本文介绍基于PaddlePaddle框架复现PointNet分类模型的方案。PointNet是早期处理点云分类/分割的框架,通过T-Net增强表示能力,用Max-Pooling获全局向量分类。在ModelNet40数据集上,该复现达89.4准确率,接近官方89.2。还详述数据集、网络结构、损失函数等,提供训练测试参数及操作步骤。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

采用PaddlePaddle框架进行PointNet的复现,这里只有关于分类模型的复现方案。
本项目基于百度开源的PaddlePaddle深度学习框架进行PointNet的复现。
PointNet是早期针对点云的分类/分割问题设计的框架,它提供了一个统一的框架来支持众多的问题。尽管PointNet的提出时间较早,整体架构较为简单,但是它仍旧达到了一个高效且具有竞争力的表现效果,在今日针对点云相关问题的研究,仍然具有学习的意义。
Paper: PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
Competition Page: PaddlePaddle AI Studio
GitHub Repo: Paddle-PointNet
PointNet Architecture: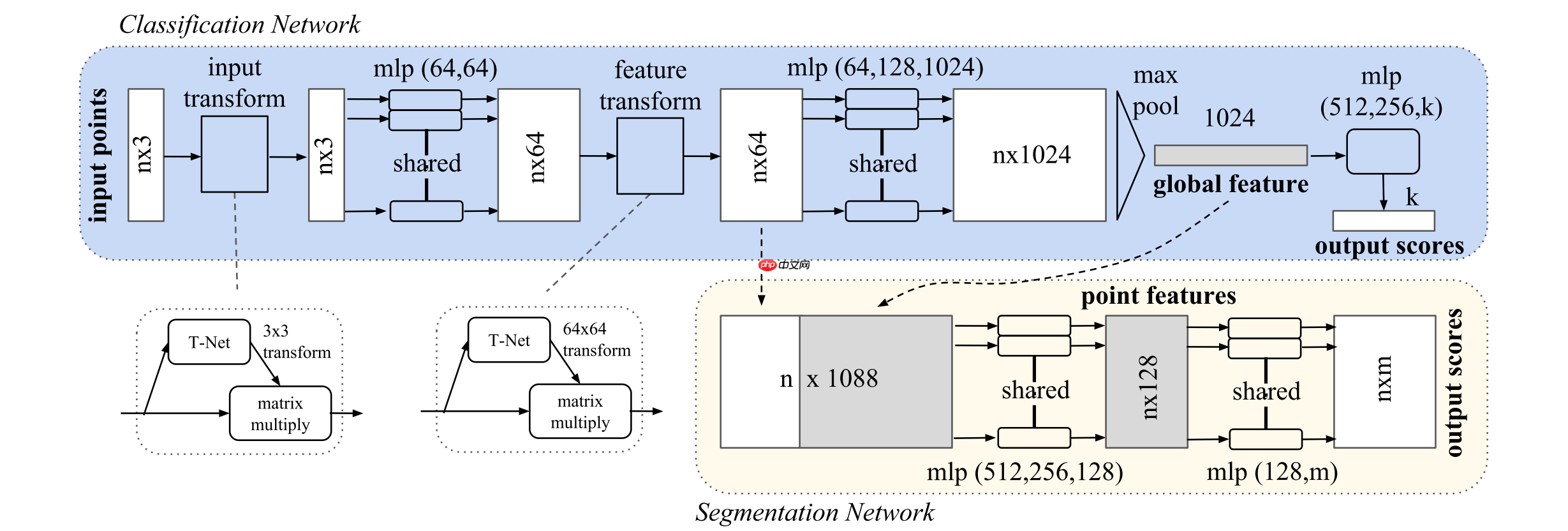
PointNet的整体框架如上图所示,从笔者的理解出发,如果要针对于点云进行分类和分割任务,不同的点云有着不同数目的空间点。那么网络设计需要保证针对不同的点输入是排序无关的,而PointNet的思路就是从空间点云当中去采样一个子集,通过子集来对于点云整体进行一个建模。这样的好处就是可以保证输入规模是相同的,使得构建一个端到端的深度学习网络成为可能。
那么最简单的就是通过一个多层感知机的模型进行前馈传播,PointNet作为早期的工作也是这样一个思路,为使得排序无关,所以不能在不同点之间采用卷积/全连接网络进行带参数的训练,在我的理解当中T-Net就是为了增强网络的表示能力所引入的。最终将其直接利用Max-Pooling方法得到一个表征全局的向量,用于进行分类。在分割任务当中与原本得到的点的表示进行拼接,作为全局表征的补充。
显然直接进行全局的Pooling会损失大量的局部信息,PointNet++当中就采用最近邻的方法,相对于直接进行全局池化可以达到更好的效果,有兴趣的读者可以进行拓展阅读,在本项目当中就不多做介绍了。
Other Version Implementation:
Acceptance condition
针对于ModelNet40的分类准确率:
| Model | Accuracy |
|---|---|
| PointNet (Official) | 89.2 |
| PointNet (PyTorch) | 90.6 |
| PointNet (PaddlePaddle) | 89.4 |
普林斯顿ModelNet项目的目标是为计算机视觉、计算机图形学、机器人学科和认知科学领域的研究人员提供全面、清晰的3D CAD模型对象集合。
数据集的基本描述信息如下:
下载数据集 alignment ModelNet 并保存在 modelnet40_normal_resampled/. 本项目采用与PyTorch版本实现相同的数据集.
wget https://shapenet.cs.stanford.edu/media/modelnet40_normal_resampled.zip unzip modelnet40_normal_resampled.zip
python train.py
训练的模型结果将默认保存在路径 pointnet.pdparams。
实验在单卡环境下大约需要训练10个小时左右能够达到最优表现。
python test.py
├── README.md├── arch.png├── data.py├── model.py├── pointnet.pdparams├── requirements.txt├── test.py├── train.log└── train.py
class TNet(nn.Layer):
def __init__(self, k=64):
super(TNet, self).__init__()
self.conv1 = nn.Conv1D(k, 64, 1)
self.conv2 = nn.Conv1D(64, 128, 1)
self.conv3 = nn.Conv1D(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k * k)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1D(64)
self.bn2 = nn.BatchNorm1D(128)
self.bn3 = nn.BatchNorm1D(1024)
self.bn4 = nn.BatchNorm1D(512)
self.bn5 = nn.BatchNorm1D(256)
self.k = k
self.iden = paddle.eye(self.k, self.k, dtype=paddle.float32) def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = paddle.max(x, 2, keepdim=True)
x = x.reshape((-1, 1024))
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
x = x.reshape((-1, self.k, self.k)) + self.iden return x
仿射变换矩阵由微型网络 (T-net) 预测,并将此变换直接应用于输入点的坐标。 iden 用于使输出矩阵被初始化为一个单位阵。
class CrossEntropyMatrixRegularization(nn.Layer):
def __init__(self, mat_diff_loss_scale=1e-3):
super(CrossEntropyMatrixRegularization, self).__init__()
self.mat_diff_loss_scale = mat_diff_loss_scale def forward(self, pred, target, trans_feat=None):
loss = F.cross_entropy(pred, target) if trans_feat is None:
mat_diff_loss = 0
else:
mat_diff_loss = feature_transform_reguliarzer(trans_feat)
total_loss = loss + mat_diff_loss * self.mat_diff_loss_scale return total_lossdef feature_transform_reguliarzer(trans):
d = trans.shape[1]
I = paddle.eye(d)
loss = paddle.mean(
paddle.norm(
paddle.bmm(trans, paddle.transpose(trans, (0, 2, 1))) - I, axis=(1, 2)
)
) return loss
将正则化损失(权重为 0.001)添加到 softmax 分类损失中,使矩阵接近一个正交矩阵。 为了使得高维变换能够发挥作用,正则化损失是必须的。 通过结合变换和正则化项,我们可以达到最优的分类效果。
| Name | Type | Default | Description |
|---|---|---|---|
| data_dir | str | "modelnet40_normal_resampled" | 训练和测试的数据集路径 |
| num_point | int | 1024 | 从点云当中采样的点的个数 |
| batch_size | int | 32 | 训练过程中采用的Batch Size大小 |
| num_category | int | 40 | ModelNet10/40 |
| learning_rate | float | 1e-3 | 训练过程中采用的Learning Rate大小 |
| max_epochs | int | 200 | 训练过程中迭代的epoch上限 |
| num_workers | int | 32 | Dataloader采用的workers数量 |
| log_batch_num | int | 50 | 每隔多少个batch进行一次日志保存 |
| model_path | str | "pointnet.pdparams" | 在训练过程中保存/在测试过程中导入的模型路径 |
| lr_decay_step | int | 20 | StepDecay学习率衰减方法中定义的step_size |
| lr_decay_gamma | float | 0.7 | StepDecay学习率衰减方法中定义的gamma |
有关该模型的其他信息,可以在如下表格中查看:
| 信息 | 描述 |
|---|---|
| 作者 | 甘云冲 |
| 时间 | 2021.8 |
| 框架版本 | Paddle 2.1.2 |
| 支持的硬件 | GPU/CPU |
| 模型下载链接 | pointnet.pdparams |
准备数据集:
!unzip /home/aistudio/data/data35576/modelnet40.zip
运行Test方法
!python test.py
如果需要的话可以重新训练模型
!python train.py
以上就是基于飞桨框架复现PointNet的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 667
667






















