
感谢网友 zerodert 的线索投递!
10 月 14 日,小米和北京大学联合署名的论文发表于 arxiv,曾被曝获小米集团创始人兼 ceo 雷军以千万年薪招募的 deepseek“天才少女”罗福莉,出现在了这篇论文的通讯作者之列,但值得注意的是,论文作者中并没有标注罗福莉属于小米大模型团队。

通讯作者中的罗福莉是 95 后,她本科就读于北京师范大学计算机专业,硕士毕业于北京大学计算语言学研究所计算语言学专业。随后罗福莉曾在阿里巴巴达摩院主导开发了多语言预训练模型 VECO,并推动了 AliceMind 的开源工作,2022 年入职 DeepSeek,参与了 MoE 大模型 DeepSeek-V2 的研发。去年年底,小米被曝以千万年薪挖角 DeepSeek-V2 核心开发者之一罗福莉,使其冲上热搜,但双方至今都未公开声明是否正式入职小米。

这篇论文提出了提升 MoE 模型强化学习训练的新方法 Rollout Routing Replay(R3)。实验结果证明,R3 的整体性能优于 GRPO、TIS 这类强化学习领域提升模型性能的优化算法,且引入 R3 的所有组合方法全过程无崩盘,训练过程中训练-推理 KL 散度等始终较低,在不影响训练速度的情况下,使得极端 token 比例减少一个量级。
当下,强化学习已成为提升大语言模型能力的关键方法。然而,在 MoE 模型中,路由机制往往会引入不稳定性,甚至导致强化学习训练崩溃,但现有的引入重要性采样机制等并不能提升训练稳定性。不同于此前采取诸如丢弃差异较大的数据之类的变通方法,这篇论文的研究人员希望通过解决路由分布也就是 R3 来根本性解决这个问题。
论文地址:https://arxiv.org/pdf/2510.11370
强化学习已成为大语言模型后期训练的基石,利用大规模强化学习,大模型更深入、更广泛推理,获得解决复杂问题所需的高级能力,但其面临的关键挑战是如何平衡效率和稳定性。
现代强化学习框架通常使用不同的引擎进行推理和训练用于部署,但这种架构上的分离可能导致 token 概率出现分歧,甚至可能导致灾难性的强化学习崩溃。然而,现有的改进方法并不能完全解决 MoE 模型上进行强化学习训练时出现的强化学习离线策略问题。
研究人员提出的 R3,其工作原理是在序列生成期间从推理引擎捕获路由分布,并将其直接重放到训练引擎中。这一过程可以缩小训练和推理之间的差距,其显著特征是不同引擎生成的逻辑向量的 KL 散度(量化两个概率分布之间的差异程度,值越小说明两个分布越接近)显著降低,两个阶段之间概率差异显著的 token 数量减少了大约一个数量级。
此外,该方法同时适用于在线策略(on-policy)和小批量(mini-batch)式离线策略强化学习(off-policy)场景。
论文提到了研究团队的三大主要贡献:
1、系统识别和分析了 MoE 模型中训练和推理之间的路由分布差异,强调了它们在训练不稳定性中的作用;
2、提出 Rollout Routing Replay,它重用训练引擎内部的推理时间路由分布,以协调训练和推理之间的路由行为;
3、将 R3 应用于多种强化学习设置进行 MoE 强化学习,并表明 R3 在稳定性和整体性能方面优于 GSPO 和 TIS。
R3 的主要思路是在训练前向传播过程中重用推理路由掩码 I,同时仍将 softmax 应用于训练逻辑以保持梯度流。
这种设计主要有两个目的:一是对齐训练和推理,确保训练重放期间使用的专家与推理期间选择的专家相匹配,从而消除专家选择中的不匹配;二是保留梯度数据流,通过仅重放掩码,梯度仍然可以流回 logits 而不会干扰计算图,这有助于有效地优化路由器。

具体来看,R3 在效率优化上,通过路由掩码缓存(Router Mask Caching)适配多轮对话场景,降低计算开销。
其论文提到,缓存的路由掩码具有相似的属性,对于相同的前缀 token,MoE 路由器应该产生相同的结果,因此来自推理引擎的路由掩码可以与前缀 KVCache 一起缓存。
对于每个层和 token 前缀,相应的路由掩码都存储在 KVCache 中。当相同的前缀出现并命中缓存时,这些掩码可以被重用,从而无需重新计算,这使得 R3 能够与前缀缓存机制无缝集成。
研究人员称,缓存路由掩码在 Agent 场景中有较大应用空间。例如软件工程和网页浏览等 Agent 任务,都涉及自回归生成和工具调用之间的多轮交互,为了提高效率,这些过程直接重用了前几轮的 KVCache,因此无需重新生成已计算的数据。路由掩码缓存使 R3 能够在强化学习代理任务中保持高效,而无需重新预填充以生成路由掩码。
为了证明 R3 在缩小训练-推理差异上的有效性,研究人员使用 Qwen3-30B-A3B 模型进行了验证,其将推理过程中获得的路由分布缓存在 SGLang 上,并在 Megatron 框架内重放它们。
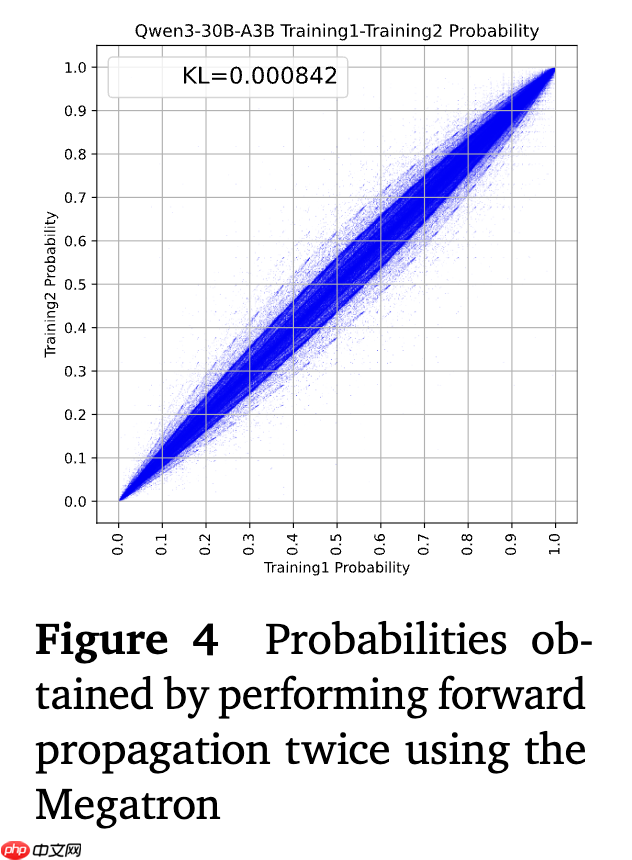
结果表明,应用 R3 后,训练和推理之间的 KL 散度从 1.5×10⁻³ 减小到 7.5×10⁻⁴,接近于稠密模型的 6.4×10⁻⁴水平,这表明其训练-推理差异减少。
研究人员还绘制了使用 R3 的训练-推理差异比率的累积分布图,对于 MoE 模型,应用 R3 可将具有较大训练推理差异的 token 的频率降低一个数量级。

为了评估 R3 对强化学习的性能改进,研究人员从 BigMath、ORZ 等开源数据集筛选约 10 万道可验证数学题,采用 AIME24、AIME25、AMC23 和 MATH500 作为基准数据集进行评估,并在单次训练过程中每 5 个全局步骤测量一次模型性能。
其选择的模型是 Qwen3-30B-A3B-Base 及其微调模型 Qwen3-30B-A3B-SFT。
评估方式是每 5 个全局步骤记录模型性能,最终报告最佳性能及对应训练步骤,若模型后期性能骤降,同时追踪训练崩盘步骤”。
实验结果表明,整体性能上,R3 在多步更新场景,GRPO+R3 平均得分 68.05 分,比 GSPO 高出 1.29 分;GSPO+R3 进一步提升至 69.00,比单独 GSPO 高 2.24 分。
单步更新场景,SFT 模型上,GRPO+R3 平均得分 71.83 分,比 GRPO(62.23)高 9.6 分,比 GRPO+TIS(66.24)高 5.59 分;Base 模型上,GRPO+R3 平均得分 70.73,比 GRPO(61.69)高 9.04 分。
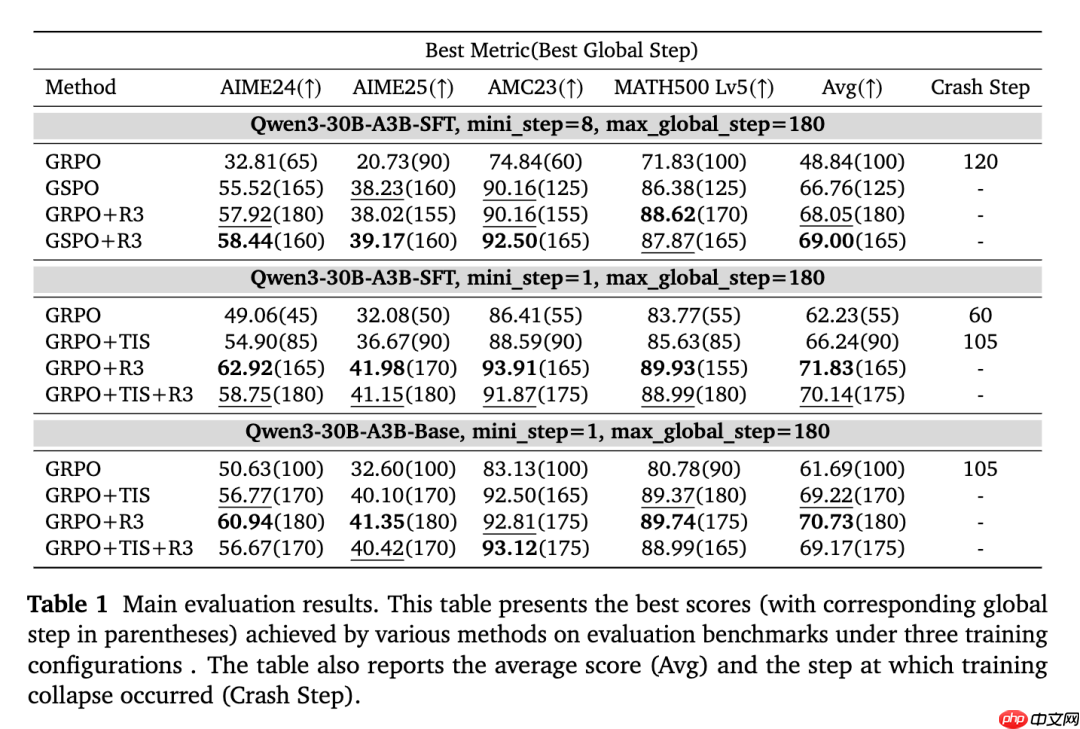
研究人员还发现,将 R3 与 TIS 结合使用并不能带来明显的性能提升,甚至可能降低性能,例如在 SFT 模型的单小步设置下,TIS+R3 的得分比单独使用 R3 低 1.69 分。由于 R3 已经显著降低了训练和推理之间的策略差异,因此 TIS 的额外校正效果微乎其微。
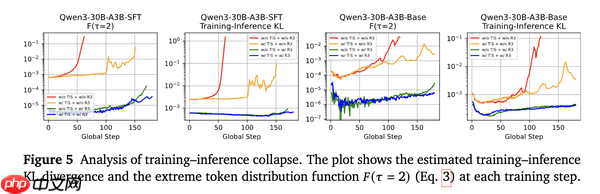
训练稳定性方面:如 GRPO、GRPO+TIS 等无 R3 的方法在单步更新场景中均出现崩盘,GRPO 在 60 步崩盘、GRPO+TIS 在 105 步崩盘。
引入 R3 后,所有组合方法均无崩盘,且训练过程中训练-推理 KL 散度等始终较低。
优化与生成行为方面,在训练过程中,R3 还能增强优化稳定性、探索行为和生成动态。下图是研究人员绘制的单步 + 基础模型组训练过程中的序列长度、梯度范数、生成熵和评估分数。
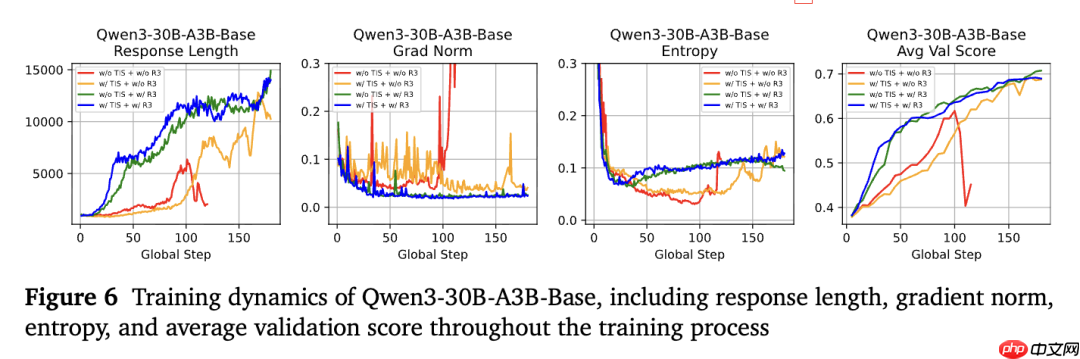
结果显示,R3 具有更小的梯度范数、更平滑的序列增长模式和更稳定的熵。实验中使用 R3 时,生成的序列长度在训练开始时迅速上升,表明 R3 能够快速捕捉到正确的优化方向,相比之下其他两个训练过程在第 80 步之后才缓慢上升,并且波动更为明显;R3 始终保持较低的梯度范数,表明优化过程更加稳定;实验使用 R3 时,熵在大约第 25 步后开始稳步上升,表明模型更早地开始探索更优策略,不使用 R3 时,熵上升得更晚,并且波动较大。
MoE 架构如今已成为扩展现代语言模型的基石,其采用门控网络,对每个 token 稀疏地仅激活一部分专家参数,从而将模型的总参数数量与其推理成本分离开来,从而大幅提升了模型容量。然而,由于门控网络的敏感性,MoE 模型容易受到训练不稳定性的影响,这使得路由稳健性成为有效模型收敛的核心挑战。
在这篇论文中,研究人员在训练过程中重用推理时的路由分布,以在保留梯度流的同时对齐专家选择。这种思路或为行业提供了新的研究思路。
本文来自微信公众号:智东西(ID:zhidxcom),作者:程茜,原标题《小米 AI 新论文!雷军千万年薪要挖的 DeepSeek 天才少女署名》
以上就是小米 AI 新论文,雷军千万年薪要挖的 DeepSeek 罗福莉署名的详细内容,更多请关注php中文网其它相关文章!

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 979
979



















