
我想提取网页:http://www.igxe.cn/h1z1/43385... 上该物品的当前售价和对应商品的ITEM_ID
我使用的是PYTHON2.7配合requests进行操作的,代码如下:
import requests
import sys
headers = {'User-Agent': 'Mozilla/5.0 (Linux; U; Android 4.0.3; zh-cn; M032 Build/IML74K) AppleWebKit/533.1 (KHTML, like Gecko)Version/4.0 MQQBrowser/4.1 Mobile Safari/533.1'}
r = requests.get('http://www.igxe.cn/h1z1/433850/product-567592', headers = headers,stream=True)
print r.request.headers['User-Agent']
print r.text
reload(sys)
sys.setdefaultencoding('utf-8')
f = open('/workspace/test.txt', 'w')
f.write (r.text)
f.close
得到的该代码文件包含了网页上绝大部分信息,唯独就是没有我需要的售价信息以及物品ID,但是该段信息却可以通过浏览器的审查元素获得,代码片段如下: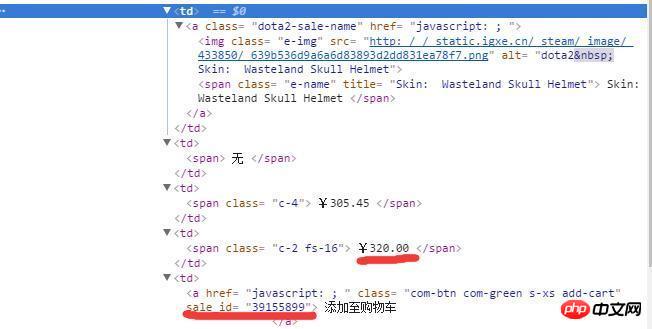
这段代码片段通过审查元素可以轻松获得,但是源代码上却没有,所以十分困惑该如何获取。
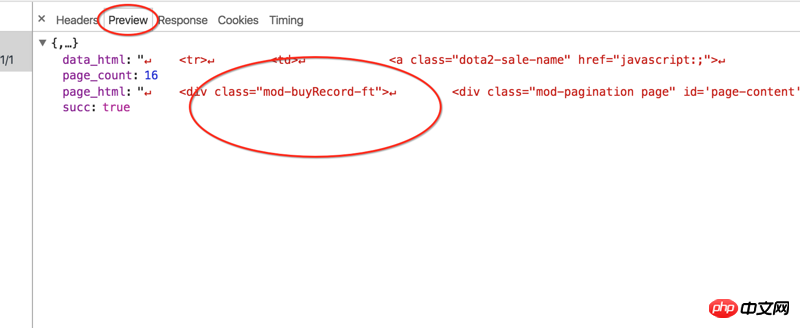
在源代码中找到了如下片段,不知道是不是AJAX有关的信息获取的方式:
Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号


 0
0  1
1 2182
2182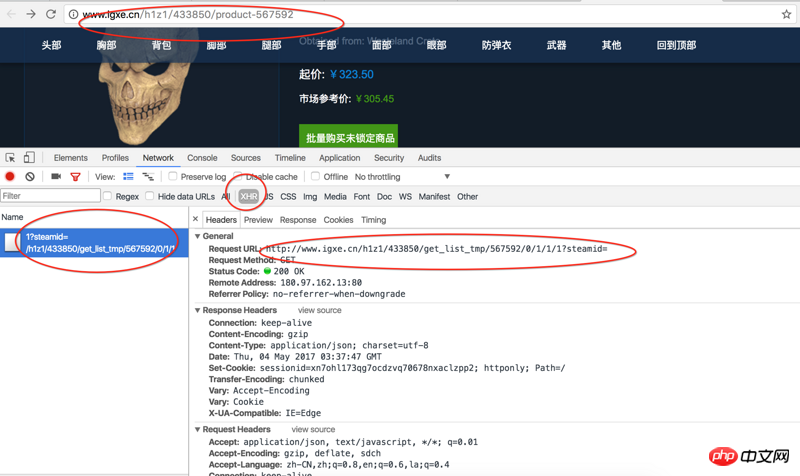
 赞 +0
赞 +0


















学习是最好的投资!