
8月22日,阿里通义正式推出全新一代端到端语音识别大模型fun-asr。该模型在上下文理解与高精度语音转写方面实现显著突破,在家装、保险等多个行业场景中,语音识别准确率提升均超过15%。目前,fun-asr已广泛应用于会议字幕生成、实时同传、智能纪要生成及语音助手等实际场景,后续将登陆阿里云百炼平台,进一步赋能开发者与企业用户。
Fun-ASR是一款由大语言模型驱动的语音识别系统,依托自研语音算法与基于监督微调的Qwen3模型训练而成,融合了先进的模型架构与文本模态对齐技术,有效保留并增强大模型的语言理解能力。同时,模型集成了RAG(检索增强生成)方案,支持自动化音频信息检索,最多可导入1000余个自定义热词。借助这一能力,系统可根据输入音频内容动态检索相关领域术语、文档资料及历史对话记录,显著提升特定行业关键词的识别准确率。
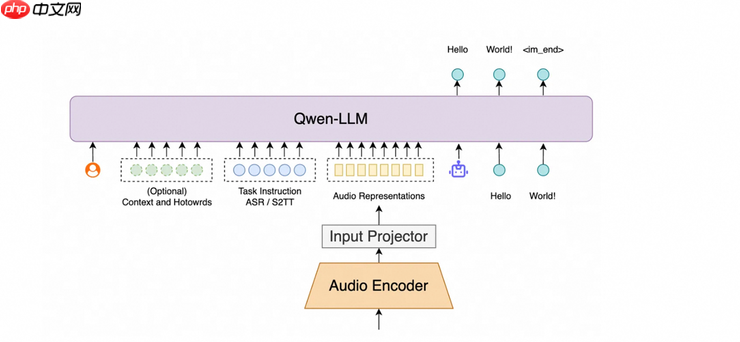
Fun-ASR架构图
针对语音识别中常见的识别错误、噪声干扰、语种混杂以及“幻觉”生成等问题,通义团队在模型训练过程中创新性地引入强化学习(RL)技术,有效抑制识别过程中的错误输出,显著提升系统的稳定性与准确性。在四川话、粤语、闽南语等多种方言场景下,Fun-ASR表现优于同类产品。此外,模型对远场拾音与近场降噪等复杂声学环境具备出色的适应能力,无论是在会议室、办公区,还是超市、户外等嘈杂环境中,均能保持高水平的识别性能。
在训练数据层面,Fun-ASR依托超过一亿小时的海量音频数据,覆盖互联网、科技、家装、畜牧、汽车等十余个行业领域的专业术语,实现了多垂直领域识别准确率的大幅提升。实测结果显示,该模型在保险行业的识别准确率相较之前提升达18%,在家装、畜牧等领域也实现了15%至20%的显著进步。
在音频技术布局方面,通义实验室已相继发布语音生成大模型Cosyvoice、端到端多模态音频大模型MinMo、以及音频生成模型ThinkSound,构建起涵盖语音识别、语音合成、音频生成与理解的全栈能力体系。
以上就是阿里通义推新一代语音模型Fun-ASR,垂直领域识别准确率提升15%以上的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 922
922




















