
斯坦福大学研究团队提出全新多模态语言模型,实现逼真3d人体动作生成与理解。该模型突破性地整合了语音、文本和动作三种模态,能够根据语音和文本指令生成自然流畅的动作,并支持动作编辑。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
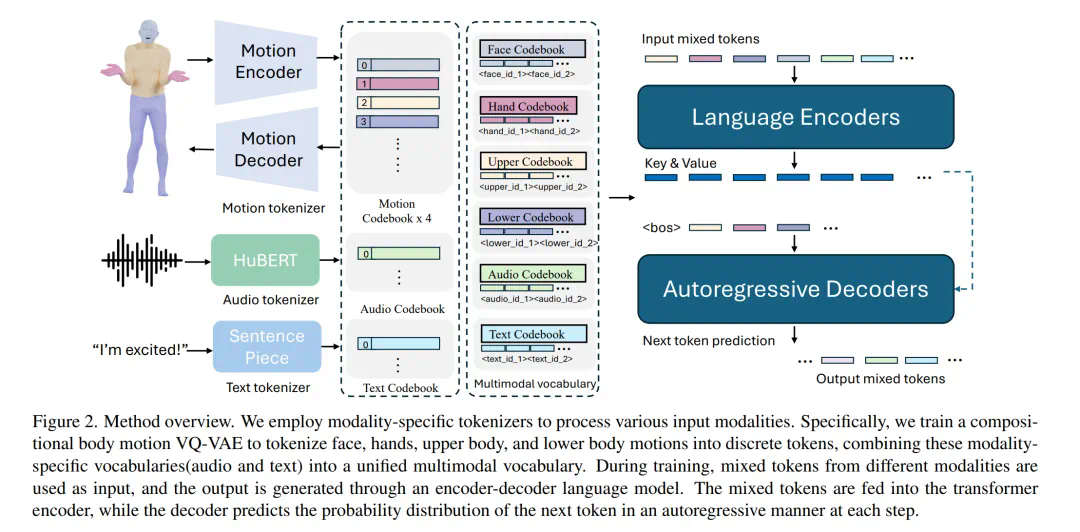
研究人员指出,利用语言模型统一人类动作的言语和非言语表达至关重要,因为它能自然地与其他模态连接,并具备强大的语义推理和理解能力。 该模型采用两阶段训练:首先进行预训练,对齐不同模态,然后进行下游任务训练,使其遵循各种指令。

该模型将动作分解为面部、手部、上半身和下半身等不同部位进行token化,再结合文本和语音token化策略,实现多模态输入的统一表示。预训练阶段包含组合动作对齐(空间和时间)和音频-文本对齐两种任务,以学习动作的时空先验和模态间关联。


实验结果表明,该模型在伴语手势生成等任务上超越现有SOTA模型,尤其在数据稀缺的情况下优势显著。 它能够根据语音和文本指令生成协调一致的动作,并支持将“绕圈走”等动作替换为其他动作序列,保持动作的自然流畅。

此外,该模型还展现了出色的泛化能力和在动作情绪预测任务中的潜力。这项研究为李飞飞教授的“空间智能”研究目标做出了重要贡献。
以上就是李飞飞团队统一动作与语言,新的多模态模型不仅超懂指令,还能读懂隐含情绪的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 518
518


















