
一、目标文件
我们知道源文件经过编译链接形成可执行程序,在
Windows
IDEA
在
Linux
gcc
而源文件经过编译形成
.o
.o
.o
.o
目标文件是一个二进制文件,其格式是
ELF
而我们还知道,我们源文件经过编译形成
.o
.o
那在链接的过程中做了什么呢?我们的
.o
目标文件的文件格式是
ELF
ELF
ELF
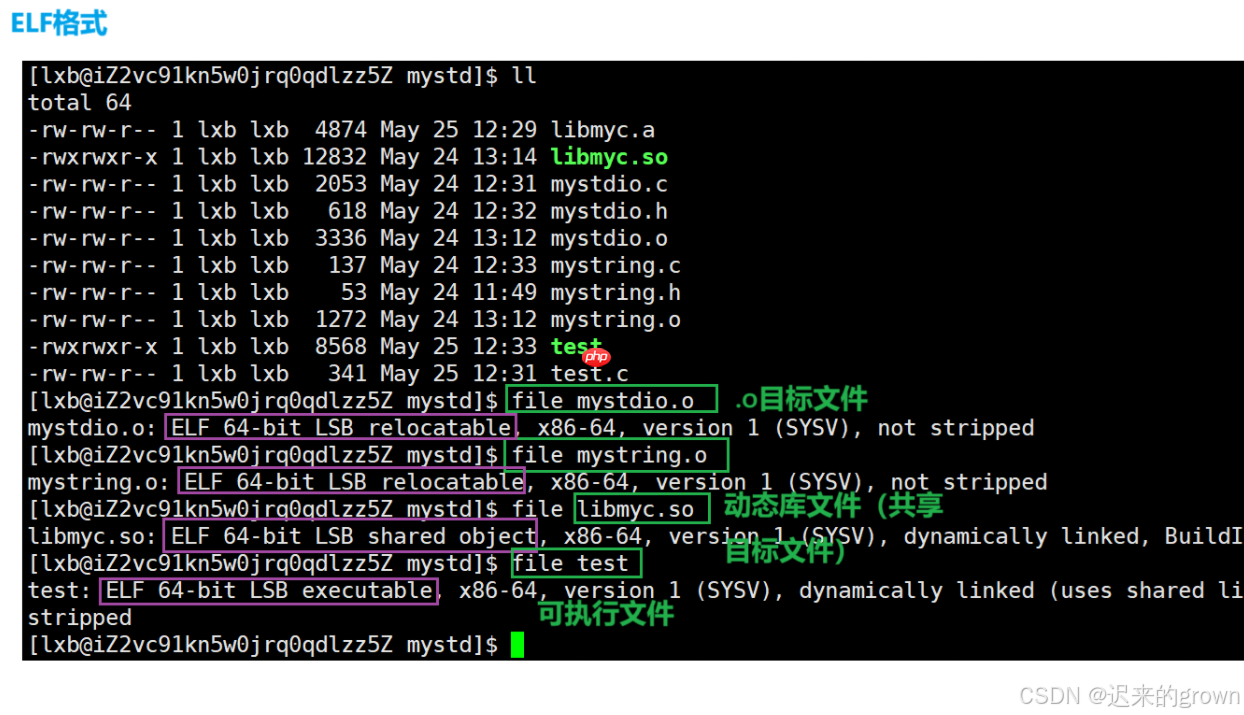
可以看到
.o
ELF
.o
.so
.a
.o
ELF
ELF
一般
ELF
ELF
ELF Header
program Header Table
Section
Section Header Table
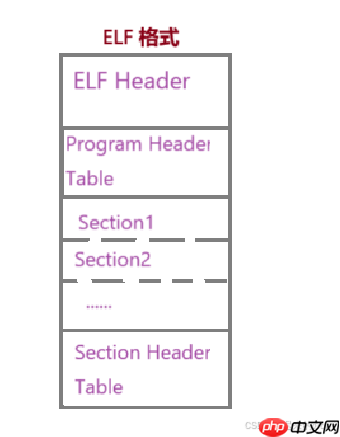
那这些部分都包含哪些内容呢?
在
Linux
readelf
ELF
节(
Section
节是
ELF
ELF
例如
.text
.data
.bss
节头表(
Section Header Table
在
ELF
在节头表
Section Header Table
Name
Type
Address
我们可以使用
readelf -S
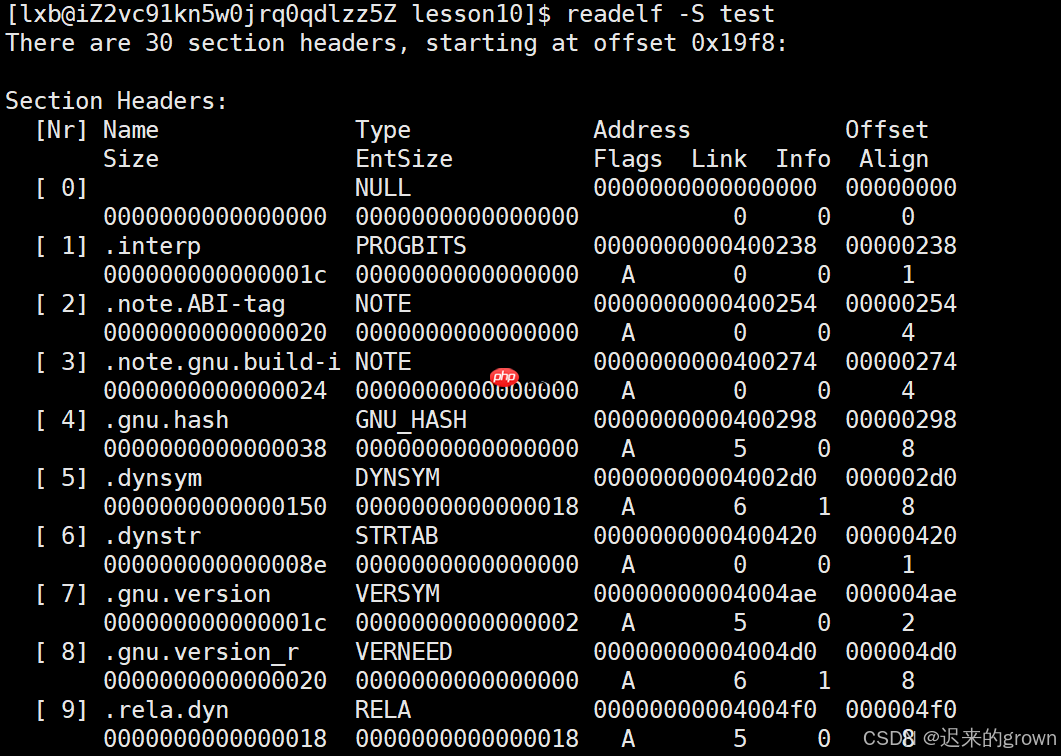
这里内容比较多,只截取了一部分;
在这里面,我们可以看到存在
.text
.data
rodata
.bss
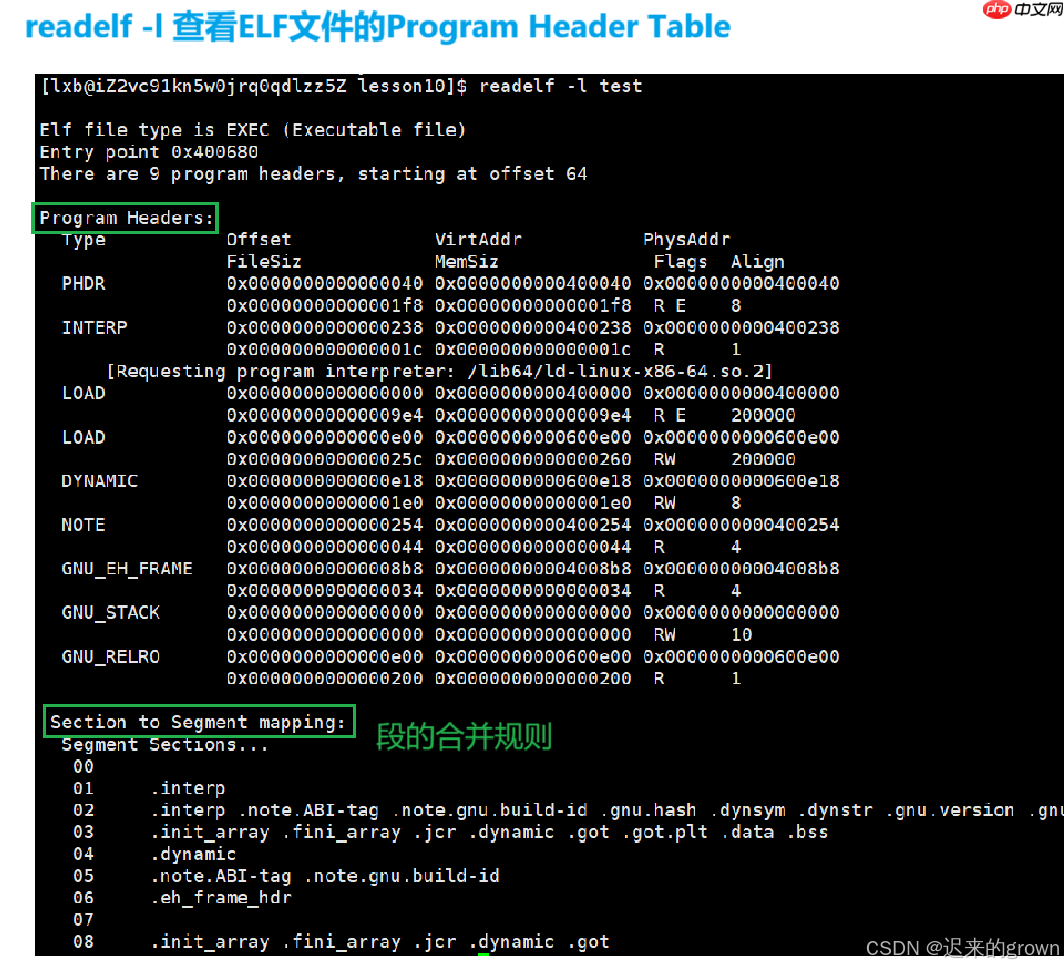
程序头表
program Header Table
在程序头表中,记录了所有有效段和它们的属性。
在表中记录着每一段的开始位置和位移
offset
我们可以使用
readelf -l
ELF Header
在
ELF Header
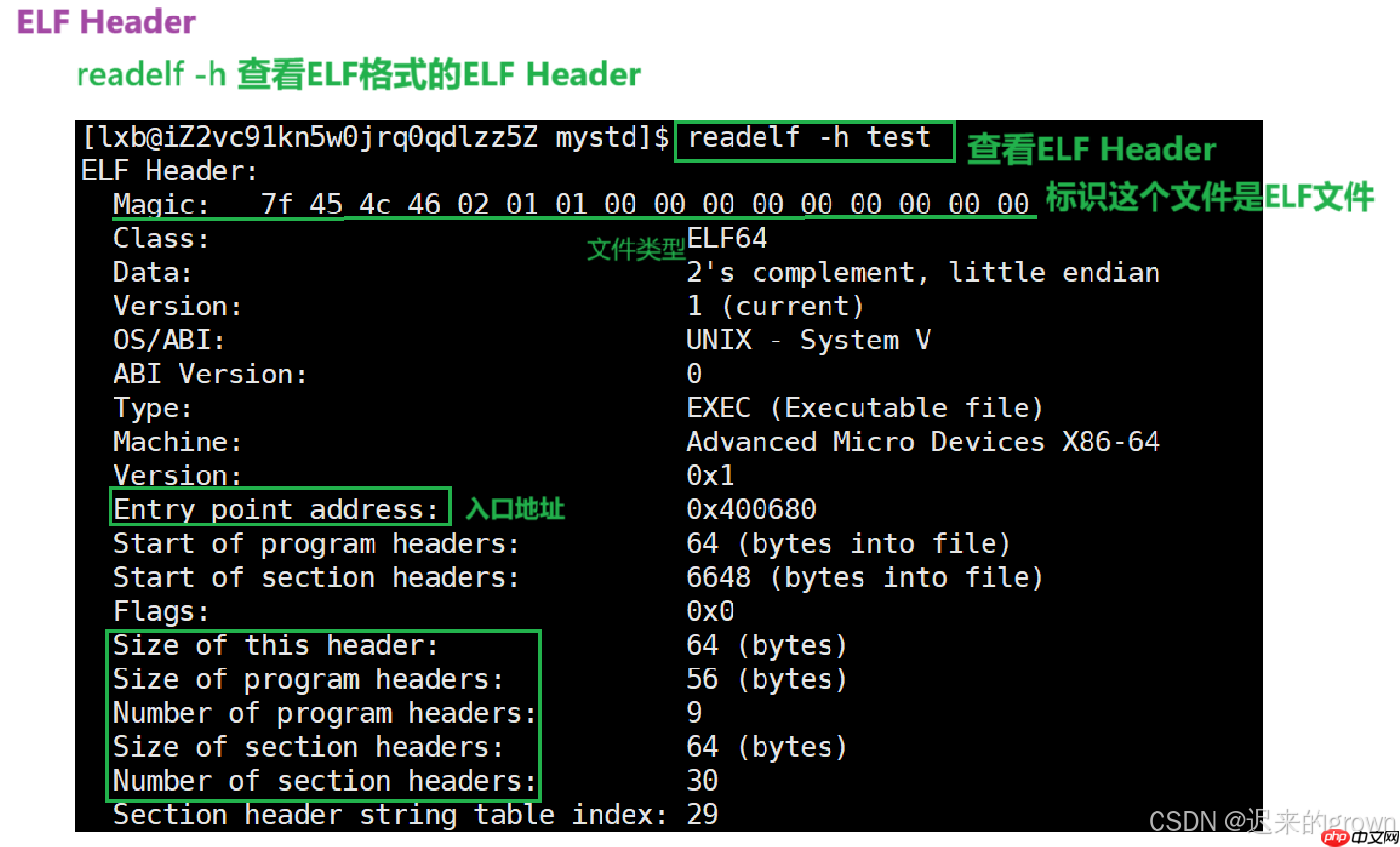
readelf -h
ELF Header
了解了ELF文件的组成,感觉还是云里雾里的;(这里了解ELF文件中有哪几个部分组成,每一个部分大概内容即可)
那
.o
.so
这个就比较简单了,因为我们的
.o
.o
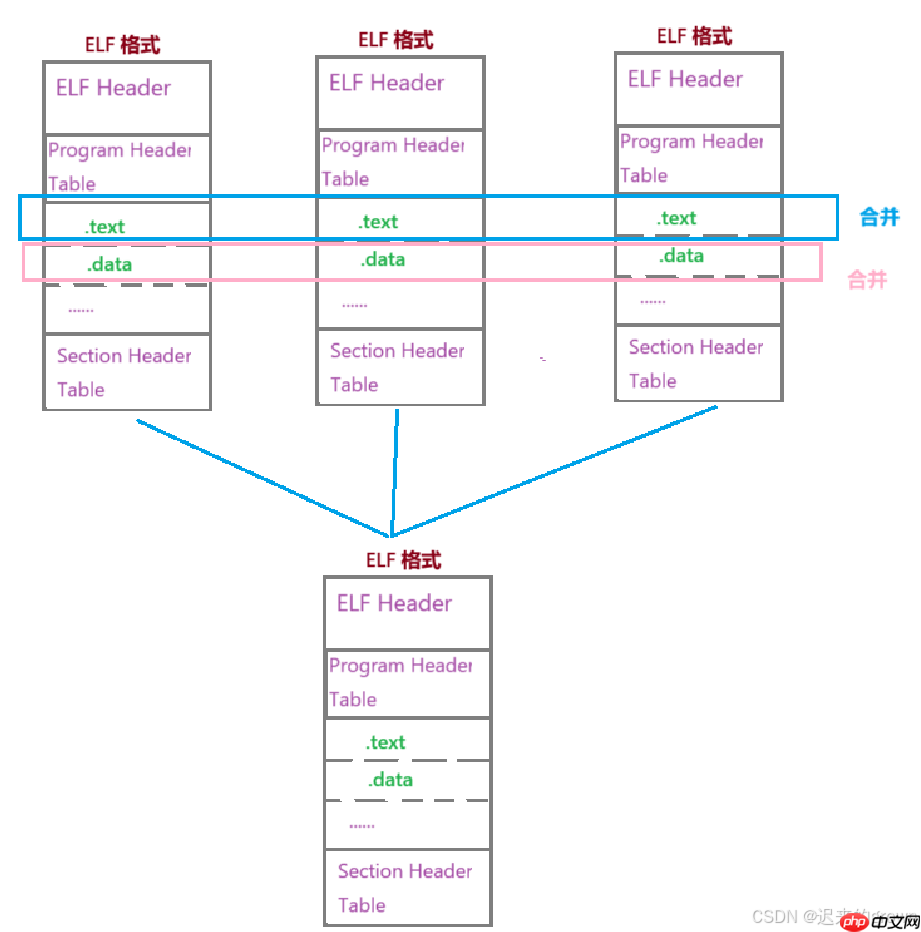
这里简单了解一下,在后续链接和加载内容中详细说明。
ELF可执行文件的加载我们知道一个ELF文件中存在非常多的
Section
Section
segment
合并规则:相同属性,可读/可写/可执行等等。
这样不同的
Section
segment
而合并方式在形成ELF时就已经确定了,在ELF的程序头表
Paogram Header Table

可以看到我们的
.text
.rodata
segment
.got
.data
.bss
segment
4
segment
segment
首先我们要知道,静态链接本质上就是将我们所有的
.o
.o
.o
那
.o
现在有存在
code.c
fun.c
<pre class="brush:php;toolbar:false;">//code.c#include <stdio.h>void fun();int main(){ fun();printf("code: \n");return 0;}//fun.c#include <stdio.h>void fun(){printf("fun: \n");}我们知道编译形成的
.o
objdump
objdump -d
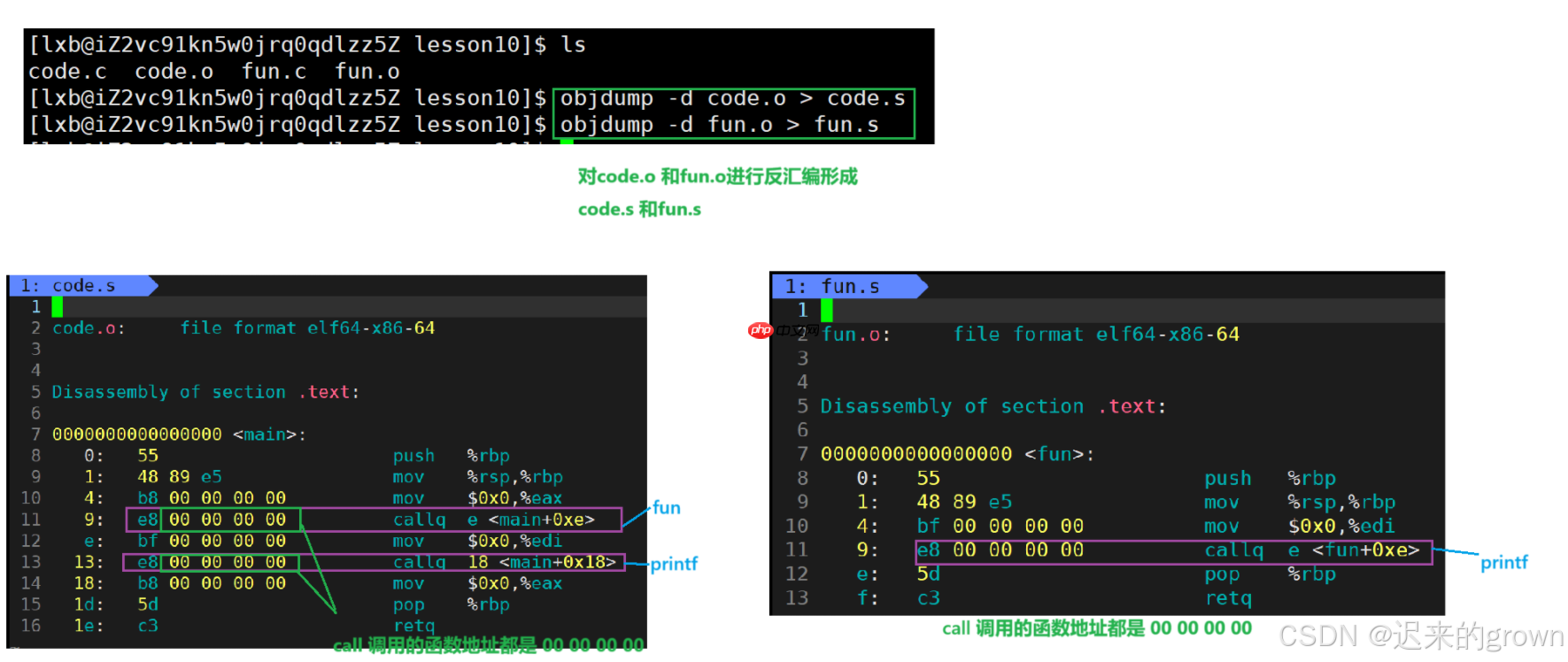
我们可以发现,在
code.c
fun.c
.o
code.s
fun
cal
0
printf
0
fun.s
call
printf
0
我们再来对可执行程序进行返汇编查看一下:
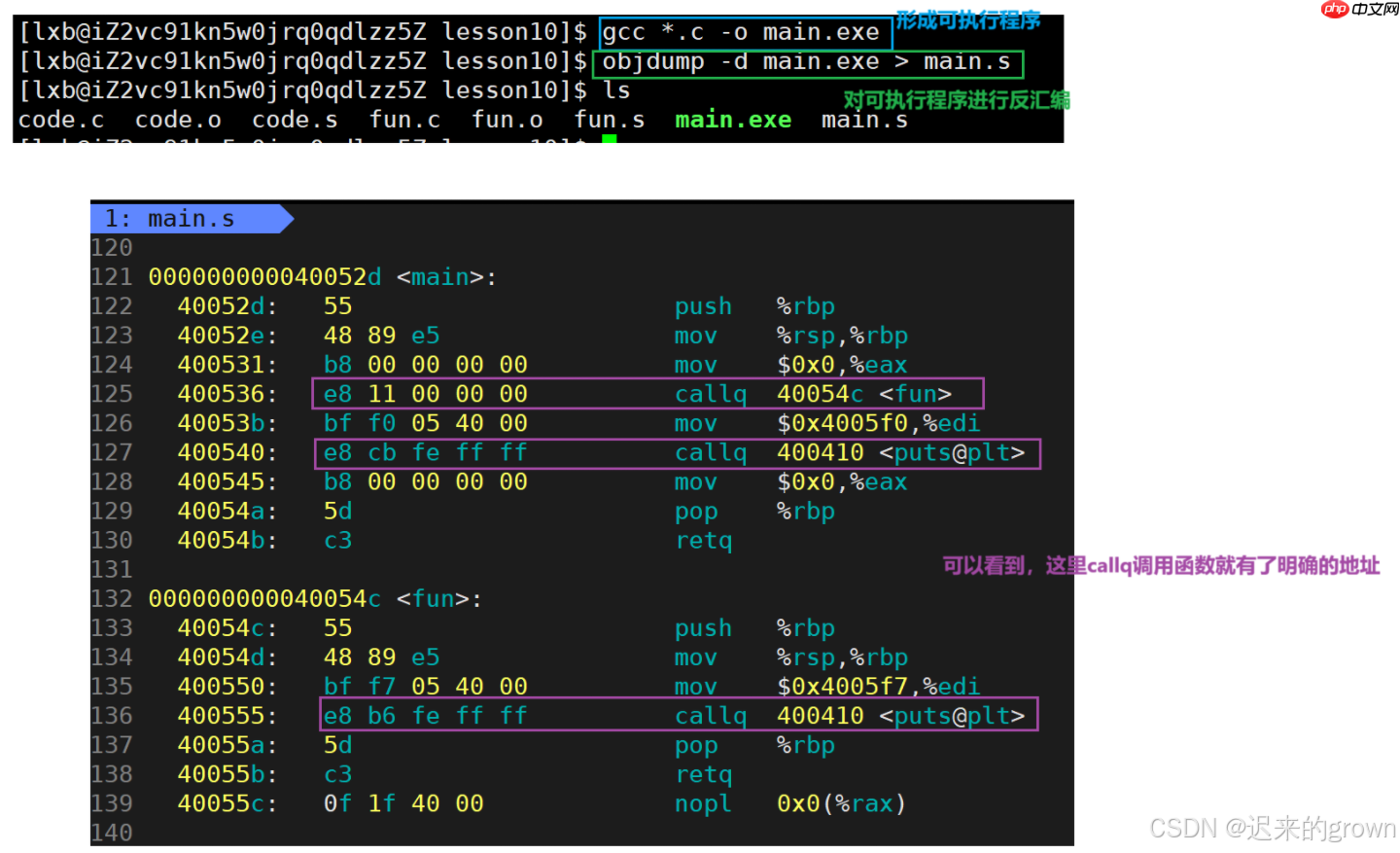
可以看到,在可执行程序反汇编形成的文件中,
callq
readelf -S
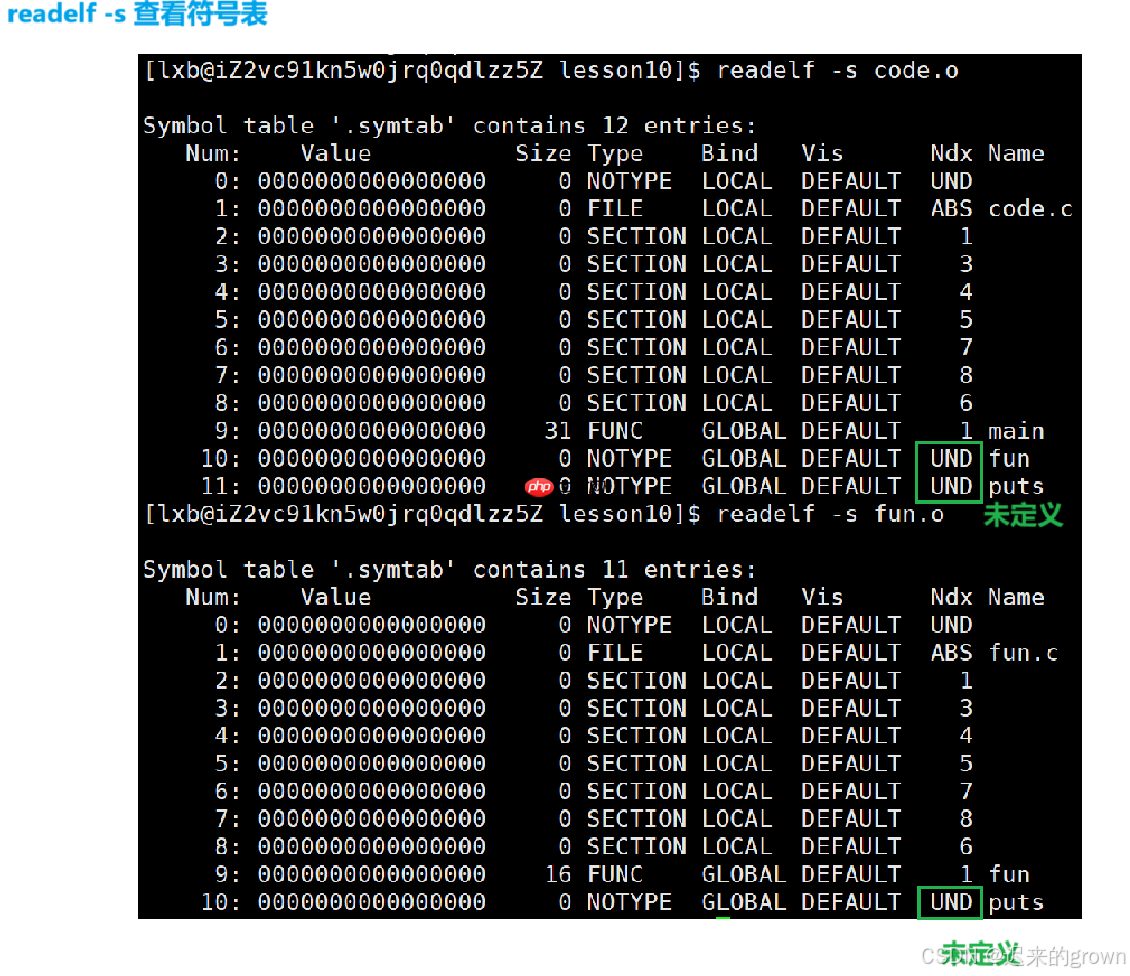
在链接时,对照符号表,根据表里记录的地址来修正函数的地址。
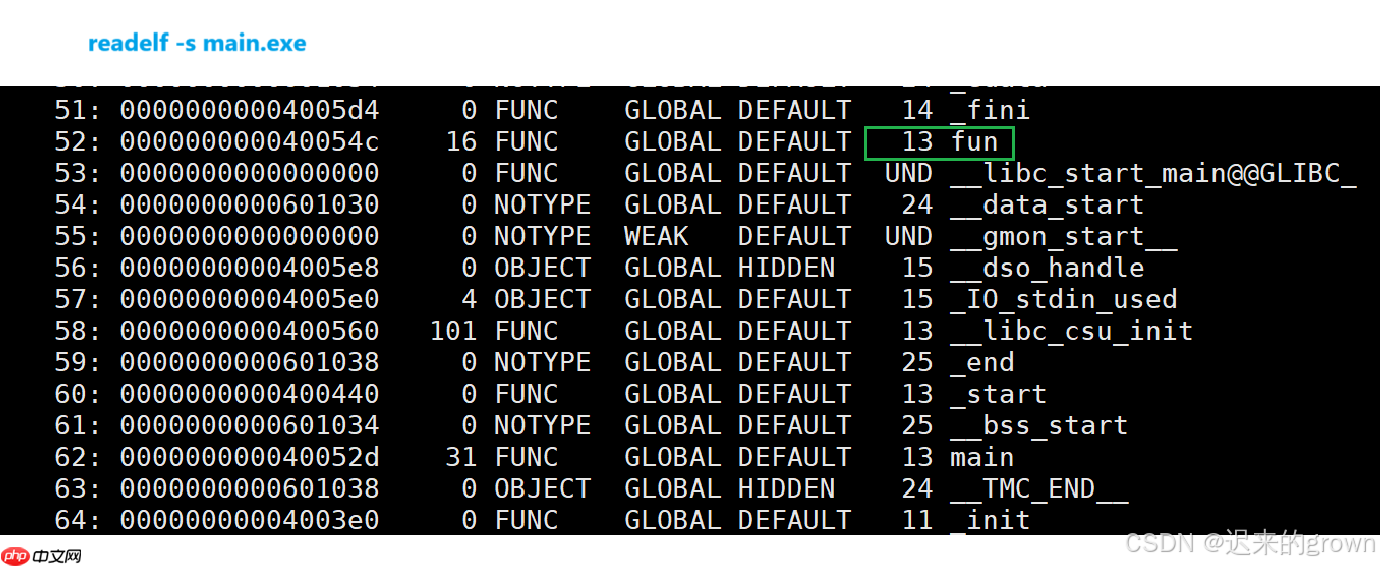
所以,链接的本质上就是编译之后的所有目标文件连同用到的一些静态库运行时库组合,形成一个独立的可执行文件。
当所有模块组合在一起之后,链接器就会根据我们的
.o
我们链接的过程中就会涉及到对目标文件
.o
.o
这里有一个问题:进程地址空间
mm_struct
vm_area_struct
我们对
.o
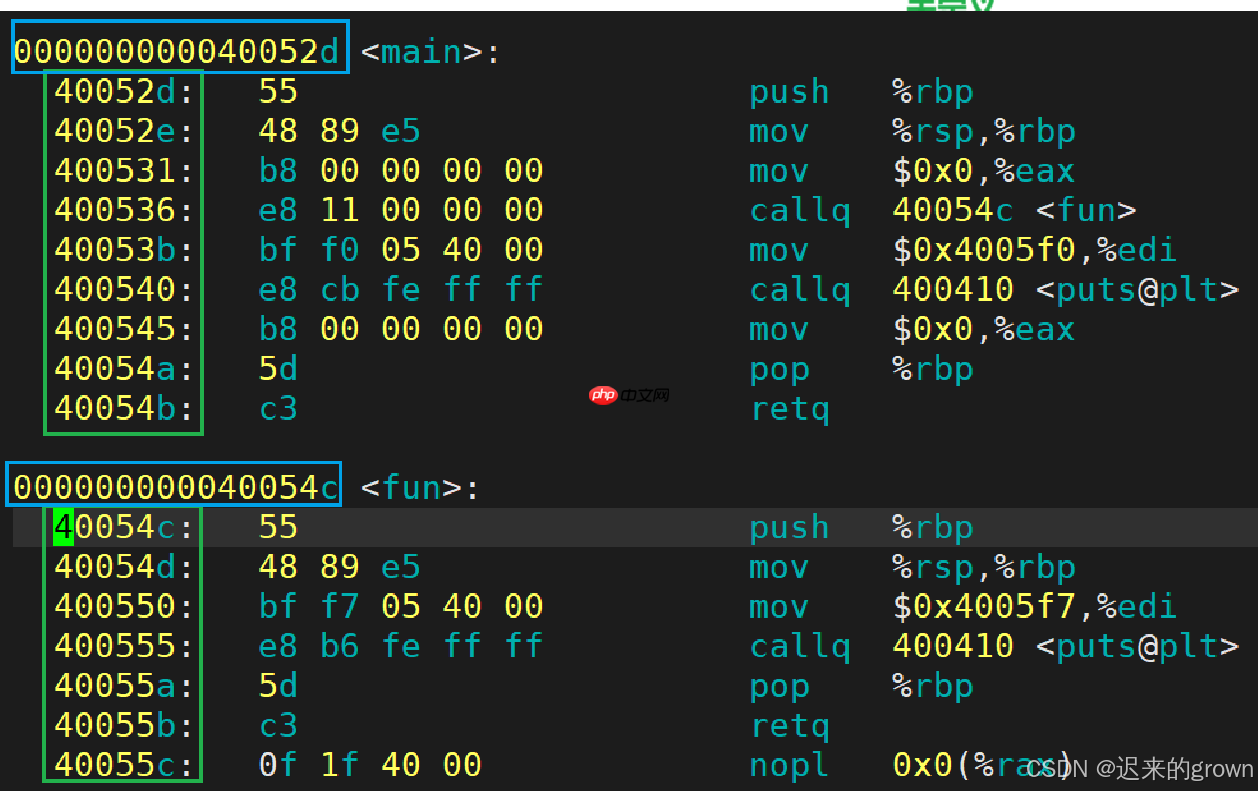
上图中最左侧就是ELF文件中的地址;严格意义上将,这种地址应该叫做逻辑地址:起始位置+偏移量。
而当我们把起始位置当做
0
所以,我们进程在创建时,虚拟地址空间
mm_struct
vm_arae_sruct
从ELF中的
segment
segment
vm_area_struct
[start , end]
所以虚拟地址,不仅操作系统要支持,而编译器也要支持。(因为程序在还没有加载到内存时,就已经进行统一编址了)
进程地址空间
所以,在程序运行时,该可执行程序要加载到内存;而进程的进程地址空间
mm_struct
这样进程才能被
CPU
CPU
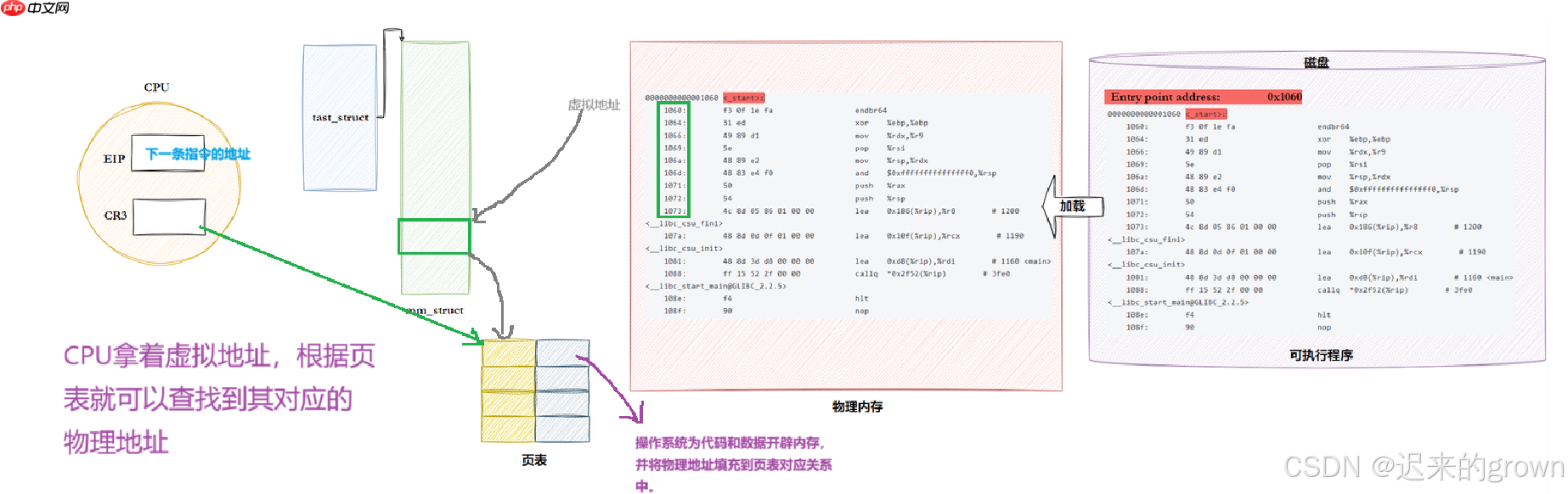
还记得在ELF格式的
ELF Header
Entry point address
CPU
EIP
CPU
CR3
所以在进程被调度时,就会把
Entry point address
CPU
EIP
CR3
CPU
动态链接,简单来说就是将可执行程序和库产生关联,然后在程序运行时再加载动态库;
这也是我们在动态链接我们自己的库,生成可执行,在运行时还需要让系统找到我们的库的原因。
程序在运行时,才会加载动态库,那进程如何看到我们的动态库呢?
了解了一个进程如何找到我们的动态库;我们还知道动态库也被称为共享目标文件,也就是说我们的库可以被多个进程共享的。
所以在我们进程去找自己依赖的库时,如果当前库已经被加载到内存了,当前进程就可以根据库文件的
struct file
struct path
path
struct dentry
inode
这样讲库映射到进程的地址空间中,这样多个进程就共享同一个库了;而在内存中库文件就只存在一份
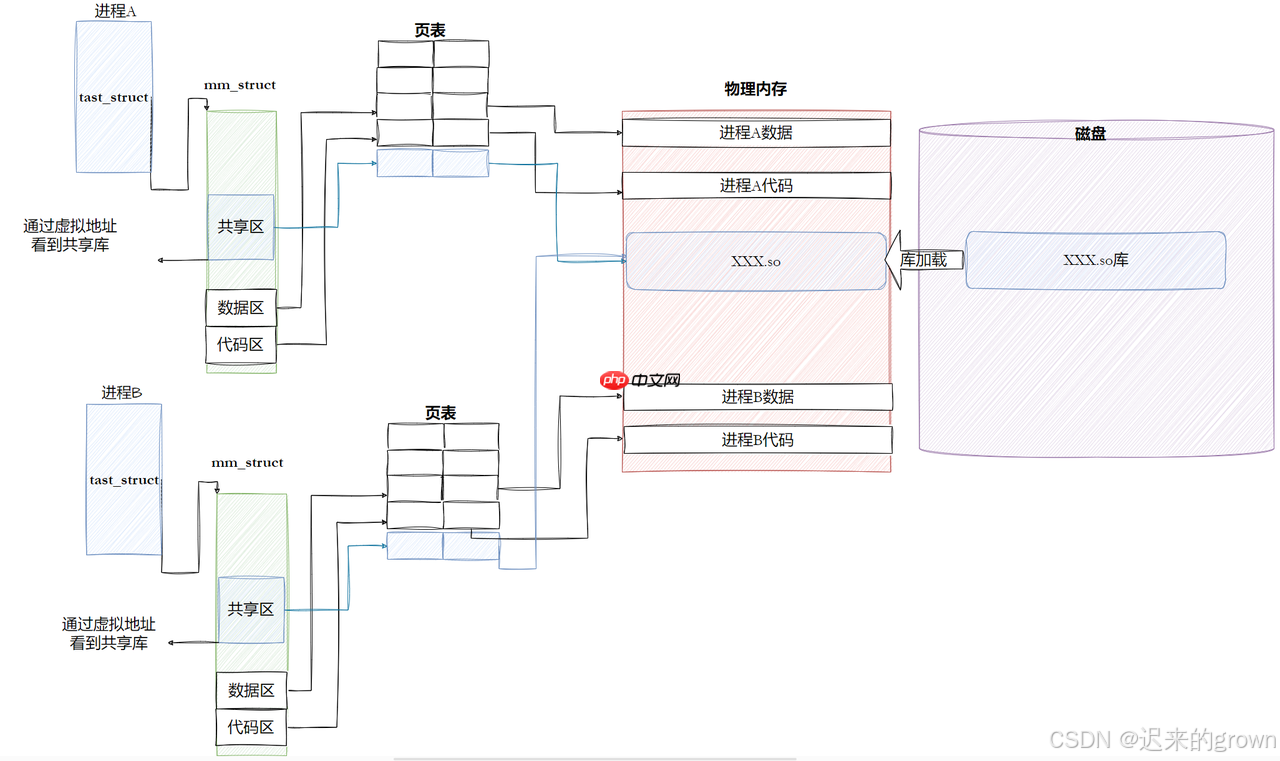
我们知道静态链接就是将静态库合并到我们的可执行程序中,这样静态链接形成的可执行不依赖库,就可以执行;按理来说应该比的链接更加方便。
但是,当我们静态库文件特别大,我们如果使用静态链接,这样形成的可执行都包含一份静态库代码;而当程序运行起来时,在内存中就势必会存在多份源文件代码。
再看动态链接,只是将可执行文件和动态库文件产生关联,在程序运行时才进行链接,可执行文件中不存在库代码;而且在内存中,多个进程可以共享一个动态库,在内存中也不会出现多份库代码。
那动态链接如何实现的呢?
可执行程序被编译器处理过在
C/C++
main
实际是程序的入口不是
main
_start
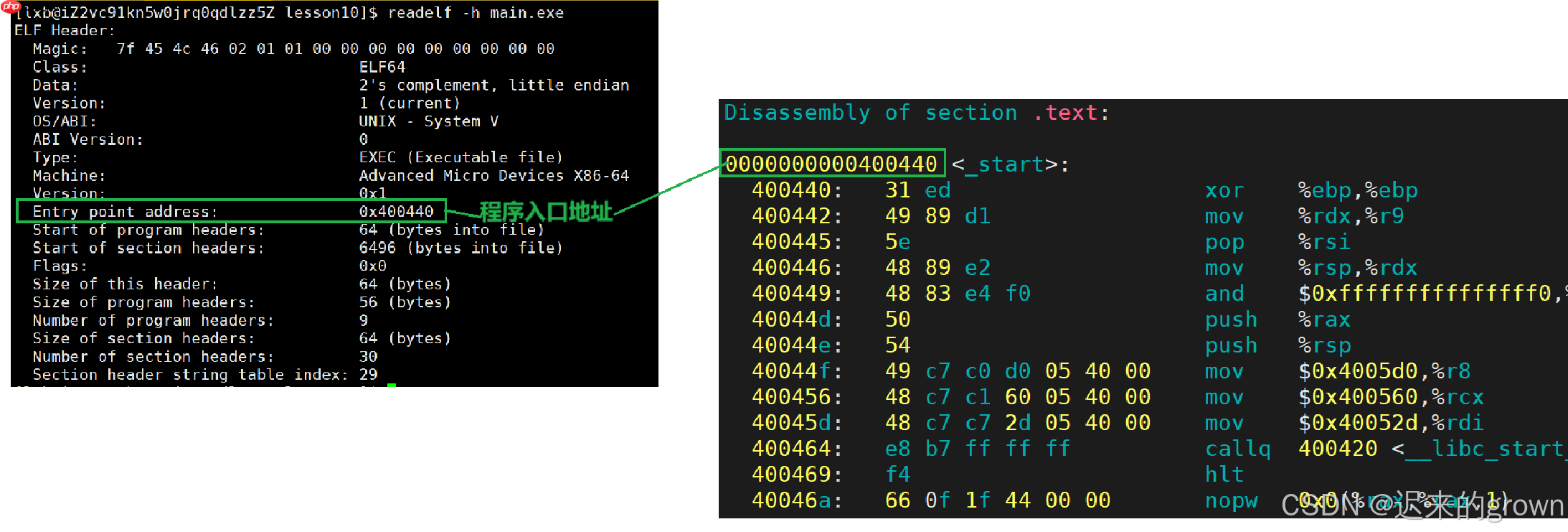
可以看到可执行程序的入口地址并不是
main
_start
Linux
_start
glibc
id
那
_start
_start
_libc_start_main
_start
libc_start_main
glibc
lib_start_main
main
lib_start_main
main
main
main
lib_start_main
_exit
动态链接器:负责在程序运行时加载动态库
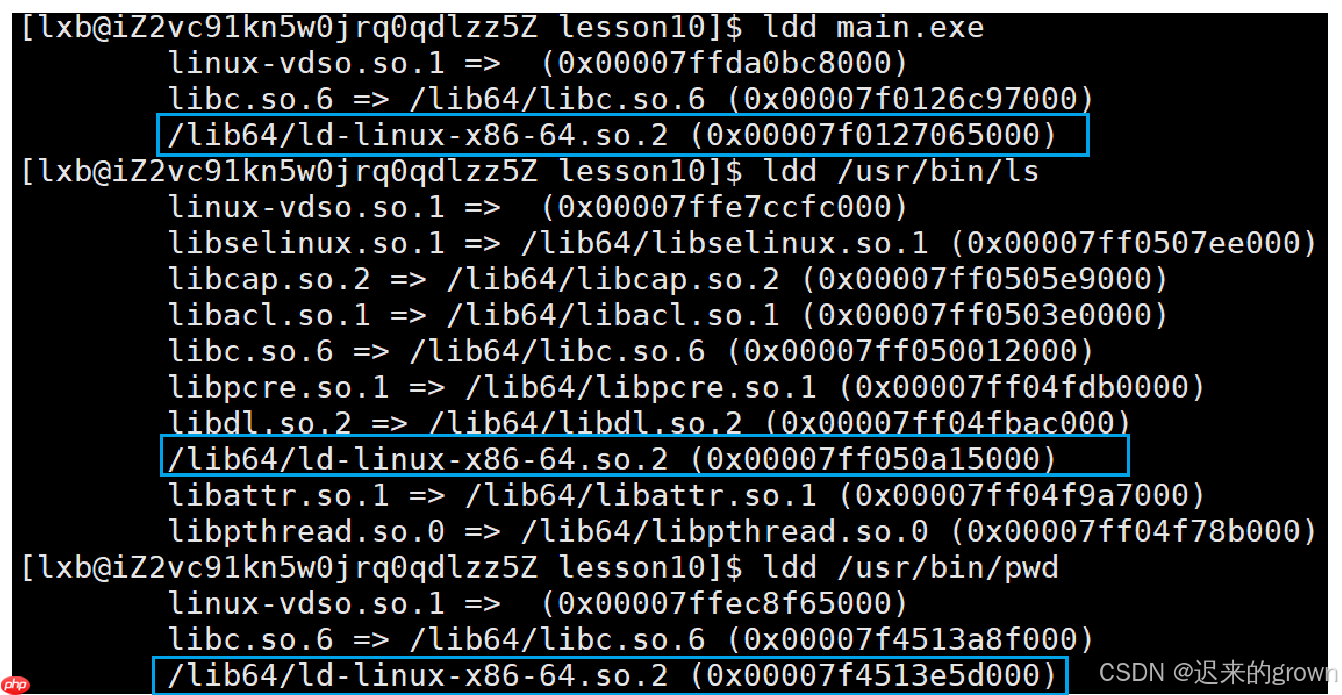
可以看到这里程序都依赖
ld-linux-x86-64.so.2
Linux
LD_LIBRARY_PATH
etc/ld.so.conf
缓存文件:
为了提高动态库的加载效率,Linux
/etc/ld.so.cache
说了这么多,那动态库该如何链接和加载的呢?我们的程序又是如何调用库函数呢?
那我们就清楚了,库映射到进程地址空间后,我们只需要知道库的起始虚拟地址和要调用方法的偏移量就可以找到库中的方法。
那也就是说,我们在动态链接的过程中,我们只需要记录下来调用库函数依赖的库名称,和该库函数中动态库中的偏移量地址即可。
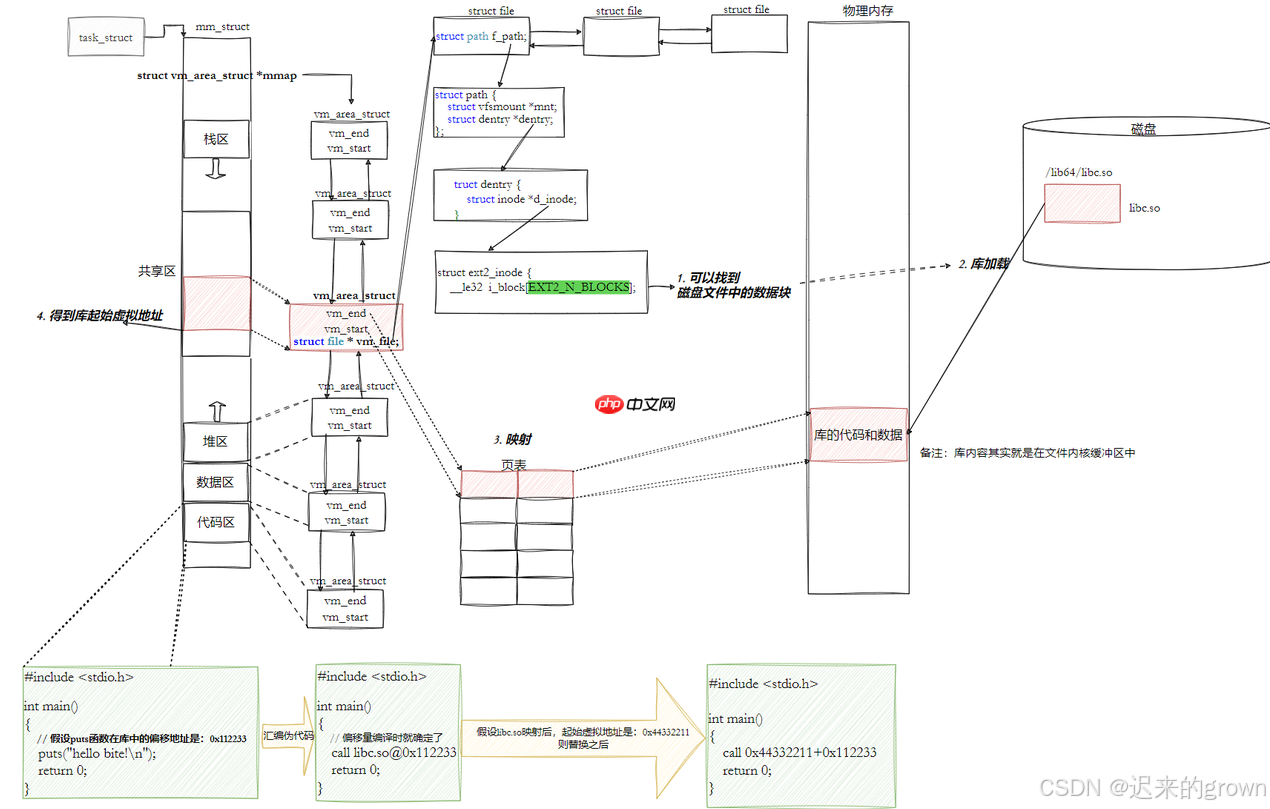
GOT
但是,我们知道代码区是只读的;那如何修改呢?代码区是不能修改的。
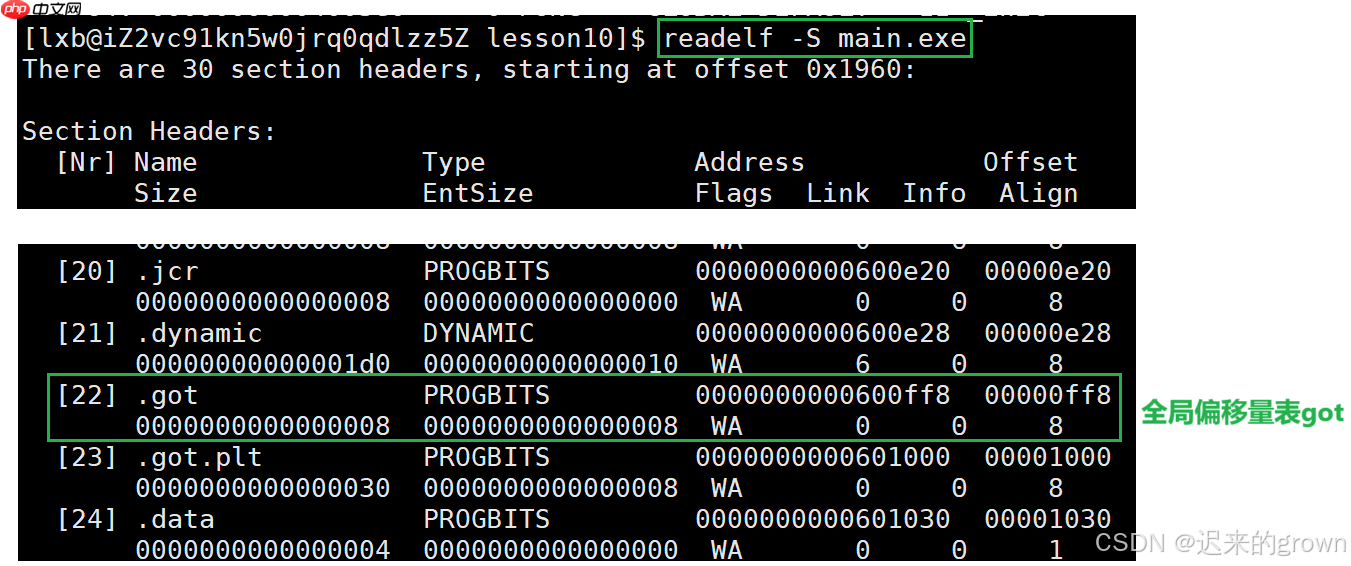
所以,在动态链接的时候,在可执行程序中就存在了全局偏移量表
GOT
这样执行加载时,库加载映射到进程的进程地址空间中,然后修改
GOT
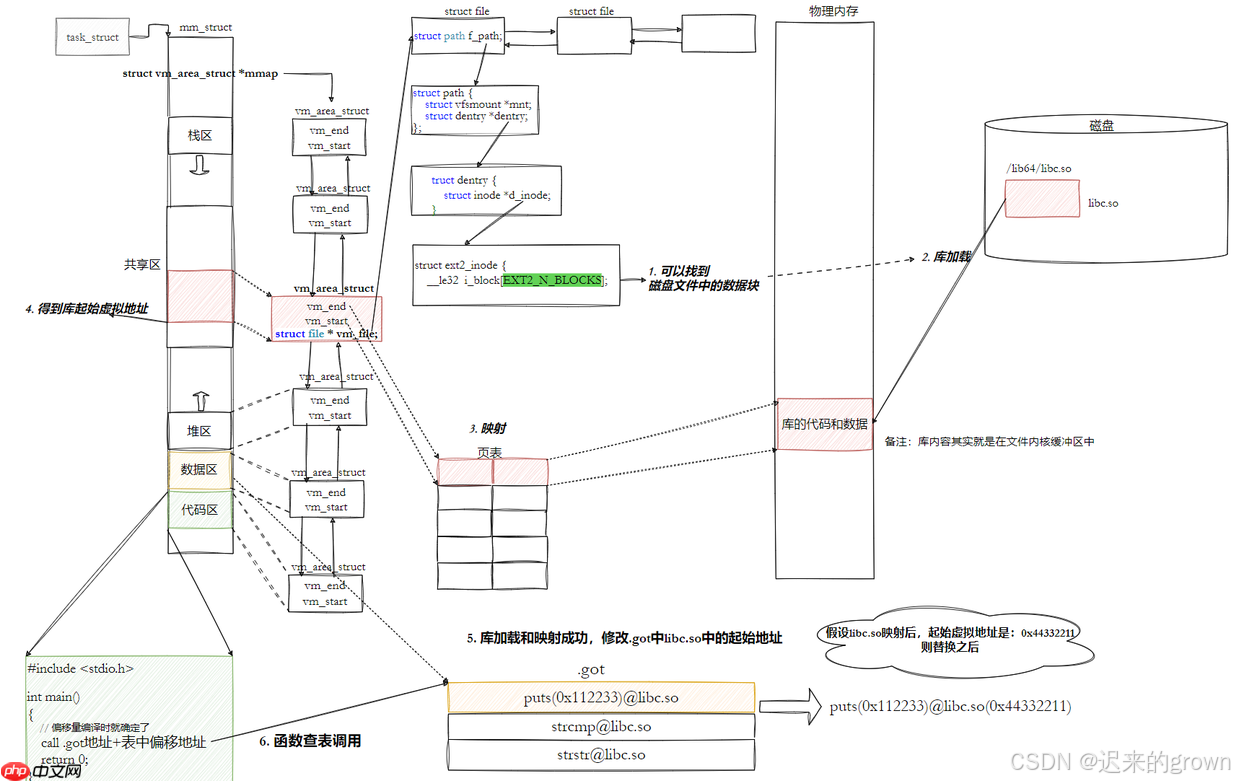
.so
GOT
.text
CPU
GOT
GOT
这种方式实现动态链接被称为 地址无关码; 简单来说就是:我们动态库不需要做任何修改,被加载到任意内存地址处都能正常运行,且能够被所有进程共享。 这也就是在制作动态库,生成
.o
-fPIC
plc
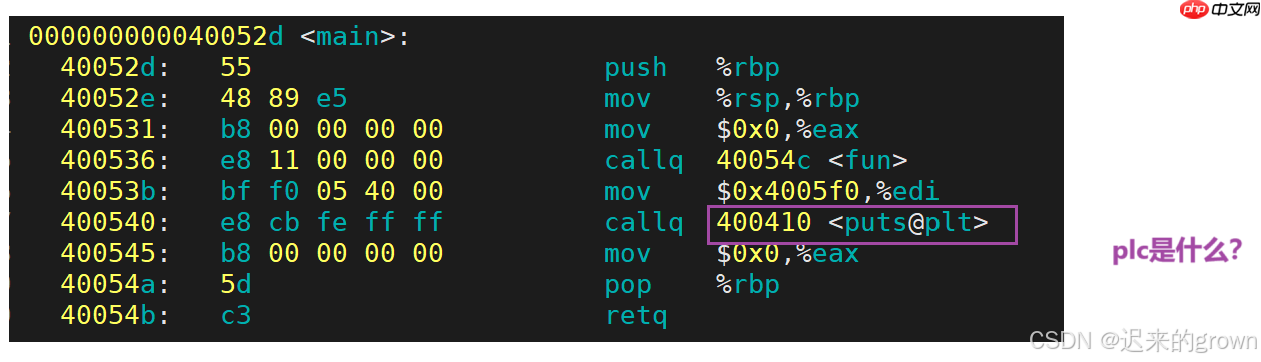
我们通过查看汇编代码可以发现,在进行库函数调用时,存在一个
plc
<puts@plc>
这里
plc
plc
我们知道动态链接在程序加载时需要进程大量函数地址的重定位(修改大量的函数地址),显然是非常耗费时间的;并且有很多函数我们并没有调用。
为了进一步降低消耗,操作系统就会做优化:延迟绑定也就是
plc
最后在这里补充一点:库函数也会调用其他库函数,也就是库之间也存在依赖。
到这里本篇文件内容就大致结束了
简单总结:
ELF文件:ELF Header
program Header Table
Section Header Table
Section
0
mm_struct
vm_area_struct
plc
GOT
/stup
GOT
以上就是深入了解linux系统—— 库的链接和加载的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 186
186






















