
在机器人学习领域,让 ai 真正“看懂”三维世界始终是一个核心挑战。
现有的视觉语言动作(VLA)模型大多基于预训练的视觉语言模型(VLM),仅利用 2D 图像-文本对进行训练,缺乏对真实操作至关重要的 3D 空间感知能力。
虽然当前一些方法通过引入显式深度信息来增强模型,但这类方案通常依赖额外的深度传感器或复杂的深度估计网络,带来了部署复杂、成本高以及噪声干扰等实际问题。

为解决这一难题,上海交通大学与剑桥大学联合提出了一种轻量化的 VLA 增强框架——Evo-0。该方法无需任何显式深度输入或外部硬件,而是通过隐式注入 3D 几何先验知识,显著提升模型的空间理解能力。
Evo-0 利用视觉几何基础模型 VGGT,从多视角 RGB 图像中提取深层的 3D 结构信息,并将其融合进原有的视觉语言模型中,从而实现对物体空间布局和几何关系的精准建模。
在 RLBench 仿真实验中,Evo-0 在五个需要精细空间操作的任务上表现优异,平均成功率比基线模型 π0 提升 15%,相比 openvla-oft 更高出 31%。

其核心技术在于将 VGGT 作为空间编码器,提取其在训练过程中生成的 t3^D token,这些 token 蕴含了丰富的深度上下文和跨视角的空间对应信息。
通过设计一个 cross-attention 融合模块,以 ViT 提取的 2D 视觉 token 作为 query,VGGT 输出的 3D token 作为 key 和 value,实现 2D 与 3D 表征的有效融合,增强模型对复杂空间结构的理解。

融合后的特征与语言指令一同输入冻结主干的 VLM 模型,动作则由 flow-matching 策略生成。训练过程中仅微调融合模块、LoRA 适配层及动作专家部分,大幅降低了计算开销。
研究团队在 5 个 RLBench 模拟任务和 5 个真实机器人操作任务上进行了全面验证,并在 5 种不同干扰条件下评估鲁棒性。实验结果表明,Evo-0 在各类设置下均展现出更强的空间感知能力,性能全面超越现有先进 VLA 模型。
此外,在超参数分析实验中,团队重点考察了训练步数与执行步数对任务成功率的影响。结果显示,仅用 15k 步训练的 Evo-0 就已超过训练 20k 步的 π0 模型,证明其具备更高的学习效率。

在真实机器人实验中,设置了五项对空间精度要求极高的任务:目标居中放置、插孔、密集抓取、置物架放置和透明物体操作。
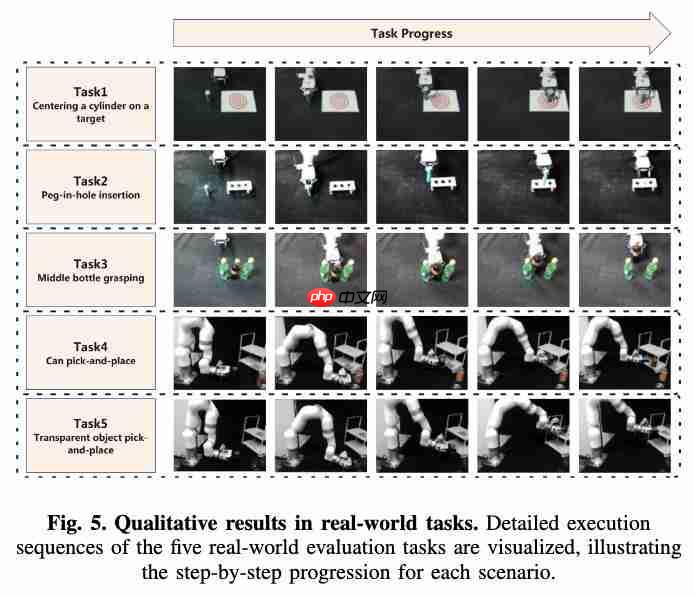
Evo-0 在所有任务中均优于基线 π0,平均成功率提升达 28.88%。尤其在插孔和透明物体抓取任务中,展现了对复杂空间关系的深刻理解与高精度操控能力。

鲁棒性测试涵盖五类干扰:(1)新增未见干扰物,(2)背景颜色变化,(3)目标位置偏移,(4)目标高度变动,(5)相机视角改变。Evo-0 在各项干扰下均保持稳定表现,且显著优于 π0。

综上所述,Evo-0 的核心创新在于借助 VGGT 提取丰富的空间语义信息,规避了深度估计误差与专用传感器依赖,以即插即用的方式增强 VLA 模型的空间建模能力。该方法训练高效、部署灵活,为通用机器人智能策略的发展提供了新的可行路径。
论文链接:https://www.php.cn/link/5fa5ca950fb704c977027ddfc2ee7e3f
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
量子位智库 AI100 季度榜单征集中!征集截至 10 月 10 日。欢迎提名 2025 年 Q3「AI 100」双榜单产品~
一键关注 点亮星标
科技前沿进展每日见
以上就是机器人感知大升级!轻量化注入几何先验,成功率提升 31%的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 596
596



















