
2025 年 8 月,scale[1] 评测基准在纳入 gpt-5 家族后,迅速新增了深度求索[2] 公司于 8 月 21 日推出的最新模型 —— deepseek-v3.1。
 https://www.php.cn/link/6095b12ecdfcd301bf571ff6ca7a9edb
https://www.php.cn/link/6095b12ecdfcd301bf571ff6ca7a9edb
评测数据显示,DeepSeek-V3.1 在“理解、优化、转换”三大维度展现出较为均衡的综合能力。其中,其在 SQL 优化 方面表现尤为亮眼,得分为 67.3 分,为涉及代码深度分析和系统维护的应用场景提供了有力支撑。
为了确保评测结果具备纵向可比性与稳定性,本月仍沿用三大核心维度:SQL 理解、SQL 优化、SQL 方言转换,对所有参评模型进行公平且深入的能力评估。
以下是针对 DeepSeek-V3.1 的首次全面评测解析。
 https://www.php.cn/link/be5b7dd09833f473d70afbf4c2f8642b
https://www.php.cn/link/be5b7dd09833f473d70afbf4c2f8642b
 SQL 理解能力SQL 理解能力
SQL 理解能力SQL 理解能力
| 细分指标 | 分数 |
|---|---|
| 语法错误检测 | 81.4 |
| 执行准确性 | 70 |
| 执行计划检测 | 57.1 |
优势:在“语法错误检测”方面表现稳健,得分最高,显示出其具备较强的代码审查基础能力。
不足:在“执行计划检测”上得分最低,反映出其对 SQL 执行逻辑与性能机制的深层理解仍有欠缺。
DeepSeek-V3.1 在该维度排名 第 12 位,与领先梯队存在一定差距。
以榜首 Gemini 2.5 Flash 为例,其总分为 82.3,高出 12.1 分。差距主要来源于“执行准确性”这一关键指标。该指标反映的是模型对复杂语义结构的理解落地能力,而 DeepSeek-V3.1 此项仅获 70 分,显著低于 Gemini 2.5 Flash 的 90 分,说明其在处理复杂查询逻辑时仍有较大提升空间。
 SQL 优化能力SQL 优化能力
SQL 优化能力SQL 优化能力
| 细分指标 | 分数 |
|---|---|
| 语法错误检测 | 94.7 |
| 逻辑等价 | 78.9 |
| 优化深度 | 57.8 |
优势:整体可靠性高。模型在语法合规性(94.7分)和优化前后逻辑一致性(78.9分)方面表现良好,保障了输出方案的安全性和可用性。
不足:优化策略缺乏创新与深度。“优化深度”得分仅为 57.8 分,是其明显短板,表明模型更倾向于保守改写,难以生成高级或复杂的优化建议。
DeepSeek-V3.1 以 67.3 分位列第 9 名,落后于专业工具 SQLFlash[3](88.5分)及同系列模型 DeepSeek-R1(71.6分)等头部产品。
差距主要体现在优化策略的复杂度与创造性上。其“优化深度”得分不仅自身偏低,也远逊于领先模型,暴露出其在深层次结构分析和智能重构方面的局限。同时,“逻辑等价”得分虽属中上水平,但相较顶尖模型仍显不足,提示其在逻辑校验机制上尚需加强。
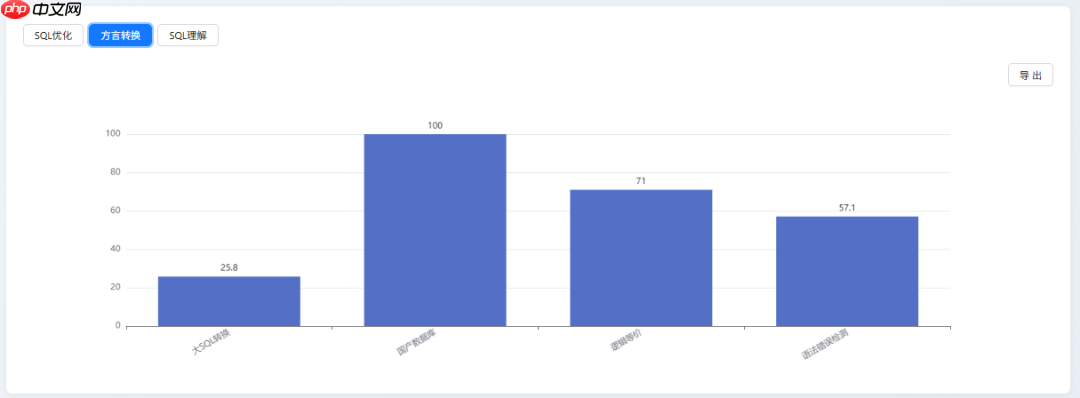 SQL 方言转换能力SQL 方言转换能力
SQL 方言转换能力SQL 方言转换能力
| 细分指标 | 分数 |
|---|---|
| 国产数据库转换 | 100 |
| 逻辑等价 | 71 |
| 语法错误检测 | 57.1 |
| 大SQL转换 | 25.8 |
优势:在特定领域任务中表现出色。DeepSeek-V3.1 在“国产数据库转换”项目中取得满分,充分展现了其强大的垂直知识储备与场景适配能力。面对规则明确、边界清晰的专业任务,模型能够精准执行转换逻辑,体现极高的专业化水准。
不足:长文本与复杂结构处理能力薄弱。其在“大 SQL 转换”中得分极低(25.8分),暴露了在处理超长语句、多层嵌套及复杂依赖关系时的核心缺陷,存在信息丢失或逻辑断裂的风险,成为制约其通用性的关键瓶颈。
在该维度中,DeepSeek-V3.1 以 63.2 分排在第 13 位,明显落后于 GPT-5 mini(79.6 分)、o4-mini(77.4 分)等领先模型。
根本原因在于能力分布不均:尽管在“国产数据库转换”这类专项任务中表现完美(100 分),但在考验通用能力的关键环节却表现不佳。例如,“大 SQL 转换”得分(25.8 分)远低于 GPT-5 mini 的 58.1 分,凸显其上下文建模能力不足;“语法错误检测”得分(57.1 分)亦大幅落后于头部模型(如 92.9 分),反映出语法敏感度和纠错精度有待提升。这种基础能力的缺失,直接影响了其整体排名。
DeepSeek-V3.1 的加入为当前 LLM 的 SQL 能力图谱增添了新的观察视角。本次评测清晰揭示:当前主流大模型在 SQL 相关任务中呈现出“专精有余、通备不足”的特点。例如,DeepSeek-V3.1 在特定国产数据库迁移场景中表现卓越,但在长 SQL 处理与深度优化方面仍有明显短板。
这也再次强调我们的观点:脱离实际应用场景谈模型排名,并不能真实反映其价值。
我们将持续追踪并引入业界前沿的大模型。备受期待的专业级 SQL 应用 SQLShift[4] 的详细评测报告即将上线,敬请关注。
我们致力于通过公开、透明的方式构建行业认可的 LLM 在 SQL 领域能力评估体系,并诚邀社区成员提供宝贵意见与反馈。
参考资料
[1]
SCALE: https://www.php.cn/link/5aad38004a6546b2382974698dbcb264
[2]
深度求索: https://www.php.cn/link/6226c5b0f6a9b68f3dee542ab5c34545
[3]
SQLFlash: https://www.php.cn/link/2bf720f77d3874e07949cfcd1f75e91e
[4]
SQLShift: https://www.php.cn/link/358793cf5d9f8a4842a137486ef6bf29
✨ Github:https://www.php.cn/link/5aad38004a6546b2382974698dbcb264
? 官网:https://www.php.cn/link/fb4f401f943fac2830a81ac63178e9a4
以上就是2025 年 8 月《DeepSeek-V3.1 SQL 能力评测报告》发布的详细内容,更多请关注php中文网其它相关文章!

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 193
193






















