
数据湖是当前备受关注的一个概念,许多企业正在构建或计划构建自己的数据湖。在启动数据湖项目之前,理解数据湖的本质,明确数据湖项目的基本组成,并设计出数据湖的基本架构,对于成功构建数据湖至关重要。关于数据湖的定义,存在多种解释。
维基百科指出,数据湖是一种系统或存储仓库,用于以自然或原始格式存储数据,通常是对象块或文件。这包括原始系统生成的原始数据拷贝以及为各种任务转换而生成的数据,如关系数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如电子邮件、文档、PDF等)和二进制数据(如图像、音频、视频)。
AWS定义数据湖为一个集中式的存储库,允许以任意规模存储所有结构化和非结构化数据。
微软的定义较为模糊,并未直接定义数据湖,而是通过描述其功能来定义。数据湖包括所有使得开发者、数据科学家、分析师能够更简单地存储、处理数据的能力。这些能力使得用户能够存储任意规模、任意类型、任意生成速度的数据,并跨平台、跨语言进行各种类型的分析和处理。
关于数据湖的定义虽然众多,但基本上都围绕以下几个特性展开:
综上所述,个人认为数据湖应该是一种不断演进、可扩展的大数据存储、处理、分析的基础设施,以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理,并通过与各类外部异构数据源的交互集成,支持各类企业级应用。
数据湖调研1、Iceberg
Iceberg作为新兴的数据湖框架之一,开创性地抽象出“表格式”(table format)这一中间层,既独立于上层的计算引擎(如Spark和Flink)和查询引擎(如Hive和Presto),也与下层的文件格式(如Parquet,ORC和Avro)解耦。
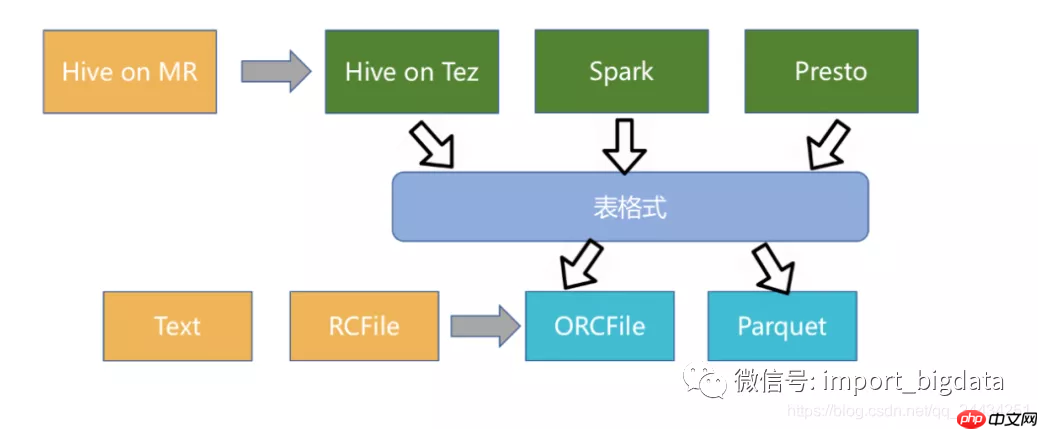
此外,Iceberg还提供了许多额外的能力:
Iceberg的架构和实现并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如Flink、Hive、Spark)对接。因此,Iceberg的架构更加优雅,对于数据格式、类型系统有完备的定义和可进化的设计。
但是,Iceberg缺少行级更新、删除能力,这两大能力是现有数据组织最大的卖点,社区仍在优化中。
2、Hudi
Hudi通常用来将大量数据存储到HDFS/S3,新数据增量写入,而旧数据鲜有改动,特别是在经过数据清洗后放入数据仓库的场景。
在数据仓库如Hive中,对于update的支持非常有限,计算昂贵。
另一方面,若是有仅对某段时间内新增数据进行分析的场景,则Hive、Presto、HBase等也未提供原生方式,而是需要根据时间戳进行过滤分析。
Apache Hudi代表Hadoop Upserts and Incrementals,能够使HDFS数据集在分钟级的时延内支持变更,也支持下游系统对这个数据集的增量处理。
Hudi数据集通过自定义的inputFormat兼容当前Hadoop生态系统,包括Apache Hive,Apache Parquet,Presto和Apache Spark,使得终端用户可以无缝对接。

Hudi存储的架构如下图所示:

如上图,最下面有一个时间轴,这是Hudi的核心。Hudi会维护一个时间轴,在每次执行操作时(如写入、删除、合并等),均会带有一个时间戳。通过时间轴,可以实现仅查询某个时间点之后成功提交的数据,或是仅查询某个时间点之前的数据。这样可以避免扫描更大的时间范围,并非常高效地只消费更改过的文件(例如在某个时间点提交了更改操作后,仅query某个时间点之前的数据,则仍可以query修改前的数据)。
如上图的左边,Hudi将数据集组织到与Hive表非常相似的基本路径下的目录结构中。数据集分为多个分区,每个分区均由相对于基本路径的分区路径唯一标识。
如上图的中间部分,Hudi以两种不同的存储格式存储所有摄取的数据:
3、DeltaLake
传统的lambda架构需要同时维护批处理和流处理两套系统,资源消耗大,维护复杂。基于Hive的数仓或者传统的文件存储格式(比如parquet/ORC),都存在一些难以解决的问题:
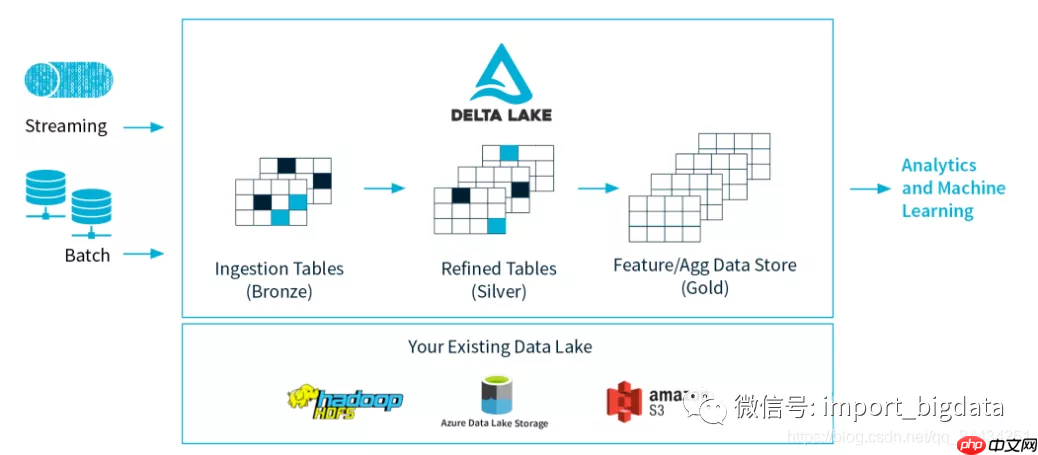
如上图,Delta Lake是Spark计算框架和存储系统之间带有Schema信息的存储中间层。它有一些重要的特性:
Delta Lake是基于Parquet的存储层,所有的数据都是使用Parquet来存储,能够利用parquet原生高效的压缩和编码方案。
Delta Lake在多并发写入之间提供ACID事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake会抛出并发修改异常以便用户能够处理它们并重试其作业。
Delta Lake其实只是一个Lib库,不是一个service,不需要单独部署,而是直接依附于计算引擎的,但目前只支持Spark引擎,使用过程中和parquet唯一的区别是把format parquet换成delta即可,可谓是部署和使用成本极低。
4、数据湖技术比较

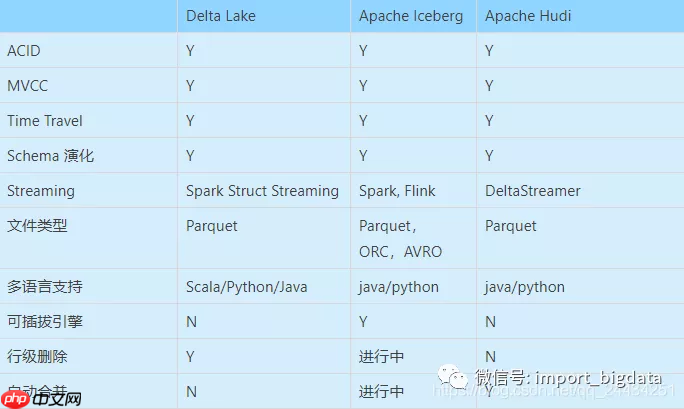
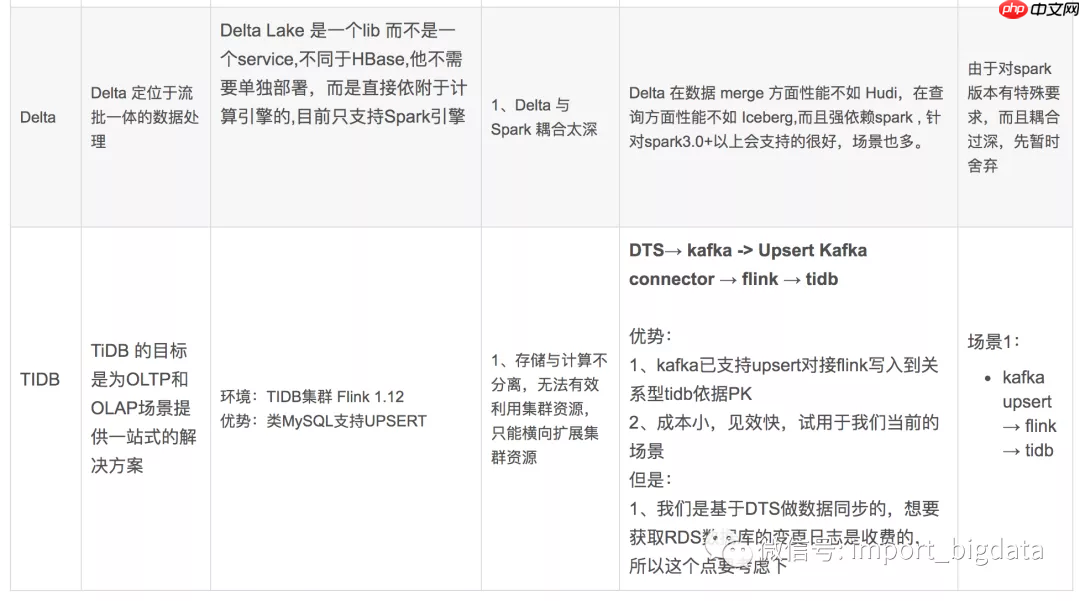
总结

以上就是实时方案之数据湖探究调研笔记的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 333
333






















