本文复现《Towards Deep Learning Models Resistant to Adversarial Attacks》,基于PaddlePaddle在MNIST数据集实现对抗训练,采用Min-Max思路与FGSM、PGD生成对抗样本,复现精度优于原文献,分析超参数影响及框架差异,为对抗防御提供参考。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

对抗攻击:攻击者就会通过设计一种有针对性的数值型向量从而让机器学习模型做出误判,这便被称为对抗性攻击,简单来说就是研究如何生成能使网络出错的样本。
根据条件不同,对抗攻击主要可分为:
本文从优化角度研究了神经网络的对抗鲁棒性问题,并在某种程度上提出了一种可以抵御任意攻击的思路。
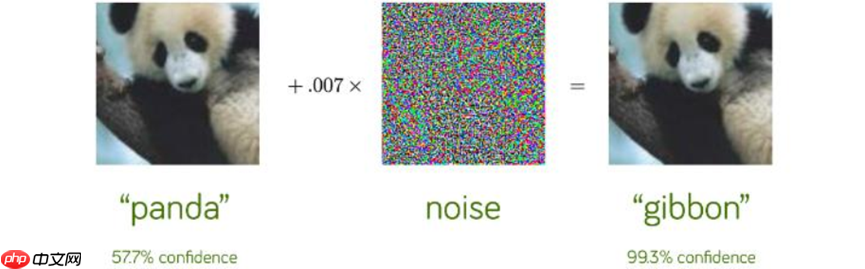
对抗攻击源于神经网络对输入信息的敏感性,当输入信息偏离模型训练样本的分布特征时,网络很可能给出错误的预测值。如果利用此漏洞,对输入信息做精细的改动,则可能导致网络以高置信度给出完全错误的预测。如下图所示,人眼完全无法分辨的差异,会导致网络输出错误结果。
本文提出的方法是,首先基于原始样本生成对抗样本,然后再基于对抗样本求解风险期望:
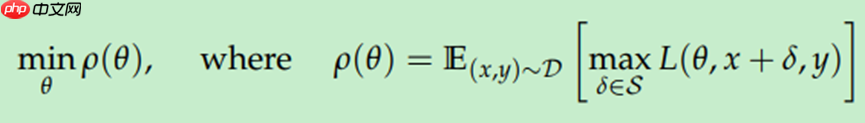
这种Min-Max问题,作者又称之为鞍点问题。Max求解的是,在固定网络参数的情况下,找出原始样本的一个偏移量,使得Loss函数在局部取得最大值,即为求出此时的对抗样本;Min求解的是,在得到对抗样本的情况下,根据梯度下降,使对抗样本的期望风险最小化。
对模型参数寻优,就是用常规的梯度下降法;关键是如何在局部找到原始样本的对抗样本,这个极大值问题。
寻找最优的对抗样本,常用的有两种方法:Fast Gradient Sign Method(FGSM)和Projected Gradient Decent(PGD)方法。
文中有一个有趣的结论是,模型越大,通过本方法获得的效果越好。我原本认为的是,模型对抗攻击鲁棒性差,可能是因为模型复杂导致了过拟合;但文章给出的结论正好相反,作者给出的原因如下图所示。
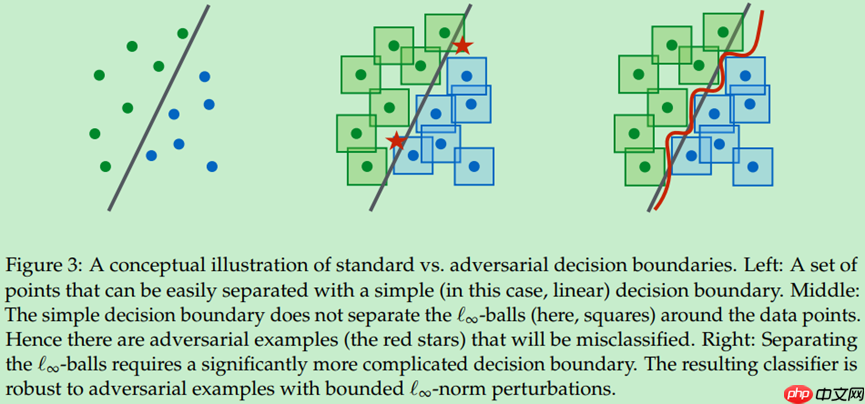
可以这样理解,文中的方法在客观上等效于随机引入了大量样本参与训练,epsilon邻域越大,参与训练的样本量越大,模型规模也应该同步增加。
论文链接:Towards Deep Learning Models Resistant to Adversarial Attacks
基于paddlepaddle深度学习框架,对文献算法进行复现后,汇总各测试条件下的测试精度,如下表所示。
| 任务 | 本项目精度 | 原文献精度 |
|---|---|---|
| PGD-steps100-restarts20-sourceA | 92.555% | 89.3% |
| PGD-steps100-restarts20-sourceA‘ | 97.3955% | 95.7% |
| PGD-steps40-restarts1-sourceB | 97.22% | 96.4% |
超参数配置如下:
| 超参数名 | 设置值 |
|---|---|
| lr | 0.0003 |
| batch_size | 128 |
| epochs | 50 |
| alpha | 0.01 |
| steps | 100 |
| steps | 100/40 |
| restarts | 20 |
| epsilon | 0.3 |
本项目使用的是MNIST数据集。
MNIST数据集是机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
该数据集为美国国家标准与技术研究所(National Institute of Standards and Technology (NIST))发起整理,一共统计了来自250个不同的人手写数字图片,其中50%是高中生,50%来自人口普查局的工作人员。该数据集的收集目的是希望通过算法,实现对手写数字的识别。
数据集链接:MNIST
硬件:
框架:
其他依赖项:
%cd /home/aistudio/TDLMRAAI_paddle/ !python train.py --net robust --seed 0
python train.py --net robust --seed 10 建立不同参数的network,用于黑盒攻击A
建立不同参数的network,运行完毕后,模型参数文件保存在./checkpoints/MNIST/目录下,手动将该文件保存至./checkpoints/MNIST_BlackboxA目录下。
%cd /home/aistudio/TDLMRAAI_paddle/ !python train.py --net robust --seed 10
/home/aistudio/TDLMRAAI_paddle
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
/home/aistudio/TDLMRAAI_paddle/helper.py:13: UserWarning:
This call to matplotlib.use() has no effect because the backend has already
been chosen; matplotlib.use() must be called *before* pylab, matplotlib.pyplot,
or matplotlib.backends is imported for the first time.
The backend was *originally* set to 'module://ipykernel.pylab.backend_inline' by the following code:
File "train.py", line 9, in <module>
import helper
File "/home/aistudio/TDLMRAAI_paddle/helper.py", line 2, in <module>
import matplotlib.pyplot as plt
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/pyplot.py", line 71, in <module>
from matplotlib.backends import pylab_setup
File "/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/backends/__init__.py", line 16, in <module>
line for line in traceback.format_stack()
matplotlib.use('Agg')
Time passed [minutes]: 0.00. execution date (d/m/y): 17/08/2021, 15:12:33
Time passed [minutes]: 0.00. Dataset name: MNIST
Time passed [minutes]: 0.00. checkpoints folder: ./checkpoints/MNIST
Time passed [minutes]: 0.00. save checkpoints: True
Time passed [minutes]: 0.00. load checkpoints: False
Time passed [minutes]: 0.00. results folder: ./results_folder/MNIST
Time passed [minutes]: 0.00. show results: False
Time passed [minutes]: 0.00. save results: False
Time passed [minutes]: 0.00. seed: 10
Time passed [minutes]: 0.00. execution device: CUDAPlace(0)
W0817 15:12:37.464154 2714 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0817 15:12:37.468314 2714 device_context.cc:422] device: 0, cuDNN Version: 7.6.
Time passed [minutes]: 0.11. Train model on MNIST-ORIGIN-NET
Time passed [minutes]: 0.11.
Full Train(training on all training dataset) with selected hp: {'lr': 0.0003, 'batch_size': 128, 'alpha': 0.01, 'steps': 100, 'epsilon': 0.3}
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/varbase_patch_methods.py:382: UserWarning: Warning:
tensor.grad will return the tensor value of the gradient. This is an incompatible upgrade for tensor.grad API. It's return type changes from numpy.ndarray in version 2.0 to paddle.Tensor in version 2.1.0. If you want to get the numpy value of the gradient, you can use :code:`x.grad.numpy()`
warnings.warn(warning_msg)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
Time passed [minutes]: 2.50. Epoch 1. Train adversarial accuracy: 0.054538.Train accuracy: 0.21, Train loss: 2.57
Time passed [minutes]: 4.85. Epoch 2. Train adversarial accuracy: 0.130375.Train accuracy: 0.43, Train loss: 2.29
Time passed [minutes]: 7.27. Epoch 3. Train adversarial accuracy: 0.286514.Train accuracy: 0.76, Train loss: 2.05
Time passed [minutes]: 9.65. Epoch 4. Train adversarial accuracy: 0.368876.Train accuracy: 0.87, Train loss: 1.81
Time passed [minutes]: 11.98. Epoch 5. Train adversarial accuracy: 0.429538.Train accuracy: 0.90, Train loss: 1.60
Time passed [minutes]: 14.32. Epoch 6. Train adversarial accuracy: 0.486385.Train accuracy: 0.92, Train loss: 1.42
Time passed [minutes]: 16.65. Epoch 7. Train adversarial accuracy: 0.530661.Train accuracy: 0.93, Train loss: 1.28
Time passed [minutes]: 18.98. Epoch 8. Train adversarial accuracy: 0.568308.Train accuracy: 0.94, Train loss: 1.16
Time passed [minutes]: 21.33. Epoch 9. Train adversarial accuracy: 0.600074.Train accuracy: 0.94, Train loss: 1.08
Time passed [minutes]: 23.75. Epoch 10. Train adversarial accuracy: 0.622018.Train accuracy: 0.94, Train loss: 1.01
Time passed [minutes]: 26.16. Epoch 11. Train adversarial accuracy: 0.643901.Train accuracy: 0.95, Train loss: 0.96
Time passed [minutes]: 28.60. Epoch 12. Train adversarial accuracy: 0.665317.Train accuracy: 0.95, Train loss: 0.90
Time passed [minutes]: 30.99. Epoch 13. Train adversarial accuracy: 0.683136.Train accuracy: 0.95, Train loss: 0.86
Time passed [minutes]: 33.43. Epoch 14. Train adversarial accuracy: 0.696867.Train accuracy: 0.96, Train loss: 0.82
Time passed [minutes]: 35.83. Epoch 15. Train adversarial accuracy: 0.718922.Train accuracy: 0.96, Train loss: 0.77
Time passed [minutes]: 38.21. Epoch 16. Train adversarial accuracy: 0.743626.Train accuracy: 0.96, Train loss: 0.71
Time passed [minutes]: 40.60. Epoch 17. Train adversarial accuracy: 0.764692.Train accuracy: 0.96, Train loss: 0.66
Time passed [minutes]: 43.01. Epoch 18. Train adversarial accuracy: 0.781033.Train accuracy: 0.96, Train loss: 0.61
Time passed [minutes]: 45.42. Epoch 19. Train adversarial accuracy: 0.794921.Train accuracy: 0.96, Train loss: 0.58
Time passed [minutes]: 47.80. Epoch 20. Train adversarial accuracy: 0.808735.Train accuracy: 0.96, Train loss: 0.54
Time passed [minutes]: 50.19. Epoch 21. Train adversarial accuracy: 0.819841.Train accuracy: 0.97, Train loss: 0.51
Time passed [minutes]: 52.60. Epoch 22. Train adversarial accuracy: 0.835027.Train accuracy: 0.97, Train loss: 0.47
Time passed [minutes]: 54.99. Epoch 23. Train adversarial accuracy: 0.850030.Train accuracy: 0.97, Train loss: 0.43
Time passed [minutes]: 57.41. Epoch 24. Train adversarial accuracy: 0.868759.Train accuracy: 0.97, Train loss: 0.38
Time passed [minutes]: 59.80. Epoch 25. Train adversarial accuracy: 0.879603.Train accuracy: 0.97, Train loss: 0.35
Time passed [minutes]: 62.17. Epoch 26. Train adversarial accuracy: 0.885767.Train accuracy: 0.97, Train loss: 0.33
Time passed [minutes]: 64.56. Epoch 27. Train adversarial accuracy: 0.890181.Train accuracy: 0.97, Train loss: 0.32
Time passed [minutes]: 66.95. Epoch 28. Train adversarial accuracy: 0.894540.Train accuracy: 0.97, Train loss: 0.31
Time passed [minutes]: 69.33. Epoch 29. Train adversarial accuracy: 0.899015.Train accuracy: 0.97, Train loss: 0.30
Time passed [minutes]: 71.73. Epoch 30. Train adversarial accuracy: 0.900337.Train accuracy: 0.98, Train loss: 0.29
Time passed [minutes]: 74.19. Epoch 31. Train adversarial accuracy: 0.903568.Train accuracy: 0.98, Train loss: 0.28
Time passed [minutes]: 76.72. Epoch 32. Train adversarial accuracy: 0.905889.Train accuracy: 0.98, Train loss: 0.27
Time passed [minutes]: 79.12. Epoch 33. Train adversarial accuracy: 0.906944.Train accuracy: 0.98, Train loss: 0.27
Time passed [minutes]: 81.50. Epoch 34. Train adversarial accuracy: 0.908571.Train accuracy: 0.98, Train loss: 0.27
Time passed [minutes]: 83.87. Epoch 35. Train adversarial accuracy: 0.908443.Train accuracy: 0.98, Train loss: 0.26
Time passed [minutes]: 86.32. Epoch 36. Train adversarial accuracy: 0.909648.Train accuracy: 0.98, Train loss: 0.26
Time passed [minutes]: 88.70. Epoch 37. Train adversarial accuracy: 0.911075.Train accuracy: 0.98, Train loss: 0.26
Time passed [minutes]: 91.14. Epoch 38. Train adversarial accuracy: 0.912408.Train accuracy: 0.98, Train loss: 0.26
Time passed [minutes]: 93.64. Epoch 39. Train adversarial accuracy: 0.912608.Train accuracy: 0.98, Train loss: 0.25
Time passed [minutes]: 96.08. Epoch 40. Train adversarial accuracy: 0.912519.Train accuracy: 0.98, Train loss: 0.25
Time passed [minutes]: 98.48. Epoch 41. Train adversarial accuracy: 0.914440.Train accuracy: 0.98, Train loss: 0.25
Time passed [minutes]: 100.91. Epoch 42. Train adversarial accuracy: 0.915734.Train accuracy: 0.98, Train loss: 0.24
Time passed [minutes]: 103.34. Epoch 43. Train adversarial accuracy: 0.917128.Train accuracy: 0.98, Train loss: 0.24
Time passed [minutes]: 105.77. Epoch 44. Train adversarial accuracy: 0.917283.Train accuracy: 0.98, Train loss: 0.24
Time passed [minutes]: 108.19. Epoch 45. Train adversarial accuracy: 0.919504.Train accuracy: 0.98, Train loss: 0.23
Time passed [minutes]: 113.07. Epoch 47. Train adversarial accuracy: 0.920781.Train accuracy: 0.98, Train loss: 0.23
Time passed [minutes]: 115.47. Epoch 48. Train adversarial accuracy: 0.922358.Train accuracy: 0.98, Train loss: 0.22
Time passed [minutes]: 117.85. Epoch 49. Train adversarial accuracy: 0.923474.Train accuracy: 0.99, Train loss: 0.22
Time passed [minutes]: 120.26. Epoch 50. Train adversarial accuracy: 0.924007.Train accuracy: 0.99, Train loss: 0.22
Time passed [minutes]: 120.26. training selected hyperparams: {'lr': 0.0003, 'batch_size': 128, 'alpha': 0.01, 'steps': 100, 'epsilon': 0.3}
Time passed [minutes]: 120.27. %accuracy on attack: 0.9287109375 with hp: {'epsilon': 0.3}
Time passed [minutes]: 120.27. FGSM attack selected hyperparams: {'epsilon': 0.3}
Time passed [minutes]: 120.38. %accuracy on attack: 0.8938802083333334 with hp: {'alpha': 0.01, 'steps': 100, 'epsilon': 0.3}
Time passed [minutes]: 120.38. PGD attack selected hyperparams: {'alpha': 0.01, 'steps': 100, 'epsilon': 0.3}
Time passed [minutes]: 120.99. TEST SCORES of MNIST-ORIGIN-NET with PGD adversarial training:
Time passed [minutes]: 120.99. accuracy on test: 0.9807
Time passed [minutes]: 120.99. accuracy on FGSM constructed examples: 0.946
Time passed [minutes]: 120.99. accuracy on PGD constructed examples: 0.9163
Time passed [minutes]: 120.99. save network to ./checkpoints/MNIST/MNIST-ORIGIN-NET with PGD adversarial training.pdparamspython train.py --net diff_arch --seed 0 建立不同架构的network,用于黑盒攻击B
建立不同架构的network,运行完毕后,模型参数文件保存在./checkpoints/MNIST/目录下,手动将该文件保存至./checkpoints/MNIST_BlackboxB目录下。
%cd /home/aistudio/TDLMRAAI_paddle/ !python train.py --net diff_arch --seed 0
python test.py --method white --num_restarts 20 用于白盒测试,对应PGD-steps100-restarts20-sourceA
%cd /home/aistudio/TDLMRAAI_paddle/ !python test.py --method white --num_restarts 20
python test.py --method blackA --num_restarts 20 用于网络架构已知,参数未知的黑盒测试,对应PGD-steps100-restarts20-sourceA’
%cd /home/aistudio/TDLMRAAI_paddle/ !python test.py --method blackA --num_restarts 20
python test.py --method blackB --num_restarts 1 用于网络架构未知黑盒测试,对应PGD-steps40-restarts1-sourceB
%cd /home/aistudio/TDLMRAAI_paddle/ !python test.py --method blackB --num_restarts 1
在不同的超参数配置下,模型的收敛效果、达到的精度指标有较大的差异,以下列举不同超参数配置下,实验结果的差异性,便于比较分析:
(1)学习率:
原文献采用的优化器与本项目一致,为Adam优化器,原文献学习率设置为0.0001,本项目经调参发现, 学习率设置为0.0003能够更快、更好地收敛。不同学习率在训练时,对攻击样本的精度和loss函数如下图所示。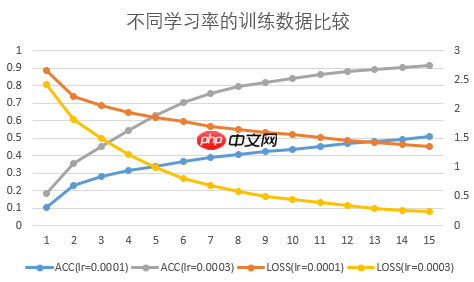
(2)训练时,是否加入原始样本:
根据本项目所参考的 repo 描述,训练时加入原始样本,有利于模型精度的提高。本项目分别在相同超参数配置下,比较了是否加入原始样本进行训练的实验结果,如下表所示。
| 测试项 | add origin samples | no original samples |
|---|---|---|
| 测试集ACC | 98.86% | 98.56% |
| FGSM攻击ACC | 96.17% | 96.31% |
| PGD攻击ACC | 92.45% | 93.44% |
原文献作者算法,训练时只针对生成的对抗样本,训练时不加入原始样本。通过上表对比数据可知, 增加原始样本,有利于微小提升真实样本的准确率(0.3%),但会导致攻击样本准确率略有下降。
但总体上,对指标影响很小。
(3)initialer
(4)batch_size
(5)epoch轮次
本项目训练时,采用的epoch轮次为50。LOSS和对抗准确率基本稳定,模型处于收敛状态,如下图所示。 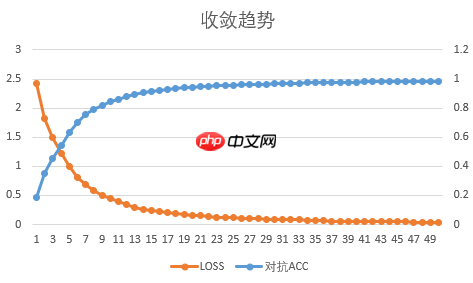
本次论文复现,由于论文作者并未给出原始的模型参考实现,仅提供了部分基于TensorFlow的部分代码,复现难度比较大。 前期除了对文献本身研读以外,同时在网上查阅了很多资料,以及同领域的相似实现代码。论文复现过程中, 所学到的领域知识,令我获益匪浅,对对抗攻击方向的研究也有了更深入的理解。
纸上得来终觉浅,绝知此事要躬行。古人诚不欺我!
除了文献本身的理论学习,在项目实现过程中,细致比较了pytorch和paddle框架的实现异同。 譬如,模型的初始化方式,pytorch默认采用kaiming_normal进行初始化;而paddle默认采用Xavier_normal。 对于一般的网络训练,仅仅初始化部分的微小差异通常不会引起大问题,但项目似有不同。
本项目开始使用paddle的默认初始化,即Xavier_normal,通常这种方式在大多数网络下都是最佳的初始化配置方式。但本项目在Xavier_normal初始化后, 网络收敛速度极慢,精度也比较差,迟迟不能达到论文指标。经反复研究比较,改用kaiming_normal后,才真正与pytorch对齐,精度也达到了理想状态。
训练完成后,模型保存在checkpoints目录下。
训练日志保存在results_folder目录下,测试日志保存在test_results_folder目录下。
| 信息 | 说明 |
|---|---|
| 发布者 | hrdwsong |
| 时间 | 2021.08 |
| 框架版本 | Paddle 2.1.2 |
| 应用场景 | 对抗训练 |
| 支持硬件 | GPU、CPU |
| github地址 | https://github.com/hrdwsong/TDLMR2AA-Paddle |
以上就是论文复现赛:对抗攻击的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 428
428























