
在pandas中实现数据表的行列转置最直接的方式是使用.t属性或.transpose()方法。1. .t属性是最简洁的方法,直接在dataframe对象后加.t即可完成转置;2. .transpose()方法与.t效果相同,但提供更明确的函数调用形式。转置后数据类型可能变为通用类型如object,需检查并使用astype()转换;原来的行索引变列索引,列索引变行索引,可使用reset_index()调整。处理大数据时可能内存不足,可通过分块处理、使用dask、优化数据类型或避免不必要的转置解决。

Pandas中实现数据表的行列转置,最直接的方式就是使用
.T
.transpose()

解决方案
在Pandas中,行列转置主要通过以下两种方式实现:

.T 属性: 这是最简洁的方法,直接在DataFrame对象后加上
.T
import pandas as pd
# 创建一个示例DataFrame
data = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data)
# 使用.T进行转置
df_transposed = df.T
print("原始DataFrame:\n", df)
print("\n转置后的DataFrame:\n", df_transposed).transpose() 方法: 这个方法与
.T

import pandas as pd
# 创建一个示例DataFrame
data = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data)
# 使用.transpose()进行转置
df_transposed = df.transpose()
print("原始DataFrame:\n", df)
print("\n转置后的DataFrame:\n", df_transposed)Pandas转置后数据类型会变吗?
是的,转置操作可能会影响DataFrame中数据的类型。如果原始DataFrame中包含多种数据类型,转置后Pandas可能会尝试将所有数据转换为一种通用类型,通常是
object
例如,如果原始数据包含整数和字符串,转置后所有数据都可能变成字符串类型。因此,在进行转置操作后,最好检查数据类型是否符合预期,并根据需要进行类型转换,比如使用
astype()
Pandas转置后索引会发生什么变化?
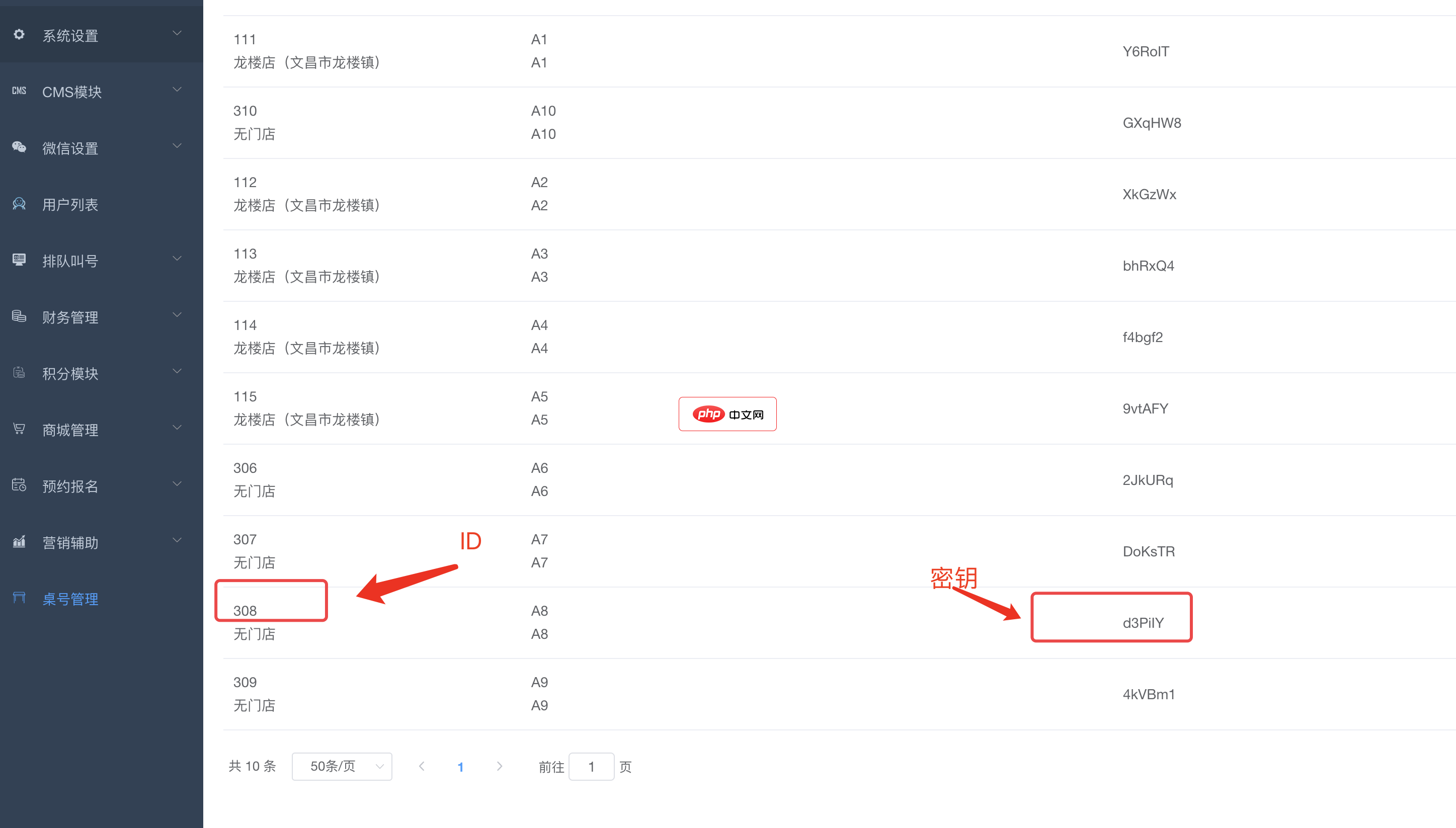
bee餐饮点餐外卖小程序是针对餐饮行业推出的一套完整的餐饮解决方案,实现了用户在线点餐下单、外卖、叫号排队、支付、配送等功能,完美的使餐饮行业更高效便捷!功能演示:1、桌号管理登录后台,左侧菜单 “桌号管理”,添加并管理你的桌号信息,添加以后在列表你将可以看到 ID 和 密钥,这两个数据用来生成桌子的二维码2、生成桌子二维码例如上面的ID为 308,密钥为 d3PiIY,那么现在去左侧菜单微信设置
 1
1

转置后,原来的行索引会变成列索引,而原来的列索引会变成行索引。这意味着你需要重新考虑如何访问和操作数据。例如,如果你原来使用行索引来定位数据,转置后就需要使用列索引。
如果你的原始DataFrame有MultiIndex(多层索引),转置操作也会相应地调整索引的层级结构。理解索引的变化对于正确地使用转置后的数据至关重要。如果转置后索引混乱,可以考虑使用
reset_index()
Pandas大数据量转置会遇到什么问题?如何解决?
当处理非常大的DataFrame时,转置操作可能会消耗大量的内存,甚至导致程序崩溃。这是因为转置需要在内存中创建一个新的DataFrame,其大小与原始DataFrame相同。
解决这个问题的一些方法包括:
分块处理: 将大的DataFrame分成小的块,分别进行转置,然后将结果合并。这可以通过循环遍历DataFrame的行或列来实现。
使用Dask: Dask是一个并行计算库,可以处理大于内存的数据集。你可以使用Dask DataFrame来执行转置操作,它会自动将数据分成小的块并在多个核心上并行处理。
优化数据类型: 确保DataFrame使用最有效的数据类型。例如,如果你的数据包含小的整数,使用
int8
int16
int64
避免不必要的转置: 在某些情况下,可能可以通过重新组织代码来避免完全转置DataFrame。例如,你可以使用
melt()
pivot()
以上就是Pandas中如何实现数据表的行列转置?的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 962
962






















