WeKnora是什么
weknora 是由腾讯推出的开源文档理解与语义检索框架,基于大语言模型(llm)构建,旨在实现高效的知识提取与智能问答。该框架采用模块化架构,支持对多种格式的多模态文档(如pdf、word、图像等)进行深度解析,并结合rag(检索增强生成)技术,提供精准的语义搜索与上下文感知问答能力。weknora 集成了强大的多模态认知引擎、多样化的检索策略,支持私有化部署和即用型web界面,广泛适用于企业知识库、科研分析、法律合规等领域,同时兼容本地部署与微信生态接入,助力组织实现智能化知识管理。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
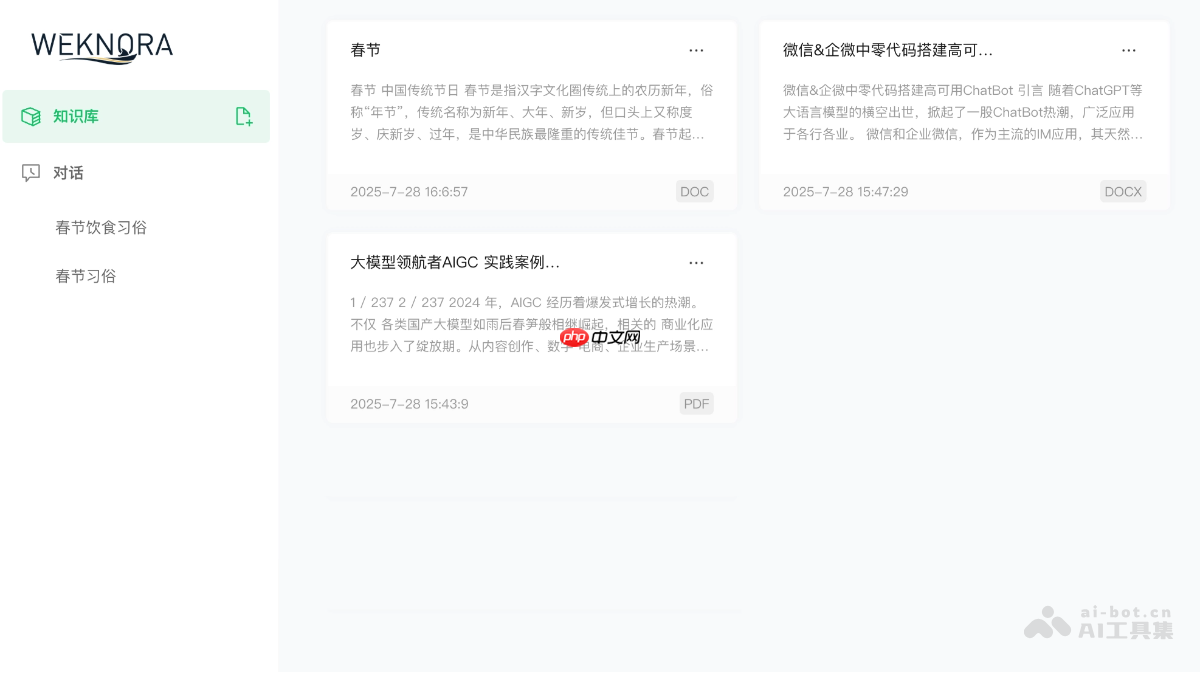
WeKnora的主要功能
-
多模态文档解析:可精确处理PDF、Word、图片等多种文档类型,提取文本、表格及图像中的语义信息,构建统一的结构化知识中枢。
-
智能语义检索:融合关键词匹配、向量检索与知识图谱检索等多种策略,依托语义向量索引实现高效、准确的信息召回。
-
大语言模型集成:兼容主流大模型(如Qwen、DeepSeek等),支持上下文理解与多轮对话,输出高质量的自然语言回答。
-
知识图谱构建:自动将文档内容转化为知识图谱,呈现段落间的语义关联,增强检索结果的深度与覆盖范围。
-
灵活部署方案:支持本地部署、Docker容器化及私有云环境,配备完整的监控与日志系统,便于运维与扩展。
-
便捷交互体验:提供直观的Web UI,支持拖拽上传、知识库可视化管理,无需编码即可部署,并可快速集成至微信生态。
WeKnora的技术原理
-
模块化架构设计:框架由文档解析、向量化处理、检索引擎和大模型推理等模块组成,各模块可独立配置与扩展,支持灵活组合检索逻辑与模型服务。
-
多模态预处理能力:结合OCR与跨模态建模技术,精准识别图文混排内容,将非结构化数据转化为结构化语义表示,形成统一的数据视图。
-
语义向量索引机制:通过 embedding 技术将文本内容转化为向量,构建高效的语义索引,支持多种向量数据库(如pgvector for PostgreSQL、Elasticsearch等),实现快速检索。
-
RAG增强生成机制:采用Retrieval-Augmented Generation(RAG)架构,将检索到的相关文档片段作为上下文输入大模型,提升回答准确性,支持复杂语义理解和多轮交互。
WeKnora的项目地址
WeKnora的应用场景
-
企业知识管理:帮助员工快速查找制度文件、操作手册和内部资料,提升信息获取效率,减少培训成本。
-
科研文献分析:加速学术论文、研究报告的检索与内容提炼,辅助科研人员高效开展创新研究。
-
产品技术支持:为用户提供产品说明书问答和技术文档查询服务,快速响应技术问题,提升客户满意度。
-
法律合规审查:支持合同条款比对、法规政策检索与案例分析,提高合规审查效率,降低法律风险。
-
医疗知识辅助:协助医生检索医学文献、诊疗指南和历史病例,提升临床决策的科学性与准确性。
以上就是WeKnora— 腾讯开源的文档理解与语义检索框架的详细内容,更多请关注php中文网其它相关文章!



 广告
广告







 782
782






















