
微软亚洲研究院联合北京大学、西安交通大学等高校,最近提出了一种名为“从错误中学习(LeMA)”的人工智能训练方法。该方法声称能够通过模仿人类学习的过程,来提升人工智能的推理能力
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
当下 OpenAI GPT-4 和谷歌 aLM-2 等大语言模型在自然语言处理(NLP)任务,及思维链(chain-of-thought,CoT)推理的数学难题任务中都有不错的表现。
但例如 LLaMA-2 及 Baichuan-2 等开源大模型,在处理相关问题时则有待加强。为了提升开源这些大语言模型的思维链推理能力,研究团队提出了 LeMA 方法。这种方法主要是模仿人类的学习过程,通过“从错误中学习”,以改进模型的推理能力。
▲ 图源 相关论文
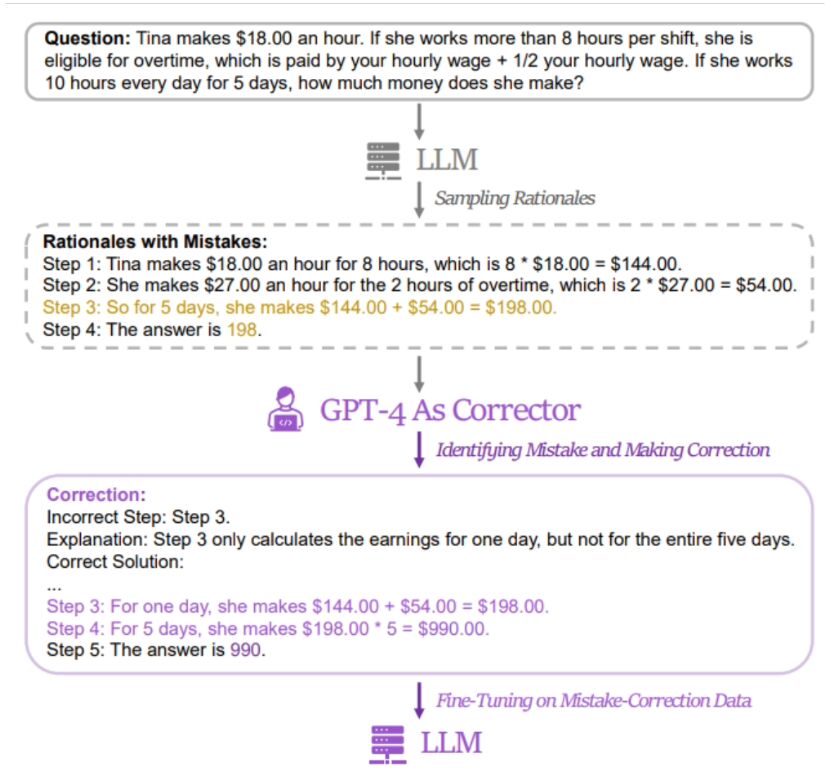
本站发现,研究人员的方法是使用一对包含“错误解答”与“修正后正确答案”的数据来微调相关模型。为取得相关数据,研究人员收集了 5 个不同大语言模型(包括 LLaMA 及 GPT 系列)的错误答案和推理过程,再以 GPT-4 作为“订正者”,提供修正后的正确答案。
据悉,修正后的正确答案中包含三类信息,分别是原推理过程中错误片段、原推理过程出错的原因、以及如何修正原方法以获得正确答案。
研究人员使用GSM8K和MATH测试了LeMa训练法对5个开源大模型的效果。结果显示,在改进后的LLaMA-2-70B模型中,GSM8K的准确率分别为83.5%和81.4%,而MATH的准确率分别为25.0%和23.6%
目前研究人员已将 LeMA 的相关资料公开在 GitHub 上,感兴趣的小伙伴们可以点此跳转。
以上就是微软推出 “从错误中学习” 模型训练法,号称可“模仿人类学习过程,改善 AI 推理能力”的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 649
649























