本文介绍了使用PaddleClas进行图像分类的流程。先查看飞桨版本,安装PaddleClas环境,了解其功能与全局配置。接着以flowers102数据集为例,演示下载、配置文件修改、训练及预测过程。还讲解了自定义蝴蝶数据集的处理、训练、中断续训、预测、评估和批处理预测等操作。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

import paddleprint(paddle.__version__)
2.1.2
参考文档:https://github.com/PaddlePaddle/PaddleClas/blob/release/2.2/docs/en/tutorials/install_en.md
# !git clone https://github.com/PaddlePaddle/PaddleClas.git# !git clone https://gitee.com/PaddlePaddle/PaddleClas.git# %cd ./PaddleClas/# !pip install --upgrade pip# !pip3 install --upgrade -r requirements.txt -i https://mirror.baidu.com/pypi/simple
官方文档:https://github.com/PaddlePaddle/PaddleClas
拥有
图像识别
图像分类
特征学习
等内容
| 参数名称 | 具体含义 | 默认值 |
|---|---|---|
| checkpoints | 断点模型路径,用于恢复训练 | null |
| pretrained_model | 预训练模型路径 | null |
| output_dir | 保存模型路径 | "./output/" |
| save_interval | 每隔多少个epoch保存模型 | 1 |
| eval_during_train | 是否在训练时进行评估 | True |
| eval_interval | 每隔多少个epoch进行模型评估 | 1 |
| epochs | 训练总epoch数 | 无 |
| print_batch_step | 每隔多少个mini-batch打印输出 | 10 |
| use_visualdl | 是否是用visualdl可视化训练过程 | False |
| image_shape | 图片大小 | [3,224,224] |
| save_inference_dir | inference模型的保存路径 | "./inference" |
| eval_mode | eval的模式 | "classification" |
注:image_shape值除了默认还可以选择list, shape: (3,)
eval_mode除了默认值还可以选择"retrieval"
参考文档:https://github.com/PaddlePaddle/PaddleClas/blob/release/2.2/docs/en/tutorials/config_description_en.md
配置文件具体说明:
# global configs 全局配置Global:checkpoints: null # 断点模型路径,用于恢复训练pretrained_model: null # 预训练模型路径output_dir: ./output/ # 保存模型路径device: gpu # 每隔多少个epoch保存模型class_num: 102 # 分类数量save_interval: 1 # 每隔多少个epoch保存模型eval_during_train: True # 是否在训练时进行评估eval_interval: 1 # 每隔多少个epoch进行模型评估epochs: 20 # 训练总epoch数print_batch_step: 10 # 每隔多少个mini-batch打印输出use_visualdl: False # 是否是用visualdl可视化训练过程# 同于静态图导出image_shape: [3, 224, 224] # 图片大小save_inference_dir: ./inference # inference模型的保存路径# model architecture 模型架构Arch:name: ResNet50_vd # 模型名称# loss function config for traing/eval process 培训/评估过程的损失功能配置Loss:Train: # 训练集
- CELoss:
weight: 1.0 # 交叉熵损失函数在整个Loss中的权重Eval: # 测试集
- CELoss:
weight: 1.0Optimizer: # 优化器name: Momentummomentum: 0.9lr:
name: Cosine # 学习率下降方式
learning_rate: 0.0125 # 学习率初始值
warmup_epoch: 5 # warmup轮数regularizer:
name: 'L2' # 正则化方法名
coeff: 0.00001 # 正则化系数# data loader for train and eval 数据读取DataLoader:Train:
dataset:
name: ImageNetDataset # 名称
image_root: ./dataset/flowers102/ # 数据存放路径
cls_label_path: ./dataset/flowers102/train_list.txt # 数据集标签
transform_ops: # 数据预处理
- DecodeImage:
to_rgb: True # 转换成RGB
channel_first: False # 安装CHW排列
- RandCropImage:
size: 224 # 随机裁剪
- RandFlipImage:
flip_code: 1 # 随机翻转
- NormalizeImage:
scale: 1.0/255.0 # RGB值归一化
mean: [0.485, 0.456, 0.406] # 归一化均值
std: [0.229, 0.224, 0.225] # 归一化方差
order: ''
sampler: # 采样器
name: DistributedBatchSampler # 采样器类型
batch_size: 32 # 批处理大小
drop_last: False # 舍弃不足的数据
shuffle: True # 是否乱序
loader:
num_workers: 0 # 数据读取线程
use_shared_memory: True # 是否用共享内存Eval: # 测试集的数据
dataset:
name: ImageNetDataset # 类名
image_root: ./dataset/flowers102/ # 数据集存放路径
cls_label_path: ./dataset/flowers102/val_list.txt # 数据标签存放位置
transform_ops:
- DecodeImage:
to_rgb: True # 转换RGB
channel_first: False # 按照CHW排序
- ResizeImage:
resize_short: 256 # 按照短边调整大小
- CropImage:
size: 224 # 随机裁剪大小
- NormalizeImage:
scale: 1.0/255.0 # RGB值归一化
mean: [0.485, 0.456, 0.406] # 归一化均值
std: [0.229, 0.224, 0.225] # 归一化均值
order: ''
sampler:
name: DistributedBatchSampler # 采样器名称
batch_size: 64 # 批处理大小
drop_last: False # 放弃最后的多余数据
shuffle: False # 乱序
loader:
num_workers: 0 # 读取线程
use_shared_memory: True # 内存共享Infer:infer_imgs: docs/images/whl/demo.jpg # 预测的图像地址batch_size: 10 # 批处理大小transforms:
- DecodeImage:
to_rgb: True # 转RGB
channel_first: False # 按CHW排序
- ResizeImage:
resize_short: 256 # 按短边调整大小
- CropImage:
size: 224 # 随机裁剪
- NormalizeImage:
scale: 1.0/255.0 # RGB值归一化
mean: [0.485, 0.456, 0.406] # 归一化均值
std: [0.229, 0.224, 0.225] # 归一化方差
order: ''
- ToCHWImage:PostProcess:
name: Topk # 后处理名字
topk: 5
class_id_map_file: ppcls/utils/imagenet1k_label_list.txt # 标签和值的映射文件Metric: # 评估Train:
- TopkAcc:
topk: [1, 5]Eval:
- TopkAcc:
topk: [1, 5]训练集中有:
train_list.txt:训练集,1020张图
val_list.txt: 验证集,1020张图
train_extra_list.txt:大的训练集,7169张图
图片展示:

数据写入情况:
相对路径 标签
# 修改当前路径# %cd ./PaddleClas/dataset/flowers102# 下载数据集# !wget https://paddle-imagenet-models-name.bj.bcebos.com/data/flowers102.zip# 解压数据# !unzip flowers102.zip
我们要首先对配置文件进行修改。 AI Studio由于没有共享内存,所以需要修改num_workers: 0,其他的可以不修改。
查看自己的环境是否为CPU或者是GPU然后对device:进行修改
# 切换目录到PaddleClas下%cd /home/aistudio/PaddleClas# 开始训练!python tools/train.py -c ./ppcls/configs/quick_start/ResNet50_vd.yaml -o Arch.pretrained=True
-c为训练配置文件
-o Infer.infer_imgs=为预测的图片
-o Global.pretrained_model=为用于预测的模型
!python tools/infer.py -c ./ppcls/configs/quick_start/new_user/ShuffleNetV2_x0_25.yaml\
-o Infer.infer_imgs=dataset/flowers102/jpg/image_00001.jpg \
-o Global.pretrained_model=output/ResNet50_vd/latest[{'class_ids': [75, 45, 43, 18, 58], 'scores': [1.0, 0.0, 0.0, 0.0, 0.0], 'file_name': 'dataset/flowers102/jpg/image_00001.jpg', 'label_names': []}]
这里对75,45,43,18,58的比例进行了分析,最后以75为最后结果。
这里使用的是蝴蝶分类数据目录位置:data/data63004
# 把数据解压到/home/aistudio/# !unzip -d /home/aistudio/ /home/aistudio/data/data63004/Butterfly20.zip
要准备训练集和验证集还有标签映射表
相对路径/绝对路径 (空格) 标签
标签映射表内容:
标签 空格 对应值
这里在/home/aistudio/species.txt 中已经处在
%cd /home/aistudio/import osimport random
/home/aistudio
data_path = '/home/aistudio/Butterfly20' # 设置初始文件地址character_folders = os.listdir(data_path) # 查看地址下文件夹character_folders
['004.Byasa_dasarada', '010.Lamproptera_curius', '001.Atrophaneura_horishanus', '020.Papilio_hermosanus', '012.Losaria_coon', '016.Papilio_alcmenor', '002.Atrophaneura_varuna', '013.Meandrusa_payeni', '011.Lamproptera_meges', '005.Byasa_polyeuctes', '017.Papilio_arcturus', '003.Byasa_alcinous', '019.Papilio_dialis', '014.Meandrusa_sciron', '008.Graphium_sarpedon', '009.Iphiclides_podalirius', '018.Papilio_bianor', '006.Graphium_agamemnon', '.DS_Store', '007.Graphium_cloanthus', '015.Pachliopta_aristolochiae']
namelist = '/home/aistudio/species.txt' # 文件地址labledcoun = {}with open(namelist)as f: '''
读取文件后处理成字典
'''
while True:
line = f.readline().strip().split(' ') if line[0] == '': break
if line[1] == '\ufeff0':
labledcoun[1] = line[0] else:
labledcoun[line[1]] = line[0] print(labledcoun){'001.Atrophaneura_horishanus': '1', '002.Atrophaneura_varuna': '2', '003.Byasa_alcinous': '3', '004.Byasa_dasarada': '4', '005.Byasa_polyeuctes': '5', '006.Graphium_agamemnon': '6', '007.Graphium_cloanthus': '7', '008.Graphium_sarpedon': '8', '009.Iphiclides_podalirius': '9', '010.Lamproptera_curius': '10', '011.Lamproptera_meges': '11', '012.Losaria_coon': '12', '013.Meandrusa_payeni': '13', '014.Meandrusa_sciron': '14', '015.Pachliopta_aristolochiae': '15', '016.Papilio_alcmenor': '16', '017.Papilio_arcturus': '17', '018.Papilio_bianor': '18', '019.Papilio_dialis': '19', '020.Papilio_hermosanus': '20'}# 新建标签列表if(os.path.exists('./train.txt')): # 判断有误文件
os.remove('./train.txt') # 删除文件if(os.path.exists('./val.txt')):
os.remove('./val.txt')
data_list = []for character_folder in character_folders: # 循环文件夹列表
# print(character_folder)
if character_folder not in '.DS_Store':
character_imgs = os.listdir(os.path.join(data_path,character_folder)) # 读取文件夹下面的内容
for character_img in character_imgs:
data = os.path.join(data_path, character_folder, character_img) + ' ' + labledcoun[character_folder] + '\n'
data_list.append(data)
random.shuffle(data_list)print(data_list[0])
count = len(data_list)print(count)for data in data_list: if count >= (len(data_list) * 0.2): # 20%数据写入验证集
with open('./train.txt', 'a')as f:
f.write(data) else: with open('./val.txt', 'a')as tf: # 80%写入训练集
tf.write(data)
count -= 1print("数据写入完毕!")/home/aistudio/Butterfly20/009.Iphiclides_podalirius/170.jpg 9 1866 数据写入完毕!
修改output_dir: ./output1/这里可以不修改(这里是为了与上面的内容进行区分)
修改image_root: ../ 和 cls_label_path: ../train.txt 问实际地址(这里使用了相对路径,也可以使用绝对路径。val的也一样修改)
修改class_id_map_file: ../species.txt 修改标签映射文件
# 切换目录到PaddleClas下%cd /home/aistudio/PaddleClas# 开始训练!python tools/train.py -c ./ppcls/configs/quick_start/ResNet50_vd.yaml -o Arch.pretrained=True
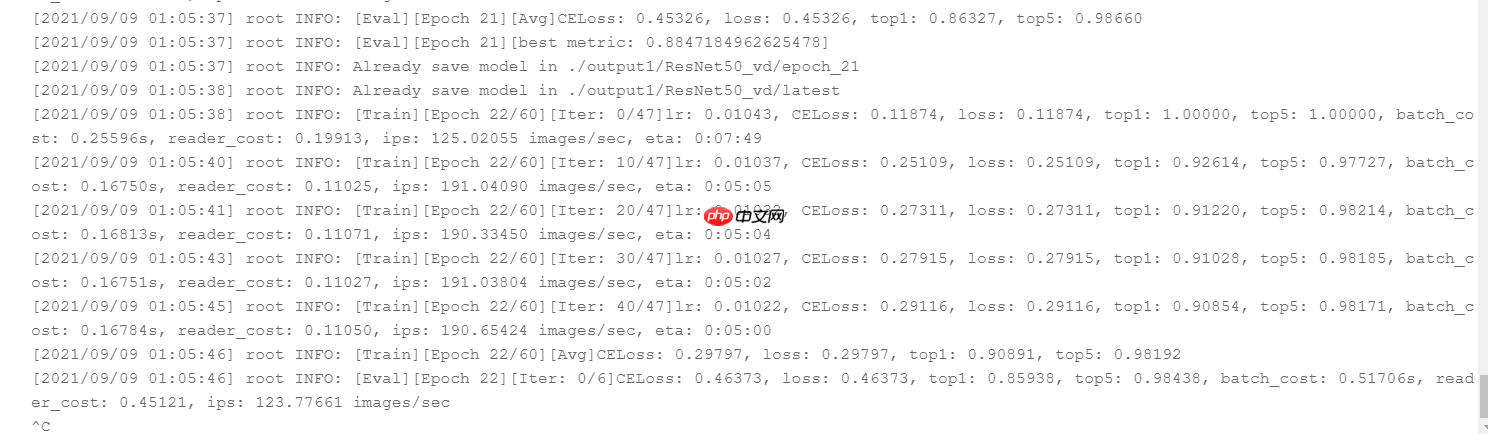
添加-o Global.checkpoints参数,后面跟上继续的模型地址(不添加后缀名)
既可以实现继续训练
!python tools/train.py \
-c ./ppcls/configs/quick_start/ResNet50_vd.yaml \
-o Global.checkpoints='./output1/ResNet50_vd/epoch_21' \
-o Arch.pretrained=True
!python tools/infer.py \
-c ./ppcls/configs/quick_start/ResNet50_vd.yaml\
-o Infer.infer_imgs=../Butterfly20/001.Atrophaneura_horishanus/084.jpg \
-o Global.pretrained_model=./output1/ResNet50_vd/latest[{'class_ids': [1, 5, 20, 3, 16], 'scores': [1.0, 0.0, 0.0, 0.0, 0.0], 'file_name': '../Butterfly20/001.Atrophaneura_horishanus/084.jpg', 'label_names': ['001.Atrophaneura_horishanus', '005.Byasa_polyeuctes', '020.Papilio_hermosanus', '003.Byasa_alcinous', '016.Papilio_alcmenor']}]
会后的结果是1,验证无误。
import paddle
!python -m paddle.distributed.launch \
tools/eval.py \
-c ./ppcls/configs/quick_start/ResNet50_vd.yaml \
-o Global.pretrained_model=./output1/ResNet50_vd/latest[Eval][Epoch 0][Avg]CELoss: 0.34251, loss: 0.34251, top1: 0.90885, top5: 0.99464
# 把数据解压到/home/aistudio/!unzip -d /home/aistudio/ /home/aistudio/data/data63004/Butterfly20_test.zip
设置PaddleClas/ppcls/engine/trainer.py文件
在infer函数中添加logger.info(result)添加输出日志地址在设置输出的模型文件中
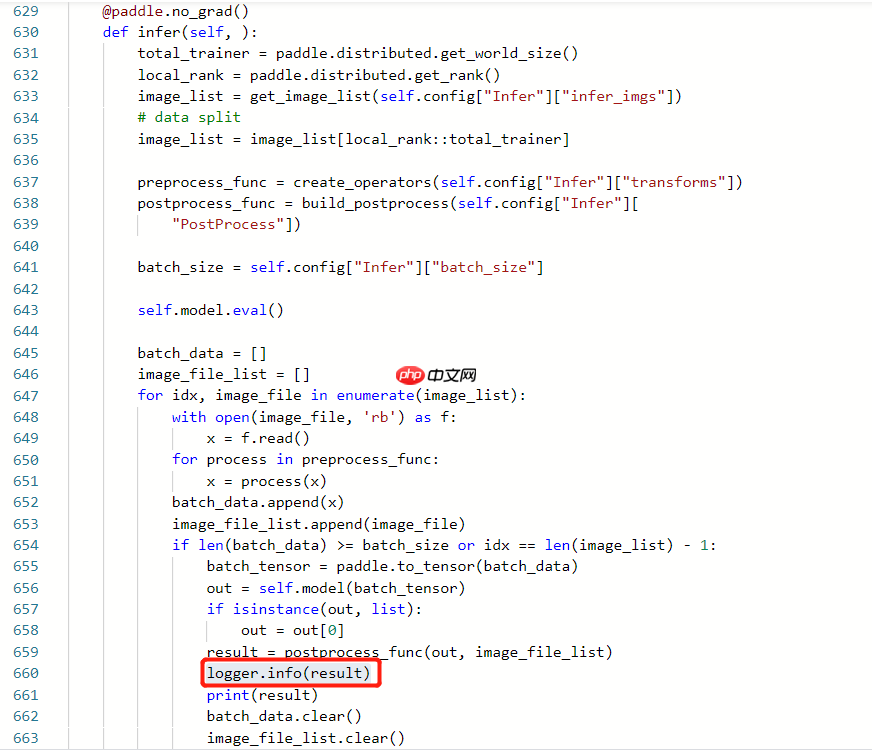
在yaml文件中修改参数topk: 1
-o Infer.infer_imgs为需要预测的图片所在的文件夹
!python3 tools/infer.py \
-c ./ppcls/configs/quick_start/ResNet50_vd.yaml \
-o Global.pretrained_model=./output1/ResNet50_vd/latest \
-o Infer.infer_imgs=../Butterfly20_test/copy以后手动删除无效日志(训练内容)
!cp output1/ResNet50_vd/infer.log ../infer.txt
%cd /home/aistudio/import jsonimport osif(os.path.exists('result.txt')): # 判断有误文件
os.remove('result.txt') # 删除文件result = {}
save_path = "infer.csv"f = open("infer.txt","r")
lines = f.readlines() #读取全部内容 ,并以列表方式返回count = 0for line in lines: # 先把前面的时间都干掉,然后将单引号换成双引号,就变成了json格式的文本了
txt = line.split(" root INFO: ")[1] # print(txt)
jsontxt = txt.replace("\'","\"") # print(jsontxt)
list_txt = json.loads(jsontxt) # print(list_txt)
for i in range(len(list_txt)):
name, ids = list_txt[i]['file_name'],list_txt[i]['class_ids']
onefilepath = name.split("/")[2].split(".")[0] # onefilepath = onefilepath
result[onefilepath] = ids[0]
count += 1# print(result)for i in range(1,count+1): with open('result.txt', 'a') as ff:
ff.write(str(result[str(i)])+'\n')print('写入成功')/home/aistudio 写入成功
以上就是『抽丝剥茧』深度解析PaddleClas—分类,一篇带你学会分类实践的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 195
195























