该项目是对联生成系统的升级版本,从简单界面可视化升级为Android APP。项目用Seq2seq框架,先处理对联数据,建立语料库和字典,划分数据集并封装。接着搭建Encoder、AttentionLayer等网络组件,定义损失函数和超参数后训练模型。还涉及模型预测及动态图转静态图,最后进行Android开发,生成opt模型并编写相关代码实现功能。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

该项目是我之前精品项目使用Seq2seq框架搭建对联生成系统的升级版本。在之前的项目中,我仅实现了简单的界面可视化,现在升级到了Android APP,嘿嘿!
安卓代码及APP下载地址:点我
import ioimport osimport numpy as npimport paddleimport paddlenlpfrom functools import partialfrom paddle.static import InputSpec
data_in_path="/home/aistudio/data/data110057/fixed_couplets_in.txt"data_out_path="/home/aistudio/data/data110057/fixed_couplets_out.txt"
def openfile(src):
with open(src,'r',encoding="utf-8") as source:
lines=source.readlines() return linesdata_in=openfile(data_in_path) data_out=openfile(data_out_path)
print(len(data_in))print(len(data_out))print(data_in[0])print(data_out[0])print(len(data_in[0]))
744915 744915 腾 飞 上 铁 , 锐 意 改 革 谋 发 展 , 勇 当 千 里 马 和 谐 南 供 , 安 全 送 电 保 畅 通 , 争 做 领 头 羊 37
def delete_newline_and_space(lista):
newlist=[] for i in range(len(lista)):
newlist.append(["<start>"]+lista[i].strip().split()+['<end>']) return newlistdata_in_nospace=delete_newline_and_space(data_in) data_out_nospace=delete_newline_and_space(data_out)print(data_in_nospace[0])print(data_out_nospace[0])
['<start>', '腾', '飞', '上', '铁', ',', '锐', '意', '改', '革', '谋', '发', '展', ',', '勇', '当', '千', '里', '马', '<end>'] ['<start>', '和', '谐', '南', '供', ',', '安', '全', '送', '电', '保', '畅', '通', ',', '争', '做', '领', '头', '羊', '<end>']
计算最长的对联长度couplet_maxlen,并将该长度+2作为向量长。不足进行填充。
couplet_maxlen=max([len(i) for i in data_in_nospace]) couplet_maxlen
34
有个问题: 输入输出的语料库是二者分别建立一个,还是二者一起建立一个?
在这里建立一个统一的语料库进行实验。(毕设的时候我是分开建的,不知道哪个做法正确)
def bulid_cropus(data_in,data_out):
crpous=[] for i in data_in:
crpous.extend(i) for i in data_out:
crpous.extend(i) return crpousdef build_dict(corpus,frequency):
# 首先统计不同词(汉字)的频率,使用字典记录
word_freq_dict={} for ch in corpus: if ch not in word_freq_dict:
word_freq_dict[ch]=0
word_freq_dict[ch]+=1
# 根据频率对字典进行排序
word_freq_dict=sorted(word_freq_dict.items(),key=lambda x:x[1],reverse=True)
word2id_dict={}
id2word_dict={}
# 按照频率,从高到低,开始遍历每个单词,并赋予第一无二的 id
for word,freq in word_freq_dict: if freq>frequency:
curr_id=len(word2id_dict)
word2id_dict[word]=curr_id
id2word_dict[curr_id]=word else:
# else 部分在 使 单词 指向unk,对于汉字,我们不设置unk,令frequency=0
word2id_dict[word]=1
return word2id_dict,id2word_dictword_frequency=0word2id_dict,id2word_dict=build_dict(bulid_cropus(data_in_nospace,data_out_nospace),word_frequency)
词汇量大小
word_size=len(word2id_dict)
id_size=len(id2word_dict)print("汉字个数:",word_size,"\n id个数:",id_size)汉字个数: 9017 id个数: 9017
with open("word2id.txt",'w',encoding='utf-8') as w2i: for k,v in word2id_dict.items():
w2i.write(str(k)+","+str(v)+'\n')with open("id2word.txt",'w',encoding='utf-8') as w2i: for k,v in id2word_dict.items():
w2i.write(str(k)+","+str(v)+'\n')print(word2id_dict['<end>'])print(word2id_dict['<start>'])
1 0
创建 tensor
def getensor(w2i,datalist,maxlength):
in_tensor=[] for lista in datalist:
in_samll_tensor=[] for li in lista:
in_samll_tensor.append(w2i[li])# if len(in_samll_tensor)<maxlength:# in_samll_tensor+=[w2i['<end>']]*(maxlength-len(in_samll_tensor))
in_tensor.append(in_samll_tensor) return in_tensorin_tensor=getensor(word2id_dict,data_in_nospace,couplet_maxlen) out_tensor=getensor(word2id_dict,data_out_nospace,couplet_maxlen)
转成数字,带上shape属性
in_tensor=np.array(in_tensor) out_tensor=np.array(out_tensor)
train_in_tensor=in_tensor[:595933] val_in_tensor=in_tensor[595933:670424] test_in_tensor=in_tensor[670424:] train_out_tensor=out_tensor[:595933] val_out_tensor=out_tensor[595933:670424] test_out_tensor=out_tensor[670424:]
print(len(train_in_tensor),len(test_in_tensor),len(val_in_tensor))
595933 74491 74491
# 1.继承paddle.io.Datasetclass Mydataset(paddle.io.Dataset):
# 2. 构造函数,定义数据集大小
def __init__(self,first,second):
super(Mydataset,self).__init__()
self.first=first
self.second=second
# 3. 实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
def __getitem__(self,index):
return self.first[index],self.second[index]
# 4. 实现__len__方法,返回数据集总数目
def __len__(self):
return self.first.shape[0]train_tensor=Mydataset(train_in_tensor,train_out_tensor) val_tensor=Mydataset(val_in_tensor,val_out_tensor) test_tensor=Mydataset(test_in_tensor,test_out_tensor)
数据加载
BATCH_SIZE=64padid=word2id_dict['<end>']
def prepare_input(inputs,padid):
src,src_length=paddlenlp.data.Pad(pad_val=padid,ret_length=True)([inputsub[0] for inputsub in inputs])
trg,trg_length=paddlenlp.data.Pad(pad_val=padid,ret_length=True)([inputsub[1] for inputsub in inputs]) #src=src.astype(paddle.get_default_dtype())
trg_mask =(trg[:,:-1]!=padid).astype(paddle.get_default_dtype()) return src,src_length,trg[:,:-1],trg[:,1:,np.newaxis],trg_maskdef create_data_loader(dataset):
data_loader=paddle.io.DataLoader(dataset,batch_sampler=None,batch_size=BATCH_SIZE,collate_fn=partial(prepare_input, padid=padid)) return data_loadertrain_loader=create_data_loader(train_tensor) val_loader=create_data_loader(val_tensor) test_loader=create_data_loader(test_tensor)
# j=0# for i in train_loader:# print(len(i))# for ind,each in enumerate(i):# print(ind,each.shape,each)# #print(ind,each.shape)# j+=1# if j==2:# break
<br/>
# for i in train_loader:# x,x_length,y,_,_= i# break# # print(x)
class Encoder(paddle.nn.Layer):
def __init__(self,vocab_size,embedding_dim,hidden_size,num_layers):
super(Encoder,self).__init__()
self.embedding=paddle.nn.Embedding(vocab_size,embedding_dim)
self.lstm=paddle.nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers,
dropout=0.2 if num_layers>1 else 0)
# src_length 的形状为[batch_size],作用是控制inputs中的time_step超过[batch_size]的不再更新状态,就是那些填充
def forward(self,src,src_length):
inputs=self.embedding(src) # [batch_size,time_steps,embedding_dim]
encoder_out,encoder_state=self.lstm(inputs,sequence_length=src_length) # out[batch_szie,time_steps,hidden_size] state:[[num_layers*1,batch_size,hidden_size],[num_layers*1,batch_size,hidden_size]]
# encoder_out,encoder_state=self.lstm(inputs)
return encoder_out,encoder_state# encoder=Encoder(word_size,256,128,2)# #paddle.summary(encoder,[(64,18),(64)],dtypes='int64')# out,state=encoder(x,x_length)# print(out.shape)# print(state)
class AttentionLayer(paddle.nn.Layer):
def __init__(self,hidden_size):
super(AttentionLayer,self).__init__()
self.attn1=paddle.nn.Linear(hidden_size,hidden_size)
self.attn2=paddle.nn.Linear(hidden_size+hidden_size,hidden_size) def forward(self,decoder_hidden_h,encoder_output,encoder_padding_mask):
encoder_output=self.attn1(encoder_output) # [batch_size,time_steps,hidden_size]
# decodr_hidden_h 的形状 [batch_size,hidden_size],是lstm公式中的ht.
# unsqueeze之后[batch_size,1,hidden_size]
# transpose_y=True,后两维转置 [batch_size,hidden_size,time_steps]
# matmul之后的 形状 [batch_size,1,time_steps]
a=paddle.unsqueeze(decoder_hidden_h,[1]) # print(a.shape)
# print(encoder_output.shape)
attn_scores=paddle.matmul(a,encoder_output,transpose_y=True)
# 注意力机制中增加掩码操作,在padding 位加上个非常小的数:-1e9
if encoder_padding_mask is not None: # encoder_padding_mask的形状为[batch_size,1,time_steps]
attn_scores=paddle.add(attn_scores,encoder_padding_mask) # softmax操作,默认是最后一个维度,axis=-1,形状不变
attn_scores=paddle.nn.functional.softmax(attn_scores)
# [batch_size,1,time_steps]*[batch_size,time_steps,hidden_size]-->[batch_size,1,hidden_size]
# squeeze之后:[batch_size,hidden_size]
attn_out=paddle.squeeze(paddle.matmul(attn_scores,encoder_output),[1])
# concat之后 [batch_size,hidden_size+hidden_size]
attn_out=paddle.concat([attn_out,decoder_hidden_h],1) # 最终结果[batch_size,hidden_size]
attn_out=self.attn2(attn_out) return attn_outclass DecoderCell(paddle.nn.RNNCellBase):
def __init__(self,num_layers,embedding_dim,hidden_size):
super(DecoderCell,self).__init__()
self.dropout=paddle.nn.Dropout(0.2)
self.lstmcells=paddle.nn.LayerList([paddle.nn.LSTMCell(
input_size=embedding_dim+hidden_size if i==0 else hidden_size,
hidden_size=hidden_size
) for i in range(num_layers)])
self.attention=AttentionLayer(hidden_size)
def forward(self,decoder_input,decoder_initial_states,encoder_out,encoder_padding_mask=None):
#forward 函数会执行squence_len次 ,每次的decoder_input 为[batch_size,embeddding_dim]
# 状态分解 states [encoder_final_states,decoder_init_states]
# encoder_final_states [num_layes,batch_size,hiden_size] ???
# decoder_init_states [] ???
encoder_final_states,decoder_init_states=decoder_initial_states #num_layers=len(encoder_final_states[0])
#decoder_init_states=lstm_init_state
# ???
new_lstm_states=[] # decoder_input: [batch_size,embedding_dim]
# print("decodercell ",decoder_input.shape)
inputs=paddle.concat([decoder_input,decoder_init_states],1) # print("concant之后",inputs.shape)
for i ,lstm_cell in enumerate(self.lstmcells): # inputs 的形状为 [batch_size,input_size] input_size:输入的大小
state_h,new_lstm_state=lstm_cell(inputs,encoder_final_states[i])
inputs=self.dropout(state_h)
new_lstm_states.append(new_lstm_state)
state_h=self.attention(inputs,encoder_out,encoder_padding_mask) # print(state_h.shape)
return state_h,[new_lstm_states,state_h]解码器由embedding+解码器单元+线性输出层组成
class Decoder(paddle.nn.Layer):
def __init__(self,vocab_size,embedding_dim,hidden_size,num_layers):
super(Decoder,self).__init__()
self.embedding=paddle.nn.Embedding(vocab_size,embedding_dim)
self.lstm_attention=paddle.nn.RNN(DecoderCell(num_layers,embedding_dim,hidden_size))
self.fianl=paddle.nn.Linear(hidden_size,vocab_size) def forward(self,trg, decoder_initial_states,encoder_output,encoder_padding_mask):
# trg 的形状为 [batch_size,sequence_length]
# embedding 之后, [batch_size,sequence_length,embedding_dim]
inputs=self.embedding(trg) # print("embedding 后的 输入维度",inputs.shape)
# decodr_out [batch_szie,hidden_size]
decoder_out,_ = self.lstm_attention(inputs,
initial_states=decoder_initial_states,
encoder_out=encoder_output,
encoder_padding_mask=encoder_padding_mask) # predict [batch_size,sequence_len,word_size]
predict=self.fianl(decoder_out) # print("最后的维度",decoder_out.shape)
return predictclass Seq2Seq(paddle.nn.Layer):
def __init__(self, vocab_size,embedding_dim,hidden_size,num_layers,eos_id):
super(Seq2Seq,self).__init__()
self.hidden_size=hidden_size
self.eos_id=eos_id
self.num_layers=num_layers
self.INF= 1e9
self.encoder=Encoder(vocab_size,embedding_dim,hidden_size,num_layers)
self.decoder=Decoder(vocab_size,embedding_dim,hidden_size,num_layers)
def forward(self,src,src_length,trg):
# encoder_output 的形状为[batch_size,sequence_len,hidden_size]
# encoder_final_state ([num_layers*1,batch_size,hidden_size],[num_layers*1,batch_size,hidden_size]]) tuple类型
encoder_output,encoder_final_state=self.encoder(src,src_length)
encoder_final_states=[(encoder_final_state[0][i],encoder_final_state[1][i]) for i in range(self.num_layers)] #print(encoder_final_states[0])
# [batch_size,hidden_size] 初始化为0
#lstm_init_state= self.decoder.lstm_attention.cell.get_initial_states(batch_ref=encoder_output,shape=[self.hidden_size])
decoder_initial_states=[encoder_final_states,
self.decoder.lstm_attention.cell.get_initial_states(batch_ref=encoder_output,shape=[self.hidden_size])]
src_mask=(src!=self.eos_id).astype(paddle.get_default_dtype())
encoder_mask=(src_mask-1)*self.INF
encoder_padding_mask=paddle.unsqueeze(encoder_mask,[1])
predict=self.decoder(trg,decoder_initial_states,encoder_output,encoder_padding_mask) return predictclass CrossEntropy(paddle.nn.Layer):
def __init__(self):
super(CrossEntropy,self).__init__() def forward(self,pre,real,trg_mask):
# 返回的数据类型与pre一致,除了axis维度(未指定则为-1),其他维度也与pre一致
# logits=pre,[batch_size,sequence_len,word_size],猜测会进行argmax操作,[batch_size,sequence_len,1]
# 默认的soft_label为False,lable=real,[bacth_size,sequence_len,1]
cost=paddle.nn.functional.softmax_with_cross_entropy(logits=pre,label=real)
# 删除axis=2 shape上为1的维度
# 返回结果的形状应为 [batch_size,sequence_len]
cost=paddle.squeeze(cost,axis=[2]) # trg_mask 的形状[batch_size,suqence_len]
# * 这个星号应该是对应位置相乘,返回结果的形状 [bathc_szie,sequence_len]
masked_cost=cost*trg_mask # paddle.mean 对应轴的对应位置求平均, 在这里返回结果为 [sequence_len]
# paddle.sum 求解方法与paddle.mean一致,最终返回的结果应为[1]
return paddle.sum(paddle.mean(masked_cost,axis=[0]))epochs=20eos_id=word2id_dict['<end>'] num_layers=2dropout_rate=0.2hidden_size=128embedding_dim=256max_grad_norm=5lr=0.001log_freq=200model_path='./train_model/train_model'
s2s=Seq2Seq(word_size,embedding_dim,hidden_size,num_layers,eos_id)
W0609 11:31:02.978509 1421 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0609 11:31:02.982554 1421 device_context.cc:422] device: 0, cuDNN Version: 7.6.
model=paddle.Model(s2s)# model.parameters() 返回一个包含所有模型参数的列表optimizer=paddle.optimizer.Adam(learning_rate=lr,parameters=model.parameters())# 困惑度ppl_metric=paddlenlp.metrics.Perplexity() model.prepare(optimizer,CrossEntropy(),ppl_metric)
#eval_freq 多少个epoch评估一次 #save_freq 多少个epoch保存模型一次
model.fit(train_data=train_loader, eval_data=val_loader, epochs=epochs, eval_freq=1, save_freq=2, save_dir=model_path, log_freq=log_freq, verbose=2, callbacks=[paddle.callbacks.VisualDL('./log')])
#保存用于预测的模型 #model.save("./infer_model/infer_model",False)
class Seq2SeqInfer(Seq2Seq):
def __init__(self,word_size,embedding_dim,hidden_size,num_layers,bos_id,eos_id,beam_size,max_out_len=couplet_maxlen):
self.bos_id=bos_id
self.beam_size=beam_size
self.max_out_len=max_out_len
self.num_layers=num_layers super(Seq2SeqInfer,self).__init__(word_size,embedding_dim,hidden_size,num_layers,eos_id)
self.beam_search_decoder=paddle.nn.BeamSearchDecoder(
self.decoder.lstm_attention.cell,
start_token=bos_id,
end_token=eos_id,
beam_size=beam_size,
embedding_fn=self.decoder.embedding,
output_fn=self.decoder.fianl)
def forward(self,src,src_length):
encoder_output,encoder_states=self.encoder(src,src_length)
encoder_final_state=[(encoder_states[0][i],encoder_states[1][i]) for i in range(self.num_layers)] # 初始化decoder的隐藏层状态
decoder_initial_states=[encoder_final_state,
self.decoder.lstm_attention.cell.get_initial_states(batch_ref=encoder_output,shape=[self.hidden_size])]
src_mask=(src!=self.eos_id).astype(paddle.get_default_dtype())
encoder_padding_mask=(src_mask-1.0)*self.INF
encoder_padding_mask=paddle.unsqueeze(encoder_padding_mask,[1]) # 扩展tensor的bacth维度
encoder_out=paddle.nn.BeamSearchDecoder.tile_beam_merge_with_batch(encoder_output,self.beam_size)
encoder_padding_mask=paddle.nn.BeamSearchDecoder.tile_beam_merge_with_batch(encoder_padding_mask,self.beam_size)
seq_output,_=paddle.nn.dynamic_decode( decoder=self.beam_search_decoder,
inits= decoder_initial_states,
max_step_num= self.max_out_len,
encoder_out=encoder_output,
encoder_padding_mask=encoder_padding_mask)
return seq_outputdef pre_process(seq,bos_idx,eos_idx):
#print(bos_idx,eos_idx)
# 结束位置
eos_pos=len(seq)-1
for i ,idx in enumerate(seq): #print(i,idx[0])
if idx==eos_idx: # 遇到结束标志
eos_pos=i break
seq=[idx[0] for idx in seq[:eos_pos] if (idx !=bos_idx) ] return seqbeam_size=1bos_id=word2id_dict['<start>'] eos_id=word2id_dict['<end>'] max_out_len=couplet_maxlenprint(bos_id)
0
x=paddle.to_tensor([[0 , 566, 566, 489, 42 , 165, 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]],dtype=paddle.int32) y=paddle.to_tensor([7],dtype=paddle.int32)print(x)print(y)
Tensor(shape=[1, 34], dtype=int32, place=CUDAPlace(0), stop_gradient=True,
[[0 , 566, 566, 489, 42 , 165, 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 ]])
Tensor(shape=[1], dtype=int32, place=CUDAPlace(0), stop_gradient=True,
[7])s2si=Seq2SeqInfer(word_size,embedding_dim,hidden_size,num_layers,bos_id,eos_id,beam_size,max_out_len)
dd=paddle.load('./trained_model/10.pdparams')
s2si.load_dict(dd)
net=paddle.jit.to_static(s2si)
out=net(x,y)
outTensor(shape=[1, 6, 1], dtype=int64, place=CUDAPlace(0), stop_gradient=False,
[[[4 ],
[24],
[11],
[75],
[7 ],
[1 ]]])paddle.jit.save(net, './trained_model/net')
! pip install paddlelite==2.11-rc
! paddle_lite_opt --model_file=./trained_model/net.pdmodel --param_file=./trained_model/net.pdiparams --optimize_out=./trained_model/v1_opt·
可以参考官方文档 Java完整示例
我使用的是2.11-rc版本
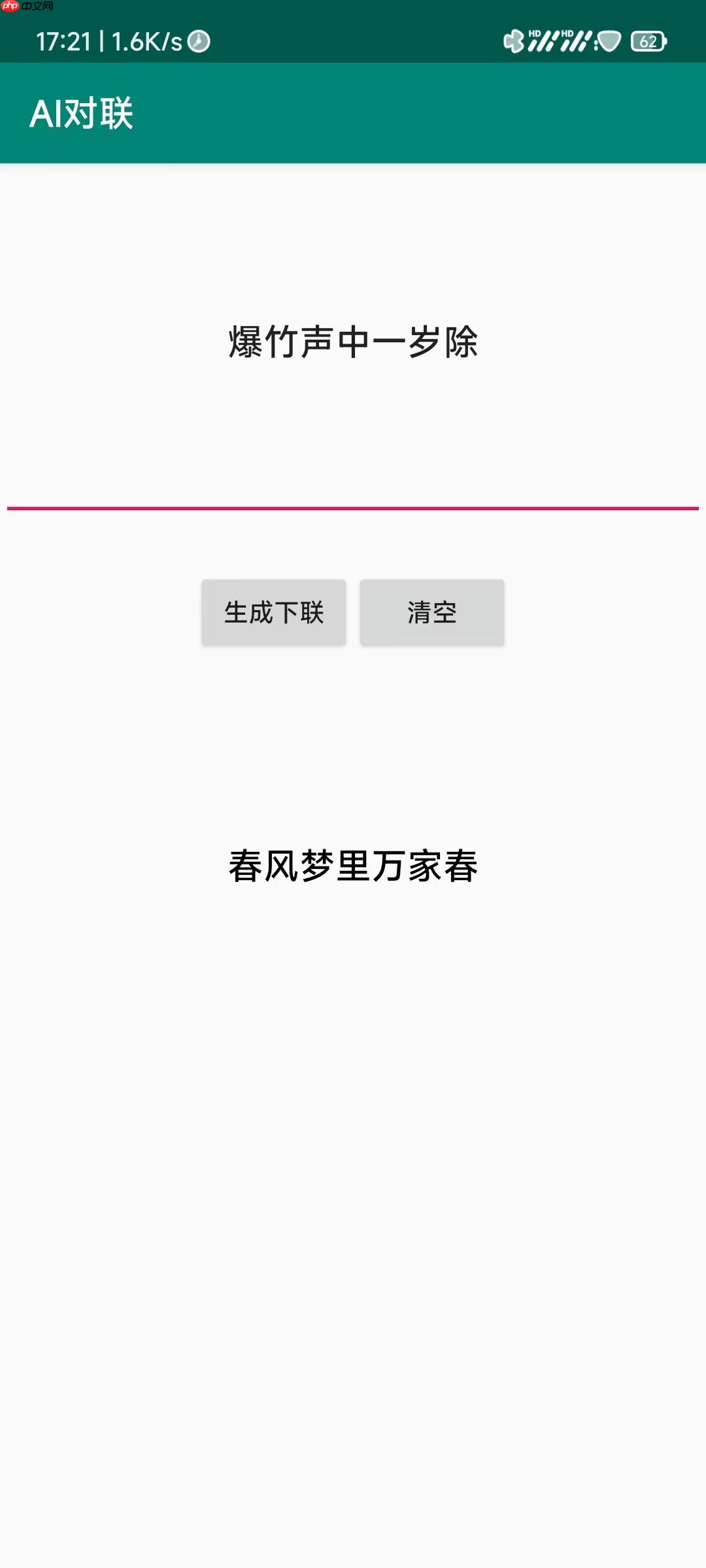
package com.baidu.paddle.lite;import android.content.Context;import android.support.v7.app.AppCompatActivity;import android.os.Bundle;import android.util.Log;import android.view.View;import android.widget.Button;import android.widget.EditText;import android.widget.TextView;import java.io.BufferedOutputStream;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.FileReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.io.OutputStream;import java.util.Date;import java.util.HashMap;import java.util.Map;public class MainActivity extends AppCompatActivity { public static final String TAG = "MainActivity"; private Button bt; private EditText et; public Map<String, String> word_id_map = new HashMap<String, String>(); public Map<String, String> id_word_map = new HashMap<String, String>();
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main); //bt=(Button)findViewById(R.id.bt1);// String path2="assets/word2id.txt";// String path2="assets/id2word.txt";
String np1 = copyFromAssetsToCache("word2id.txt", this); String np2 = copyFromAssetsToCache("id2word.txt", this); try {
word_id_map=readTxtToObject(np1);
} catch (IOException e) {
e.printStackTrace();
} try {
id_word_map=readTxtToObject(np2);
} catch (IOException e) {
e.printStackTrace();
}
} public void click(View v){ int id=v.getId(); switch (id) { case R.id.bt1:
Log.i("指定onClick属性方式","bt1点击事件");
et=(EditText) findViewById(R.id.text_in); String ss=et.getText().toString();// Log.i("指定onClick属性方式",ss);// Log.i("指定onClick属性方式", String.valueOf(ss.length()));// Log.i("指定onClick属性方式",word_id_map.toString());
int[] buffer1 = new int[]{0 , 1, 1, 1, 1 , 1, 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 }; for(int i=0;i<ss.length();i++) { //Log.i("指定onClick属性方式1", ss.substring(i, i+1));
//Log.i("指定onClick属性方式", word_id_map.get(ss.substring(i, i+1)));
buffer1[i+1]= Integer.parseInt(word_id_map.get(ss.substring(i, i+1))); if(i==34){ break;
}
} //long[] dims1 = {1, ss.length()};
long[] dims1 = {1, 34}; String re="";
Tensor output=runModel("v1_opt.nb", dims1, buffer1, this); long[] out = output.getLongData(); for(int i=0 ;i<out.length;i++){ if( out[i]==1 || i==ss.length()){ break;
}
Log.i("指定onClick属性方式1", String.valueOf(out[i]));
re+=id_word_map.get(String.valueOf(out[i]));
}
TextView textView = findViewById(R.id.text_view);
textView.setText(re); break; case R.id.bt2:
et=(EditText) findViewById(R.id.text_in);
textView=(TextView)findViewById(R.id.text_view);
textView.setText("");
et.setText(""); default: break;
}
} public static Map<String, String> readTxtToObject(String ppath) throws IOException {
Map<String, String> map = new HashMap<String, String>();
File f=new File(ppath); BufferedReader reader=new BufferedReader(new FileReader(f)); String lineTxt=null; while((lineTxt=reader.readLine())!=null){ String[] names = lineTxt.split(" "); map.put(names[0], names[1]);
} return map;
} public static String getVersionInfo(String modelName, Context context) { String modelPath = copyFromAssetsToCache(modelName, context); //Log.d(TAG,modelPath);
System.out.println(modelPath);
MobileConfig config = new MobileConfig();
config.setModelFromFile(modelPath);
PaddlePredictor predictor = PaddlePredictor.createPaddlePredictor(config); return predictor.getVersion(); //return modelPath;
} public static String copyFromAssetsToCache(String modelPath, Context context) { //context.getCacheDir():获取应用缓存目录
String newPath = context.getCacheDir() + "/" + modelPath; //创建file对象
File desDir = new File(newPath); try { // context.getAssets().open() 打开assets目录下的文件
// Inputstream 字节输入流的最顶层父类
InputStream stream = context.getAssets().open(modelPath); // 创建BufferedOutputStream字节缓冲输出流
OutputStream output = new BufferedOutputStream(new FileOutputStream(newPath)); byte data[] = new byte[1024]; int count; while ((count = stream.read(data)) != -1) {
output.write(data, 0, count);
}
output.flush();//刷新缓冲输出流
output.close();//关闭流
stream.close();
} catch (Exception e) { throw new RuntimeException(e);
} return desDir.getPath();
} public static Tensor runModel(String modelName, long[] dims1, int[] inputBuffer1,Context context) {// public static Tensor runModel(String modelName, long[] dims1, int[] inputBuffer1,// long[] dims2, int[] inputBuffer2, Context context) {
String modelPath = copyFromAssetsToCache(modelName, context);
MobileConfig config = new MobileConfig();
config.setModelFromFile(modelPath);
config.setPowerMode(PowerMode.LITE_POWER_HIGH);
config.setThreads(1);
PaddlePredictor predictor = PaddlePredictor.createPaddlePredictor(config);// System.out.println(predictor);// System.out.println(predictor.getVersion());
Tensor input1 = predictor.getInput(0);
input1.resize(dims1);
input1.setData(inputBuffer1);
predictor.run();
Tensor output = predictor.getOutput(0); return output;
} public static Tensor setInputAndRunNaiveModel(String modelName, Context context) { long[] dims1 = {1, 34}; int[] inputBuffer1 = new int[]{0 , 566, 566, 489, 42 , 165, 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 , 1 }; return runModel(modelName, dims1, inputBuffer1, context);
} public static String getSecond(String first,Context context){ String result=""; return result;
}
}<?xml version="1.0" encoding="utf-8"?><android.support.constraint.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<RelativeLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/rela"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:gravity="center"
tools:ignore="MissingConstraints">
<EditText
android:id="@+id/text_in"
android:layout_width="fill_parent"
android:layout_height="200dp"
android:textSize="20dp"
android:textStyle="bold"
android:hint="请输入上联"
android:gravity="center"
android:textColorHint="#95A1AA"
android:selectAllOnFocus="true"
tools:ignore="MissingConstraints" />
<LinearLayout
android:layout_width="match_parent"
android:layout_height="100dp"
android:layout_below="@id/text_in"
android:gravity="center"
>
<Button
android:id="@+id/bt1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_below="@id/text_in"
android:text="生成下联"
android:onClick="click"
tools:ignore="MissingConstraints" />
<Button
android:id="@+id/bt2"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_below="@id/text_in"
android:layout_toRightOf="@id/bt1"
android:text="清空"
android:onClick="click"
tools:ignore="MissingConstraints" />
</LinearLayout>
</RelativeLayout>
<TextView
android:id="@+id/text_view"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="欢迎使用AI对联系统"
android:padding="3dp"
android:textSize="20dp"
android:textStyle="bold"
android:textColor="#000"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent" /></android.support.constraint.ConstraintLayout>以上就是【NLP+Android】AI 对联 APP的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 195
195






















