
近日,arxiv 上发布了一篇论文,对 Transformer 的数学原理进行全新解读,内容很长,知识很多,十二分建议阅读原文。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

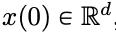 在时间间隔 (0,T) 上会按照给定的时变速度场
在时间间隔 (0,T) 上会按照给定的时变速度场 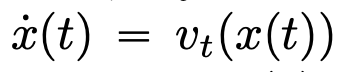 进行演化。因此,DNN 可以看作是从一个
进行演化。因此,DNN 可以看作是从一个 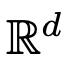 到另一个
到另一个 的流映射(Flow Map)
的流映射(Flow Map)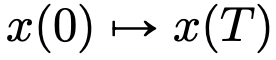 。即使在经典 DNN 架构限制下的速度场
。即使在经典 DNN 架构限制下的速度场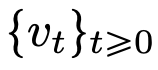 中,流映射之间也具有很强的相似性。
中,流映射之间也具有很强的相似性。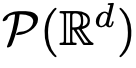 上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。
上的流映射,即 d 维概率测度空间(the space of probability measures)间的映射。为了实现这种在度量空间间进行转换的流映射,Transformers 需要建立了一个平均场相互作用的粒子系统(mean-field interacting particle system.)。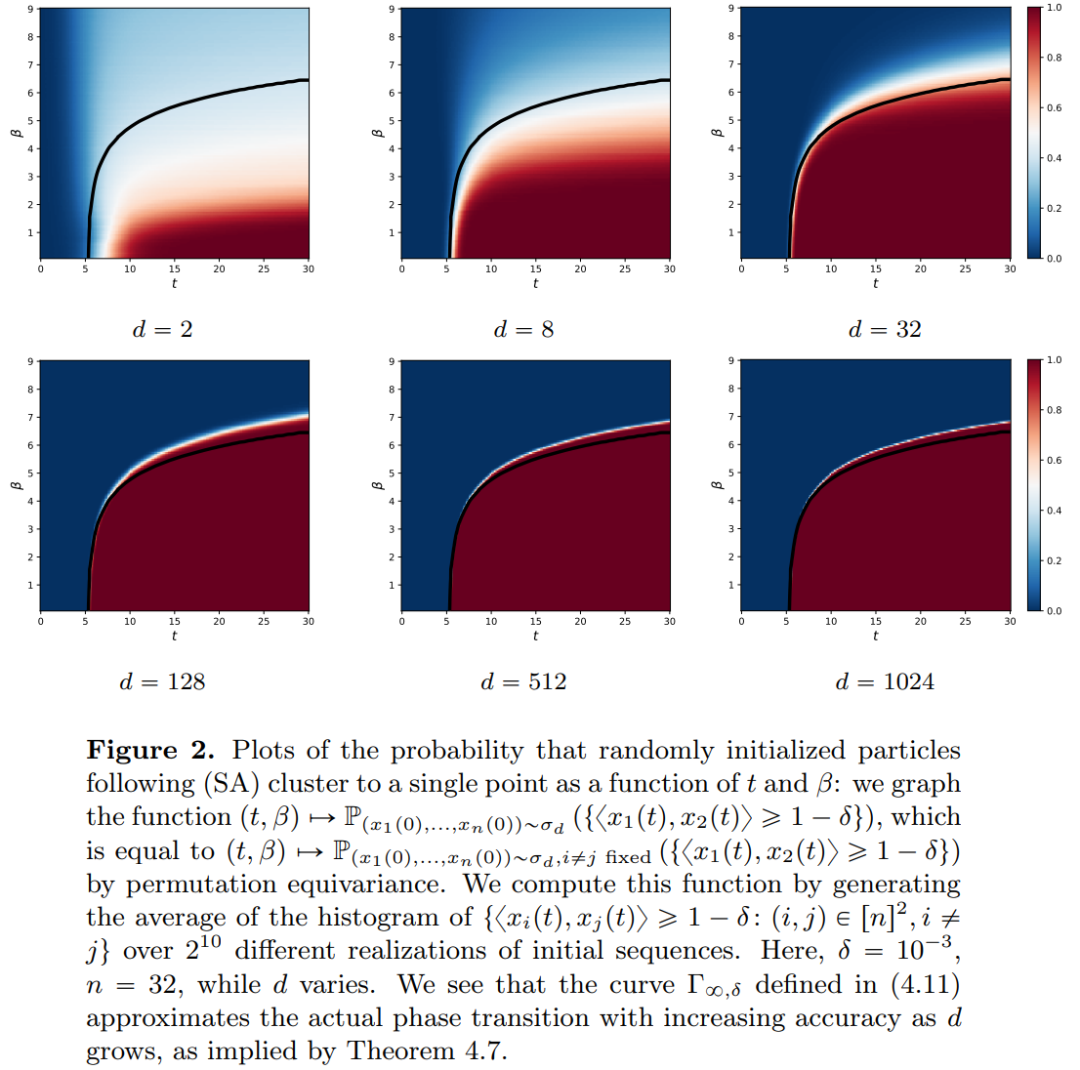

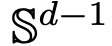 的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。
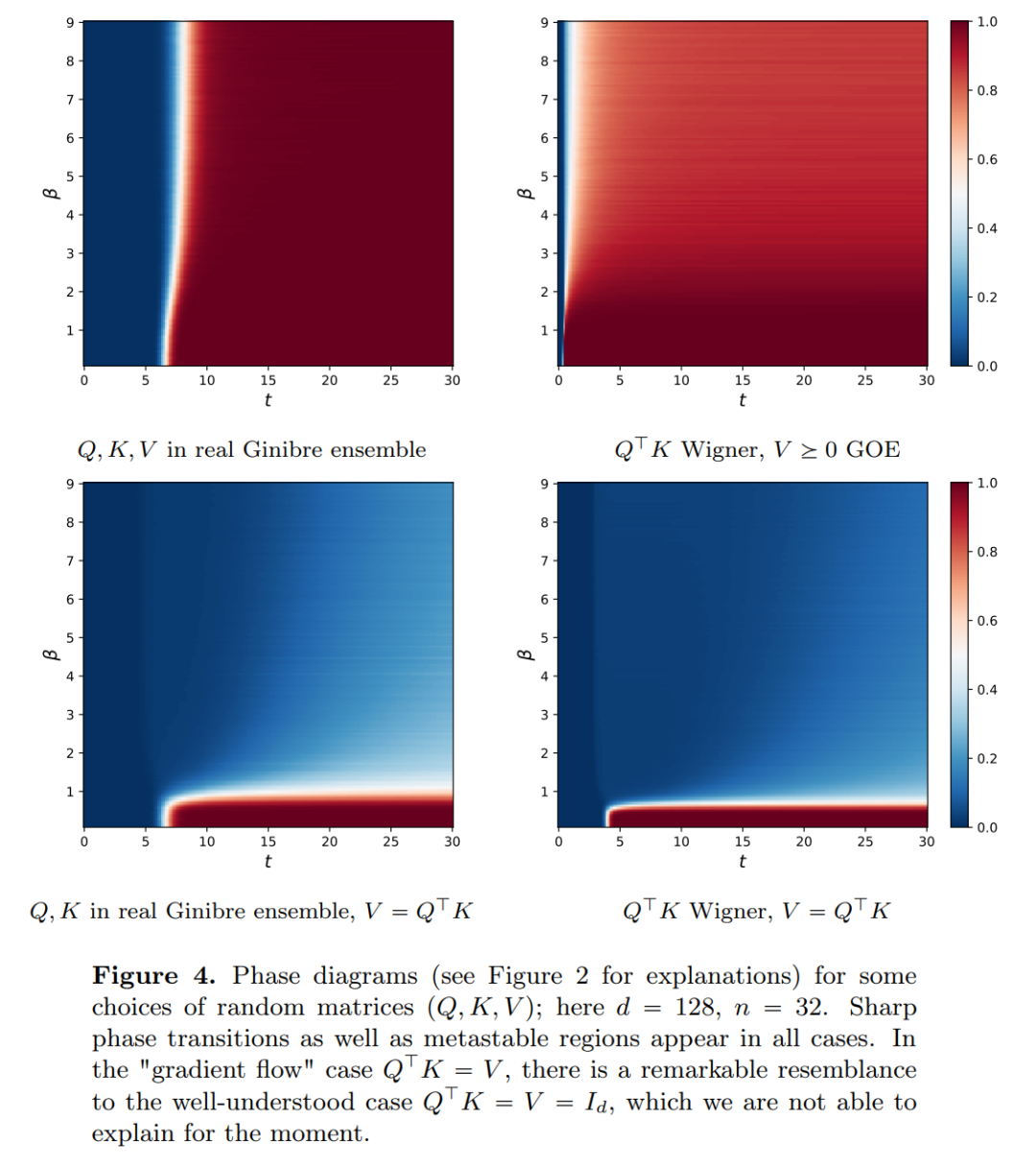
的空间内部,而自注意力机制则是通过经验度量实现粒子之间的非线性耦合。反过来,经验度量根据连续性偏微分方程进行演化。本文还为自注意引入了一个更简单好用的替代模型,一个能量函数的 Wasserstein 梯度流,而能量函数在球面上点的最优配置已经有成熟的研究方法。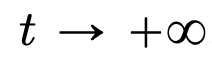 时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。
时聚成一个点。研究者对粒子集群收缩率的精确描述对这一结果进行了补充说明。具体来说,研究者绘制了所有粒子间距离的直方图,以及所有粒子快要完成聚类的时间点(见原文第 4 节)。研究者还在不假设维数 d 较大的情况下就得到了聚类结果(见原文第 5 节)。以上就是揭秘的全新版本:你从未见过的Transformer数学原理的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 149
149






















