FasterNet聚焦于提升神经网络速度,指出仅减少FLOPs未必降低延迟,关键在于提高每秒浮点运算(FLOPS)。其提出部分卷积(PConv),减少冗余计算与内存访问。基于此构建的FasterNet在多设备上速度更快,且精度不俗,如微型版比MobileVit - XXS快数倍且精度更高,大型版准确率高且吞吐量提升。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

为了设计快速神经网络,许多工作都集中在减少浮点运算的数量(FLOPs)上。 然而,我们观察到FLOPs的减少并不一定会导致延迟的类似程度的减少。 这主要源于低效率的每秒浮点运算(FLOPS)。 为了实现更快的网络,我们回顾了流行的操作,并证明如此低的FLOPS主要是由于操作频繁的内存访问,特别是深度卷积。 因此,我们提出了一种新的部分卷积(PConv),通过同时减少冗余计算和内存访问,可以更有效地提取空间特征。 在Ponv的基础上,我们进一步提出了FasterNet,这是一个新的神经网络家族,它在各种设备上获得了比其他网络更高的运行速度,而不影响各种视觉任务的准确性。 例如,在ImageNet1K上,我们的微型FasterNet-T0在GPU、CPU和ARM处理器上分别比MobileVit-XXS块3.1×、3.1×和2.5×,同时精度提高2.9%。 我们的大型FasterNet-L实现了令人印象深刻的83.5%的Top-1准确率,与新兴的Swin-B不相上下,同时在GPU上提高了49%的推断吞吐量,并在CPU上节省了42%的计算时间。
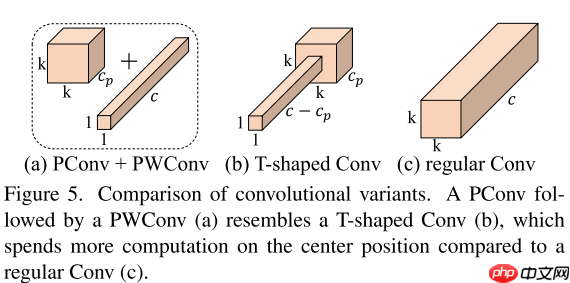
本文思考了一个问题:怎样才能更快?之前的工作大多使用FLOPs来表示神经网络的快慢,但是某些操作(如DWConv)实际运行并不快,这主要是因为频繁的内存访问。本文提出了新的见解:设计一个低FLOPs高FLOPS的操作,这样可以加快网络运行速度。由此,本文作者提出了一个“T型”的卷积——PConv,主要思想是DWConv虽然FLOPs小,但是由于频繁的内存访问导致FLOPS也小。由于网络存在冗余通道,那我是不是可以设计一个网络只用一部分去做空间计算,作者就尝试了这一想法,发现效果非常好,速度快,精度高。具体的操作如图5所示:
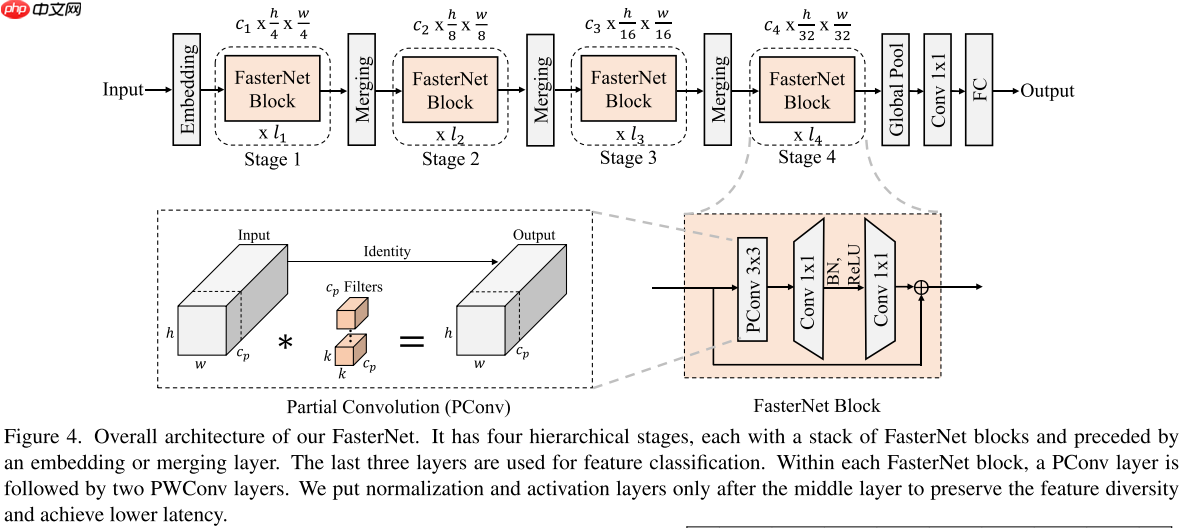
基于PConv和传统的分层Transformer,本文提出了一个新的网络架构——FasterNet,结构图如图4所示:
!pip install paddlex
%matplotlib inlineimport paddleimport paddle.fluid as fluidimport numpy as npimport matplotlib.pyplot as pltfrom paddle.vision.datasets import Cifar10from paddle.vision.transforms import Transposefrom paddle.io import Dataset, DataLoaderfrom paddle import nnimport paddle.nn.functional as Fimport paddle.vision.transforms as transformsimport osimport matplotlib.pyplot as pltfrom matplotlib.pyplot import figureimport paddleximport mathimport itertools
train_tfm = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.ColorJitter(brightness=0.2,contrast=0.2, saturation=0.2),
transforms.RandomHorizontalFlip(0.5),
transforms.RandomRotation(20),
paddlex.transforms.MixupImage(),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])
test_tfm = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
])paddle.vision.set_image_backend('cv2')# 使用Cifar10数据集train_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='train', transform = train_tfm)
val_dataset = Cifar10(data_file='data/data152754/cifar-10-python.tar.gz', mode='test',transform = test_tfm)print("train_dataset: %d" % len(train_dataset))print("val_dataset: %d" % len(val_dataset))train_dataset: 50000 val_dataset: 10000
batch_size=256
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=4) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, drop_last=False, num_workers=4)
class LabelSmoothingCrossEntropy(nn.Layer):
def __init__(self, smoothing=0.1):
super().__init__()
self.smoothing = smoothing def forward(self, pred, target):
confidence = 1. - self.smoothing
log_probs = F.log_softmax(pred, axis=-1)
idx = paddle.stack([paddle.arange(log_probs.shape[0]), target], axis=1)
nll_loss = paddle.gather_nd(-log_probs, index=idx)
smooth_loss = paddle.mean(-log_probs, axis=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss return loss.mean()def drop_path(x, drop_prob=0.0, training=False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
"""
if drop_prob == 0.0 or not training: return x
keep_prob = paddle.to_tensor(1 - drop_prob)
shape = (paddle.shape(x)[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
random_tensor = paddle.floor(random_tensor) # binarize
output = x.divide(keep_prob) * random_tensor return outputclass DropPath(nn.Layer):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob def forward(self, x):
return drop_path(x, self.drop_prob, self.training)class PConv(nn.Layer):
def __init__(self, dim, kernel_size=3, n_div=4):
super().__init__()
self.dim_conv = dim // n_div
self.dim_untouched = dim - self.dim_conv
self.conv = nn.Conv2D(self.dim_conv, self.dim_conv, kernel_size, padding=(kernel_size - 1) // 2, bias_attr=False) def forward(self, x):
x1, x2 = paddle.split(x, [self.dim_conv, self.dim_untouched], axis=1)
x1 = self.conv(x1)
x = paddle.concat([x1, x2], axis=1) return xclass FasterNetBlock(nn.Layer):
def __init__(self, dim, expand_ratio=2, act_layer=nn.ReLU, drop_path_rate=0.0):
super().__init__()
self.pconv = PConv(dim)
self.conv1 = nn.Conv2D(dim, dim * expand_ratio, 1, bias_attr=False)
self.bn = nn.BatchNorm2D(dim * expand_ratio)
self.act_layer = act_layer()
self.conv2 = nn.Conv2D(dim * expand_ratio, dim, 1, bias_attr=False)
self.drop_path = DropPath(drop_path_rate) if drop_path_rate > 0.0 else nn.Identity() def forward(self, x):
residual = x
x = self.pconv(x)
x = self.conv1(x)
x = self.bn(x)
x = self.act_layer(x)
x = self.conv2(x)
x = residual + self.drop_path(x) return xclass FasterNet(nn.Layer):
def __init__(self, in_channel=3, embed_dim=40, act_layer=nn.ReLU, num_classes=1000, depths=[1, 2, 8, 2], drop_path=0.0):
super().__init__()
self.stem = nn.Sequential(
nn.Conv2D(in_channel, embed_dim, 4, stride=4, bias_attr=False),
nn.BatchNorm2D(embed_dim),
act_layer()
)
drop_path_list = [x.item() for x in paddle.linspace(0, drop_path, sum(depths))]
self.feature = []
embed_dim = embed_dim for idx, depth in enumerate(depths):
self.feature.append(nn.Sequential(
*[FasterNetBlock(embed_dim, act_layer=act_layer, drop_path_rate=drop_path_list[sum(depths[:idx]) + i]) for i in range(depth)]
)) if idx < len(depths) - 1:
self.feature.append(nn.Sequential(
nn.Conv2D(embed_dim, embed_dim * 2, 2, stride=2, bias_attr=False),
nn.BatchNorm2D(embed_dim * 2),
act_layer()
))
embed_dim = embed_dim * 2
self.feature = nn.Sequential(*self.feature)
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv1 = nn.Conv2D(embed_dim, 1280, 1, bias_attr=False)
self.act_layer = act_layer()
self.fc = nn.Linear(1280, num_classes) def forward(self, x):
x = self.stem(x)
x = self.feature(x)
x = self.avg_pool(x)
x = self.conv1(x)
x = self.act_layer(x)
x = self.fc(x.flatten(1)) return xdef fasternet_t0():
num_classes=10
embed_dim = 40
depths = [1, 2, 8, 2]
drop_path_rate = 0.0
act_layer = nn.GELU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)def fasternet_t1():
num_classes=10
embed_dim = 64
depths = [1, 2, 8, 2]
drop_path_rate = 0.02
act_layer = nn.GELU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)def fasternet_t2():
num_classes=10
embed_dim = 96
depths = [1, 2, 8, 2]
drop_path_rate = 0.05
act_layer = nn.ReLU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)def fasternet_s():
num_classes=10
embed_dim = 128
depths = [1, 2, 13, 2]
drop_path_rate = 0.03
act_layer = nn.ReLU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)def fasternet_m():
num_classes=10
embed_dim = 144
depths = [3, 4, 18, 3]
drop_path_rate = 0.05
act_layer = nn.ReLU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)def fasternet_l():
num_classes=10
embed_dim = 192
depths = [3, 4, 18, 3]
drop_path_rate = 0.05
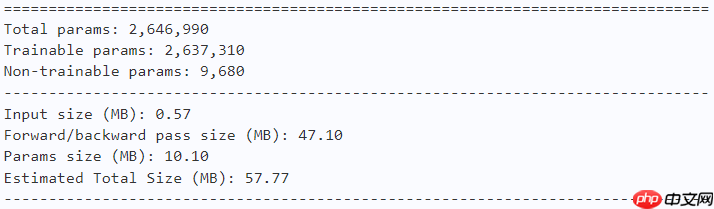
act_layer = nn.ReLU return FasterNet(embed_dim=embed_dim, act_layer=act_layer, num_classes=num_classes, depths=depths, drop_path=drop_path_rate)model = fasternet_t0() paddle.summary(model, (1, 3, 224, 224))
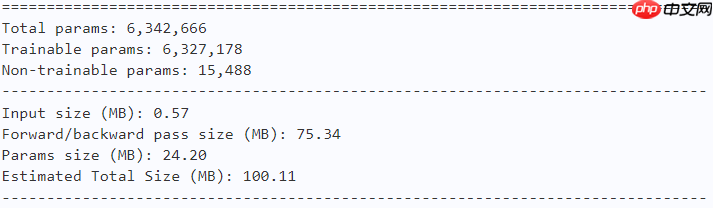
model = fasternet_t1() paddle.summary(model, (1, 3, 224, 224))
model = fasternet_t2() paddle.summary(model, (1, 3, 224, 224))
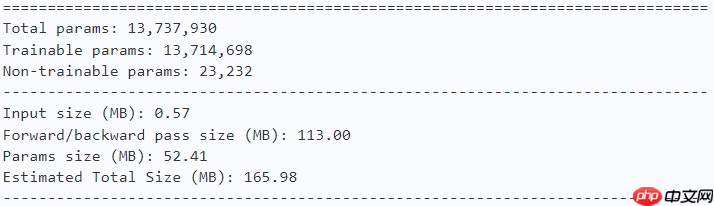
model = fasternet_s() paddle.summary(model, (1, 3, 224, 224))
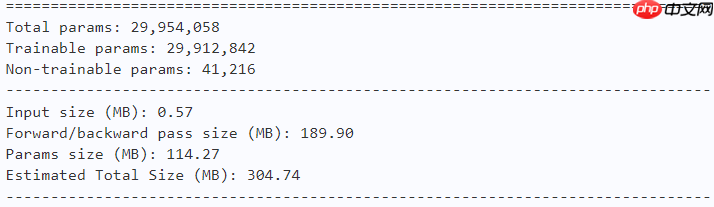
model = fasternet_m() paddle.summary(model, (1, 3, 224, 224))
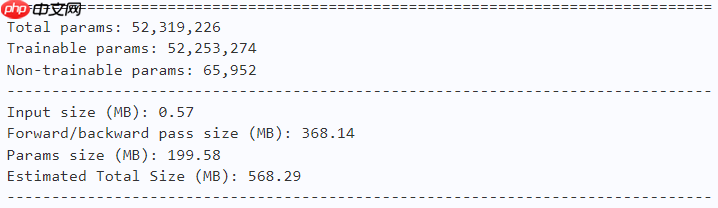
model = fasternet_l() paddle.summary(model, (1, 3, 224, 224))
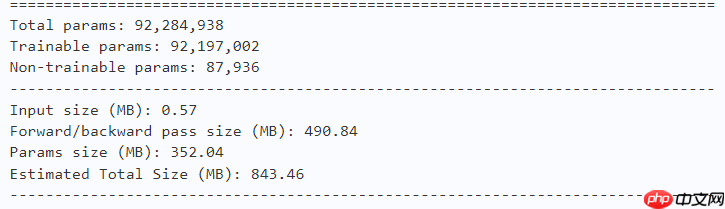
learning_rate = 0.001n_epochs = 100paddle.seed(42) np.random.seed(42)
work_path = 'work/model'# FasterNet-T0model = fasternet_t0()
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=scheduler, weight_decay=0.005)
gate = 0.0threshold = 0.0best_acc = 0.0val_acc = 0.0loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording lossacc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracyloss_iter = 0acc_iter = 0for epoch in range(n_epochs): # ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy() print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr())) for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc) if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100)) # ---------- Validation ----------
model.eval() for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100)) # ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
maxval = max(map(float, record['val'][title]))
ymax = max(maxtrain, maxval) * 1.1
mintrain = min(map(float, record['train'][title]))
minval = min(map(float, record['val'][title]))
ymin = min(mintrain, minval) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
x_2 = list(map(int, record['val']['iter']))
figure(figsize=(10, 6))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.plot(x_2, record['val'][title], c='tab:cyan', label='val')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()plot_learning_curve(loss_record, title='loss', ylabel='CE Loss')
<Figure size 1000x600 with 1 Axes>
plot_learning_curve(acc_record, title='acc', ylabel='Accuracy')
<Figure size 1000x600 with 1 Axes>
import time
work_path = 'work/model'model = fasternet_t0()
model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams'))
model.set_state_dict(model_state_dict)
model.eval()
aa = time.time()for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1) with paddle.no_grad():
logits = model(x_data)
bb = time.time()print("Throughout:{}".format(int(len(val_dataset)//(bb - aa))))Throughout:982
def get_cifar10_labels(labels):
"""返回CIFAR10数据集的文本标签。"""
text_labels = [ 'airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] return [text_labels[int(i)] for i in labels]def show_images(imgs, num_rows, num_cols, pred=None, gt=None, scale=1.5):
"""Plot a list of images."""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() for i, (ax, img) in enumerate(zip(axes, imgs)): if paddle.is_tensor(img):
ax.imshow(img.numpy()) else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False) if pred or gt:
ax.set_title("pt: " + pred[i] + "\ngt: " + gt[i]) return axeswork_path = 'work/model'X, y = next(iter(DataLoader(val_dataset, batch_size=18))) model = fasternet_t0() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict) model.eval() logits = model(X) y_pred = paddle.argmax(logits, -1) X = paddle.transpose(X, [0, 2, 3, 1]) axes = show_images(X.reshape((18, 224, 224, 3)), 1, 18, pred=get_cifar10_labels(y_pred), gt=get_cifar10_labels(y)) plt.show()
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
<Figure size 2700x150 with 18 Axes>
!pip install interpretdl
import interpretdl as it
work_path = 'work/model'model = fasternet_t0() model_state_dict = paddle.load(os.path.join(work_path, 'best_model.pdparams')) model.set_state_dict(model_state_dict)
X, y = next(iter(DataLoader(val_dataset, batch_size=18))) lime = it.LIMECVInterpreter(model)
lime_weights = lime.interpret(X.numpy()[3], interpret_class=y.numpy()[3], batch_size=100, num_samples=10000, visual=True)
100%|██████████| 10000/10000 [00:46<00:00, 212.97it/s]
<Figure size 640x480 with 1 Axes>
| Model | Val Acc | Speed |
|---|---|---|
| FasterNet | 92.8% | 982 |
| - PConv +DWConv | 93.2% | 580 |
对比实验见DWConv.ipynb
FasterNet从FLOPs和FLOPS两个角度重新审视卷积操作对于神经网络的影响,提出了新的神经网络家族——FasterNet。FasterNet不仅速度快,准确率也高。
以上就是【CVPR2023】FasterNet:追逐更高FLOPS、更快的神经网络的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 392
392




















