
机器之心报道
编辑:泽南、陈陈
大模型架构正面临变革的临界点?
在应对复杂推理任务时,当前主流的大语言模型(LLM)普遍依赖思维链(CoT)技术。然而,这类方法普遍存在任务分解困难、训练数据需求庞大以及推理延迟高等瓶颈。
近期,Sapient Intelligence 的研究团队受人脑的分层结构与多时间尺度信息处理机制启发,提出了一种全新的循环神经网络架构——分层推理模型(HRM),该模型在确保训练稳定与高效的同时,实现了极高的计算深度。
HRM 的核心在于两个相互协作的循环模块,它们在单次前向传播中即可完成顺序推理任务,且无需对中间推理步骤进行显式标注或监督。其中,高级模块负责缓慢、抽象的长期规划,而低级模块则专注于快速、细粒度的局部计算。令人惊讶的是,这一模型仅包含 2700 万参数,并使用约 1000 个样本训练,就在多项高难度推理任务中展现出卓越表现。
更关键的是,HRM 无需预训练,也不依赖 CoT 数据,却在解决极端难度的数独谜题和大型迷宫最优路径搜索等任务上接近完美。此外,在抽象与推理语料库(ARC)这一衡量通用智能的关键基准上,HRM 的性能甚至超越了拥有更长上下文窗口的大型模型。
由此可见,HRM 有望成为推动通用计算范式变革的重要一步。
 paper.png论文:Hierarchical Reasoning Model 论文链接:https://www.php.cn/link/f20b96673d628cfa435e92faa3b94666 —— HRM 的设计灵感源于大脑的层级化处理与时间分离机制,包含两个在不同时间尺度上协同工作的循环网络。右图 —— 尽管仅使用约 1000 个训练样本,HRM(2700 万参数)在 ARC-AGI、Sudoku-Extreme 和 Maze-Hard 等极具挑战性的符号推理任务上显著优于最先进的 CoT 模型,后者几乎完全失效。HRM 从随机初始化开始训练,不依赖思维链提示,直接根据输入完成推理。
paper.png论文:Hierarchical Reasoning Model 论文链接:https://www.php.cn/link/f20b96673d628cfa435e92faa3b94666 —— HRM 的设计灵感源于大脑的层级化处理与时间分离机制,包含两个在不同时间尺度上协同工作的循环网络。右图 —— 尽管仅使用约 1000 个训练样本,HRM(2700 万参数)在 ARC-AGI、Sudoku-Extreme 和 Maze-Hard 等极具挑战性的符号推理任务上显著优于最先进的 CoT 模型,后者几乎完全失效。HRM 从随机初始化开始训练,不依赖思维链提示,直接根据输入完成推理。
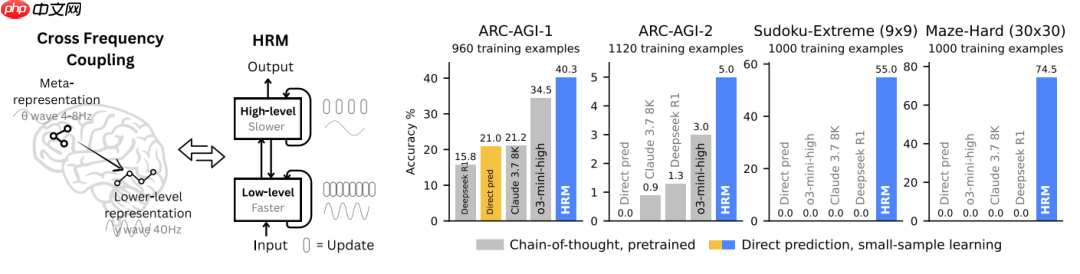 1.png分层推理模型
1.png分层推理模型
深度在复杂推理中的关键作用如下图所示。
左图:在需要大量树搜索与回溯的 Sudoku-Extreme Full 任务中,增加 Transformer 的宽度并未提升性能,而增加深度则至关重要。右图:传统架构已达到性能饱和,无法有效利用更深的网络。HRM 成功突破这一限制,充分利用其深度结构,实现了接近完美的准确率。
 2.pngHRM 的核心设计灵感来源于大脑:层级结构 + 多时间尺度处理。具体包括:
2.pngHRM 的核心设计灵感来源于大脑:层级结构 + 多时间尺度处理。具体包括:
分层处理机制:大脑通过皮层区域的层级结构处理信息。高级区域(如前额叶)在较长时间尺度上整合信息并形成抽象表征,而低级区域(如感觉皮层)则处理即时、具体的感知输入。
时间尺度分离:不同层级的神经活动具有不同的时间动态,表现为特定的神经振荡模式。这种机制使高级脑区能够稳定引导低级脑区的快速运算。
循环连接特性:大脑中存在大量反馈连接,构成循环神经网络。这种结构通过迭代优化不断提升表征精度和上下文适应能力,尽管需要更多处理时间,但有效缓解了反向传播时间算法(BPTT)中的深层信用分配难题。
HRM 模型由四个可学习组件构成:输入网络 f_I (・; θ_I ),低级循环模块 f_L (・; θ_L),高级循环模块 f_H (・; θ_H),以及输出网络 f_O (・; θ_O)。
HRM 将输入向量 x 映射为输出预测 y´。首先,输入 x 被投影为一个初始表示
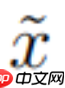 image.png:
image.png:
 image.png每个周期结束时,H 模块的状态为:
image.png每个周期结束时,H 模块的状态为:
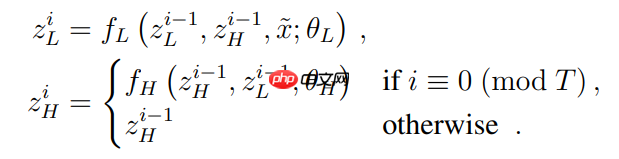 image.png最终,在经历 N 个完整周期后,从 H 模块的隐藏状态中提取预测结果
image.png最终,在经历 N 个完整周期后,从 H 模块的隐藏状态中提取预测结果
 image.png。
image.png。
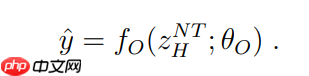 image.pngHRM 展现出层级收敛行为:H 模块状态趋于稳定收敛,而 L 模块在每个周期内反复收敛后被 H 模块重置,导致残差出现周期性峰值。相比之下,普通循环网络快速收敛,残差迅速趋零;而深度前馈网络则因梯度消失问题,在输入层和输出层保留显著残差。
image.pngHRM 展现出层级收敛行为:H 模块状态趋于稳定收敛,而 L 模块在每个周期内反复收敛后被 H 模块重置,导致残差出现周期性峰值。相比之下,普通循环网络快速收敛,残差迅速趋零;而深度前馈网络则因梯度消失问题,在输入层和输出层保留显著残差。
 3.pngHRM 引入了两项关键技术:
3.pngHRM 引入了两项关键技术:
一是近似梯度机制。传统循环模型依赖 BPTT 计算梯度,需存储所有时间步的隐藏状态,内存消耗随时间步 T 线性增长(O(T))。
HRM 提出一种一步梯度近似方法:仅使用各模块最终状态的梯度,其余状态视为常量。该方法仅需 O(1) 内存,无需展开时间序列,且可轻松集成于 PyTorch 等自动微分框架中,如图 4 所示。
 image.png
image.png
二是深度监督机制。本文将深度监督融入 HRM 的训练过程。
对于每个样本 (x, y),模型执行多段前向传递,设 M 为总段数。令
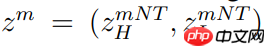 image.png表示第 m 段结束时的隐藏状态(含高级与低级分量)。图 4 展示了深度监督训练的伪代码流程。
image.png表示第 m 段结束时的隐藏状态(含高级与低级分量)。图 4 展示了深度监督训练的伪代码流程。
自适应计算时间(ACT)。大脑可在直觉式“快思考”(System 1)与深思熟虑的“慢思考”(System 2)之间灵活切换。
受此启发,研究将自适应停止策略引入 HRM,实现动态计算资源分配。如图 5 所示,ACT 能根据任务复杂度自动调整推理步数,在大幅节省计算开销的同时,几乎不影响性能。
 image.png
image.png
推理时间扩展。理想的神经模型应能在推理阶段动态增加计算资源以提升性能。如图 5-(c) 所示,
以上就是只用2700万参数,这个推理模型超越了DeepSeek和Claude的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 900
900



















