009907621890306473 epoch is 146, train error is 0.008898764848709106, test error is 0.011040279641747475 epoch is 147, train error is 0.008868013508617878, test error is 0.010186372324824333 epoch is 148, train error is 0.00884439330548048, test error is 0.01059015840291977 epoch is 149, train error is 0.009232071228325367, test error is 0.010928500443696976
在 Trainer 类中,save() 方法用于保存模型的参数和训练状态。
def save(self, epoch):
model_path = os.path.join('bhp_{}.pdparams'.format(epoch))
opt_path = os.path.join('bhp_{}.pdopt'.format(epoch))
paddle.save(self.model.state_dict(), model_path)
paddle.save(self.optimizer.state_dict(), opt_path)在上面的代码中通过使用 paddle.save() API 对模型进行保存。
paddle.save(obj, path, pickle_protocol=2)
关键参数含义如下:
如果不能对模型的训练和测试的表现进行量化地评估,就很难衡量模型的好坏。通常我们会定义一些衡量标准,这些标准可以通过对某些误差或者拟合程度的计算来得到。在波士顿房价预测实验中将使用决定系数 R2 来量化模型的表现。模型的决定系数是回归分析中十分常用的统计信息,经常被当作衡量模型预测能力好坏的标准。
说明:
R2 的数值范围从0至1,表示目标变量的预测值和实际值之间的相关程度平方的百分比。如果一个模型的 R2 值为 0 还不如直接用平均值来预测效果好;而一个 R2 值为 1 的模型则可以对目标变量进行完美的预测。从 0 至 1 之间的数值,则表示该模型中目标变量中有百分之多少能够用特征来解释。模型也可能出现负值的 R2,这种情况下模型所做预测有时会比直接计算目标变量的平均值差很多。
这里使用 sklearn.metrics 中的 r2_score 来计算真实值和预测值之间的 R2 值。
看到一个新指标 R2 , 我们也要看一下他的表达式怎么写:
R2=1−TSSRSS=1−Σi=1m(yi−yˉ)2Σi=1m(yi^−yi)2
其中, yi是每一个样本真实值,yˉ是每一个样本真实值的均值,yi^是每一个样本的预测值。
# 决定系数的公式很简单, 其实我们可以自己写一个函数def calc_r2_score(ys, preds):
# preds 是预测值, ys 是真实值
return 1 - ((preds - ys)**2).sum() / ((ys - ys.mean())**2).sum()def eval(model, dataset):
model.eval() # 将网络设置为验证状态
ys = list() # 存放真实值
preds = list() # 存放预测值
for i, data in enumerate(dataset()):
x, y = data
pred = model(x) # 获取模型输出
ys.extend(y.numpy())
preds.extend(pred.numpy())
ys = np.array(ys)[:, -1]
preds = np.array(preds)[:, -1]
score = r2_score(ys, preds) # 计算决定系数
return score
model_path = './models/bhp_49.pdparams'# 加载模型参数model_state_dict = paddle.load(model_path)
model.set_state_dict(model_state_dict)# 评估训练集和测试集score_train = eval(model, train_dataloader)
score_test = eval(model, test_dataloader)print('train score is {}, test score is {}'.format(score_train, score_test))train score is 0.7128057758618467, test score is 0.5358080939148715
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dataloader/dataloader_iter.py:89: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations if isinstance(slot[0], (np.ndarray, np.bool, numbers.Number)):
下面我们选择一条数据样本,测试下模型的预测效果。
def load_one_example():
# 从上边已加载的测试集中,随机选择一条作为测试数据
idx = np.random.randint(0, test_data.shape[0])
idx = -10
one_data, label = test_data[idx, :-1], test_data[idx, -1] # 修改该条数据shape为[1,13]
one_data = one_data.reshape([1,-1]) return one_data, labelmodel_dict = paddle.load('./models/bhp_49.pdparams')
model.load_dict(model_dict)
model.eval()# 参数为数据集的文件地址one_data, label = load_one_example()# 将数据转为动态图的variable格式 one_data = paddle.to_tensor(one_data)
predict = model(one_data)# 对结果做反归一化处理predict = predict * (max_values[-1] - min_values[-1]) + avg_values[-1]# 对label数据做反归一化处理label = label * (max_values[-1] - min_values[-1]) + avg_values[-1]print("Inference result is {}, the corresponding label is {}".format(predict.numpy(), label))Inference result is [[16.48576]], the corresponding label is 19.700000070256788
以上就是《人工智能导论:案例与实践》基于前馈神经网络实现波士顿房价预测的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 661
661























