
蚂蚁集团与中国人民大学携手推出业界首个原生moe架构的扩散语言模型(dllm)——llada-moe,成功在约20t数据上完成从零开始的大规模训练,充分验证了该架构在工业级应用中的扩展性与稳定性。该模型在性能上超越此前发布的稠密型扩散语言模型llada1.0/1.5和dream-7b,表现媲美同等规模的自回归模型,同时具备数倍推理速度优势。项目将于近期全面开源,助力全球ai社区推动dllm技术进步。
9月11日,在2025 Inclusion·外滩大会上,这一突破性成果正式发布。中国人民大学高瓴人工智能学院副教授李崇轩,以及蚂蚁集团通用人工智能研究中心主任、西湖大学特聘研究员、西湖心辰创始人蓝振忠共同出席发布仪式。

(中国人民大学与蚂蚁集团联合发布首款原生MoE结构扩散语言模型LLaDA-MoE)
据悉,LLaDA-MoE采用非自回归的掩码扩散机制,首次通过原生训练方式在MoE架构上实现大规模语言建模能力,达到与Qwen2.5相匹敌的语言智能水平,涵盖上下文学习、指令遵循、代码生成及数学推理等核心任务,打破了“语言模型必须依赖自回归生成”的传统观念。
实验结果显示,LLaDA-MoE在代码生成、数学解题、智能体交互等多项任务中显著优于LLaDA1.0/1.5和Dream-7B等现有扩散模型,整体性能接近甚至部分超越Qwen2.5-3B-Instruct这类自回归模型。值得注意的是,该模型仅激活1.4B参数即可实现相当于3B稠密模型的效果,展现出卓越的效率优势。
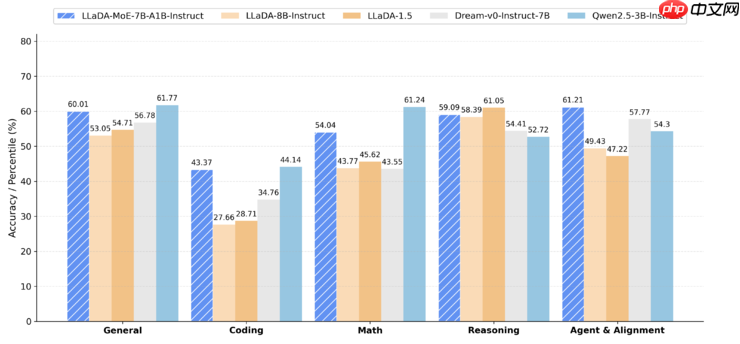
(LLaDA-MoE多维度性能对比)
“LLaDA-MoE的成功训练,证明了dLLM在大规模工业场景下的可行性与可扩展性,标志着我们在构建更大规模扩散模型的道路上迈出了关键一步。”蓝振忠在现场表示。
李崇轩指出:“尽管过去两年大模型能力飞速发展,但一些根本性问题仍未解决。这源于当前主流模型普遍采用自回归生成方式——逐个token顺序输出,导致无法有效捕捉文本内部的双向依赖关系。”
为突破这一瓶颈,研究者们开始探索并行解码的扩散语言模型路径。然而,现有的dLLM大多基于稠密架构,难以继承自回归模型中MoE“扩大参数、控制计算量”的优势。在此背景下,蚂蚁与人大联合团队率先实现技术跨越,推出首个原生MoE结构的扩散语言模型LLaDA-MoE。
蓝振忠进一步透露:“我们将在不久后向全球开放模型权重及自研推理框架,携手开发者社区共同推进AGI的发展。”
据了解,双方团队历时三个月,在LLaDA-1.0基础上重构训练流程,并依托蚂蚁自研的分布式训练框架ATorch,集成EP并行等多种加速技术,利用Ling2.0基础模型的数据资源,在负载均衡、噪声采样漂移等关键技术难题上取得突破,最终以7B-A1B(总参数7B,激活1.4B)的MoE架构高效完成了约20T数据的训练任务。
在蚂蚁自主研发的统一评测体系下,LLaDA-MoE在HumanEval、MBPP、GSM8K、MATH、IFEval、BFCL等17项权威基准测试中平均提升8.4%,相较LLaDA-1.5领先达13.2%,整体表现与Qwen2.5-3B-Instruct持平。实验结果再次印证“MoE放大器”定律在扩散语言模型领域同样适用,为未来10B至100B级别稀疏模型的研发提供了清晰的技术路线。
此外,除公开模型权重外,蚂蚁还将同步开源专为dLLM优化设计的高性能推理引擎。相比NVIDIA官方fast-dLLM方案,新引擎实现了显著提速。相关代码、技术文档将陆续在GitHub与Hugging Face平台发布。
蓝振忠强调,蚂蚁将持续深耕基于扩散语言模型的AGI研究,下一阶段将联合学术界与全球AI生态,共同探索通往通用人工智能的新路径。“自回归并非唯一选择,扩散模型同样有望成为AGI发展的主航道。”他总结道。
以上就是挑战主流认知!蚂蚁、人大在2025外滩大会发布行业首个原生MoE扩散语言模型的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 917
917






















