
今天我们将深入探讨flink的流处理概念和流批一体的api,了解如何使用flink进行数据处理。以下是今天的学习目标:
流处理概念
流处理强调数据处理的及时性,适合处理如网站数据访问、被爬虫爬取等实时数据。流处理数据是无界的,通过窗口操作可以划分数据的边界进行计算。相比之下,批处理数据是有界的。Flink在1.12版本时开始支持流批一体,既可以处理流数据也可以处理批数据。

程序结构
Flink的编程模型包括三个主要部分:Source、Transformation和Sink。
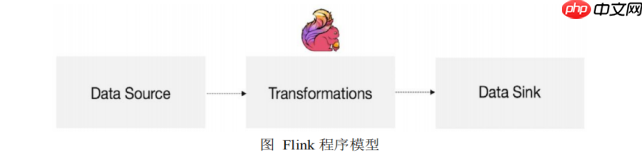
Source
Source是数据的入口,Flink支持从文件、数据库等多种数据源读取数据。以下是基于文件和数据集合的Source示例:
package cn.itcast.sz22.day02;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* Author itcast
* Date 2021/5/5 9:50
* env.readTextFile(本地/HDFS文件/文件夹);//压缩文件也可以
*/
public class FileSourceDemo {
public static void main(String[] args) throws Exception {
//创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取文件 hdfs://node1:8020/user/root/xxx.txt
//读取通过 gzip 压缩的 gz 文件
DataStreamSource<String> source1 = env.readTextFile("data/hello.txt");
DataStreamSource<String> source2 = env.readTextFile("D:\_java_workspace\sz22\data\hello.txt.gz");
//打印文本
source1.print();
source2.print("source2:");
//执行流环境
env.execute();
}
}基于数据集合的Source:
package cn.itcast.sz22.day02;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
/**
* Author itcast
* Date 2021/5/5 10:32
* Desc TODO
*/
public class MySQLSourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//1.env 设置并行度为 1
env.setParallelism(1);
//2.source,创建连接MySQL数据源 数据源,每2秒钟生成一条数据
DataStreamSource<Student> source = env.addSource(new RichSourceFunction<Student>() {
Connection conn;
PreparedStatement ps;
boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
//连接数据源
conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false"
, "root", "123456");
//编写读取数据表的sql
String sql = "select `id`,`name`,age from t_student";
//准备 preparestatement SQL
ps = conn.prepareStatement(sql);
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
while (flag) {
ResultSet rs = ps.executeQuery();
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
Student student = new Student(id, name, age);
ctx.collect(student);
}
}
}
@Override
public void cancel() {
flag = false;
}
@Override
public void close() throws Exception {
ps.close();
conn.close();
}
});
//3.打印数据源
//4.执行
//创建静态内部类 Student ,字段为 id name age
//创建静态内部类 MySQLSource 继承RichParallelSourceFunction
// 实现 open 方法
// 获取数据库连接 mysql5.7版本 jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false
// 实现 run 方法
source.print();
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Student {
private int id;
private String name;
private int age;
}
}Transformation
Transformation是数据处理的核心,Flink提供了多种转换操作,如map、filter、reduce等。以下是一个示例,展示如何对流数据中的单词进行统计并排除敏感词:
package cn.itcast.sz22.day02;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Author itcast
* Date 2021/5/5 9:59
* 1.filter过滤 将单词中 heihei 单词过滤掉
* 2.reduce聚合
*/
public class SocketSourceFilterDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.source socketSource
DataStreamSource<String> source = env.socketTextStream("192.168.88.100", 9998);
//3.处理数据-transformation
SingleOutputStreamOperator<Tuple2<String, Integer>> result = source
.flatMap((String value, Collector<String> out) -> Arrays
.stream(value.split(" ")).forEach(out::collect))
.returns(Types.STRING)
//过滤掉 包含 heihei 单词的所有信息 boolean filter(T value)
.filter(word-> !word.equals("heihei"))
.map(value -> Tuple2.of(value, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(t -> t.f0)
//.sum(1);
//T reduce(T value1, T value2)
// hadoop,1 hadoop,1 => hadoop,1+1
.reduce((Tuple2<String, Integer> a,Tuple2<String, Integer> b)->Tuple2.of(a.f0,a.f1+b.f1));
//3.1每一行数据按照空格切分成一个个的单词组成一个集合
//3.2对集合中的每个单词记为1
//3.3对数据按照单词(key)进行分组
//3.4对各个组内的数据按照数量(value)进行聚合就是求sum
//4.输出结果-sink
result.print();
//5.触发执行-execute
env.execute();
}
}合并和拆分操作也是Transformation的一部分:
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
/**
* Author itcast
* Date 2021/5/5 11:24
* 将两个String类型的流进行union
* 将一个String类型和一个Long类型的流进行connect
* */
public class UnionAndConnectDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//2.Source
DataStream<String> ds1 = env.fromElements("hadoop", "spark", "flink");
DataStream<String> ds2 = env.fromElements("hadoop", "spark", "flink");
DataStream<Long> ds3 = env.fromElements(1L, 2L, 3L);
//3. transformation
//3.1 union
DataStream<String> union = ds1.union(ds2);
union.print("union:");
//3.2 connect
ConnectedStreams<String, Long> connect = ds1.connect(ds3);
SingleOutputStreamOperator<String> source2 = connect.map(new CoMapFunction<String, Long, String>() {
@Override
public String map1(String value) throws Exception {
return "string->string:" + value;
}
@Override
public String map2(Long value) throws Exception {
return "Long->Long:" + value;
}
});
//打印输出
source2.print("connect:");
env.execute();
}
}拆分数据流的示例:
package cn.itcast.sz22.day02;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
/**
* Author itcast
* Date 2021/5/5 11:35
* 对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
*/
public class SplitStreamDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
//2.Source 比如 1-20之间的数字
DataStreamSource<Long> source = env.fromSequence(1, 20);
//定义两个输出tag 一个奇数 一个偶数,指定类型为Long
OutputTag<Long> odd = new OutputTag("odd", TypeInformation.of(Long.class));
OutputTag<Long> even = new OutputTag("even", TypeInformation.of(Long.class));
//对source的数据进行process处理区分奇偶数
SingleOutputStreamOperator<Long> processDS = source.process(new ProcessFunction<Long, Long>() {
@Override
public void processElement(Long value, Context ctx, Collector<Long> out) throws Exception {
if (value % 2 == 0) {
ctx.output(even, value);
} else {
ctx.output(odd, value);
}
}
});
//3.获取两个侧输出流
DataStream<Long> evenDS = processDS.getSideOutput(even);
DataStream<Long> oddDS = processDS.getSideOutput(odd);
//4.sink打印输出
evenDS.printToErr("even");
oddDS.print("odd");
//5.execute
env.execute();
}
}Sink
Sink是数据的出口,Flink支持将数据输出到控制台、文件、数据库等多种存储介质。以下是将数据sink到MySQL的示例:
package cn.itcast.sz22.day02;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
/**
* Author itcast
* Date 2021/5/5 16:00
* 将 Student 集合数据sink到MySQL数据库中
*/
public class SinkMySQLDemo01 {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.Source 定义 Student 对象
DataStream<Student> studentDS = env.fromElements(new Student(null, "tonyma", 18));
studentDS.addSink(new RichSinkFunction<Student>() {
Connection conn;
PreparedStatement ps;
boolean flag = true;
@Override
public void open(Configuration parameters) throws Exception {
//初始化操作,添加连接MySQL
conn = DriverManager.getConnection("jdbc:mysql://192.168.88.100:3306/bigdata?useSSL=false"
, "root", "123456");
String sql="INSERT INTO t_student(`id`,`name`,`age`) values(null,?,?)";
ps = conn.prepareStatement(sql);
}
@Override
public void invoke(Student value, Context context) throws Exception {
ps.setString(1,value.getName());
ps.setInt(2,value.getAge());
ps.executeUpdate();
}
@Override
public void close() throws Exception {
ps.close();
conn.close();
}
});
//3.Transformation 暂时不需要
//4.Sink 实现自定义 MySQL sink
//5.execute
//创建 Student 类,包含3个字段 id name age
//创建 MySQLSink 类继承 RichSinkFunction
//实现 open invoke close 方法
env.execute();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class Student {
private String id;
private String name;
private int age;
}
}Flink连接器Connectors
Flink提供了多种连接器,可以与外部系统如JDBC、Kafka、Redis等进行集成。以下是使用Kafka和Redis的示例:
Kafka
package cn.itcast.sz22.day02;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
/**
* Author itcast
* Date 2021/5/5 17:23
* 需求:使用flink-connector-kafka_2.12中的FlinkKafkaConsumer消费Kafka中的数据做WordCount
* 需要设置如下参数:
* 1.订阅的主题
* 2.反序列化规则
* 3.消费者属性-集群地址
* 4.消费者属性-消费者组id(如果不设置,会有默认的,但是默认的不方便管理)
* 5.消费者属性-offset重置规则,如earliest/latest...
* 6.动态分区检测(当kafka的分区数变化/增加时,Flink能够检测到!)
* 7.如果没有设置Checkpoint,那么可以设置自动提交offset,后续学习了Checkpoint会把offset随着做Checkpoint的时候提交到Checkpoint和默认主题中
*/
public class FlinkKafkaConsumerDemo {
public static void main(String[] args) throws Exception {
//1.env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启checkpoint
env.enableCheckpointing(5000);
//2.Source
Properties props = new Properties();
props.setProperty("bootstrap.servers", "node1:9092");
props.setProperty("group.id", "flink");
props.setProperty("auto.offset.reset","latest");
props.setProperty("flink.partition-discovery.interval-millis","5000");//会开启一个后台线程每隔5s检测一下Kafka的分区情况
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "2000");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer("flink_kafka"
, new SimpleStringSchema(), props);
consumer.setStartFromEarliest();
DataStreamSource<String> source = env.addSource(consumer).setParallelism(1);
source.print();
env.execute();
}
}Redis
//-1.创建RedisSink之前需要创建RedisConfig
//连接单机版Redis
FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder()
.setHost("node1").build();
result.addSink(new RedisSink<>(config, new RedisMapperEx()));
env.execute();
// * 最后将结果保存到Redis 实现 FlinkJedisPoolConfig
// * 注意:存储到Redis的数据结构:使用hash也就是map
// * key value
// * WordCount (单词,数量)
<p>public static class RedisMapperEx implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.HSET, "hashOpt");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> data) {
return data.f0;
}
@Override
public String getValueFromData(Tuple2<String, Integer> data) {
return data.f1 + "";
}
}通过以上内容的学习,您将能够掌握Flink的基本使用方法,并能够利用Flink进行流处理和批处理的开发。
以上就是2021年最新最全Flink系列教程_Flink原理初探和流批一体API(二)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 871
871























