
大语言模型智能体的强化学习框架, 首次实现了通用的多智能体的“群体强化”。
在大语言模型(LLM)智能体的各种任务中,已有大量研究表明在各领域下的多智能体工作流在未经训练的情况下就能相对单智能体有显著提升。
但是现有的LLM智能体训练框架都是针对单智能体的,多智能体的“群体强化”仍是一个亟须解决的问题。
为了解决这一领域的研究痛点,来自UCSD和英特尔的研究人员,提出了新的提出通用化多智能体强化学习框架——PettingLLMs。支持任意组合的多个LLM一起训练。
大语言模型驱动的多智能体系统在医疗、编程、科研、具身智能等多个领域均能大幅度提升任务表现。
为训练大模型智能体,Group Relative Policy Optimization (GRPO) 已被验证为通用的有效强化学习算法。然而,当前所有针对LLM的强化学习训练框架,包括GRPO算法本身,都局限于单智能体训练的范畴。多智能体间的协作优化,即“群体强化”的学习机制,仍然是一个亟待填补的空白。
GRPO算法的核心机制是,针对同一个输入(prompt),通过多次采样生成一组候选回答。随后,算法在组内对这些回答进行评估(例如,通过一个奖励模型),并计算它们之间的相对优势。
这种优势计算的有效性与公平性依赖于一个关键假设——组内所有用于比较的候选回答,都必须基于一个完全相同的上下文(即prompt)生成。
然而,将GRPO直接应用于多智能体(multi-agent)多轮(multi-turn)环境中存在一个核心困难。
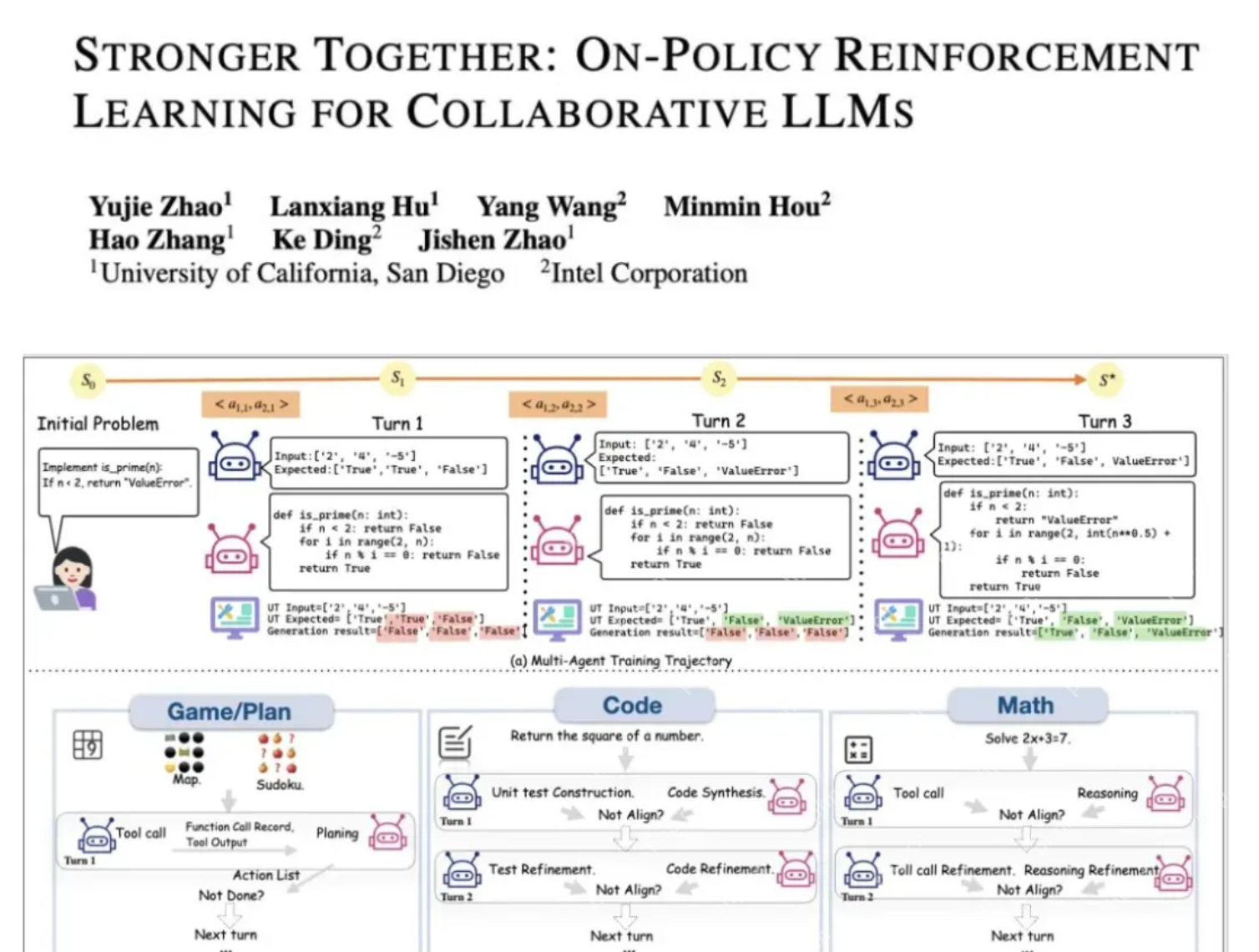
在多智能体场景下,即使是针对同一个初始问题,不同智能体在不同轮次接收到的prompt差异显著。
例如(如图所示),一个负责编程的智能体,其在第二轮的prompt不仅包含原始问题,还可能融合了第一轮中自己生成的代码以及其他智能体生成的单元测试。
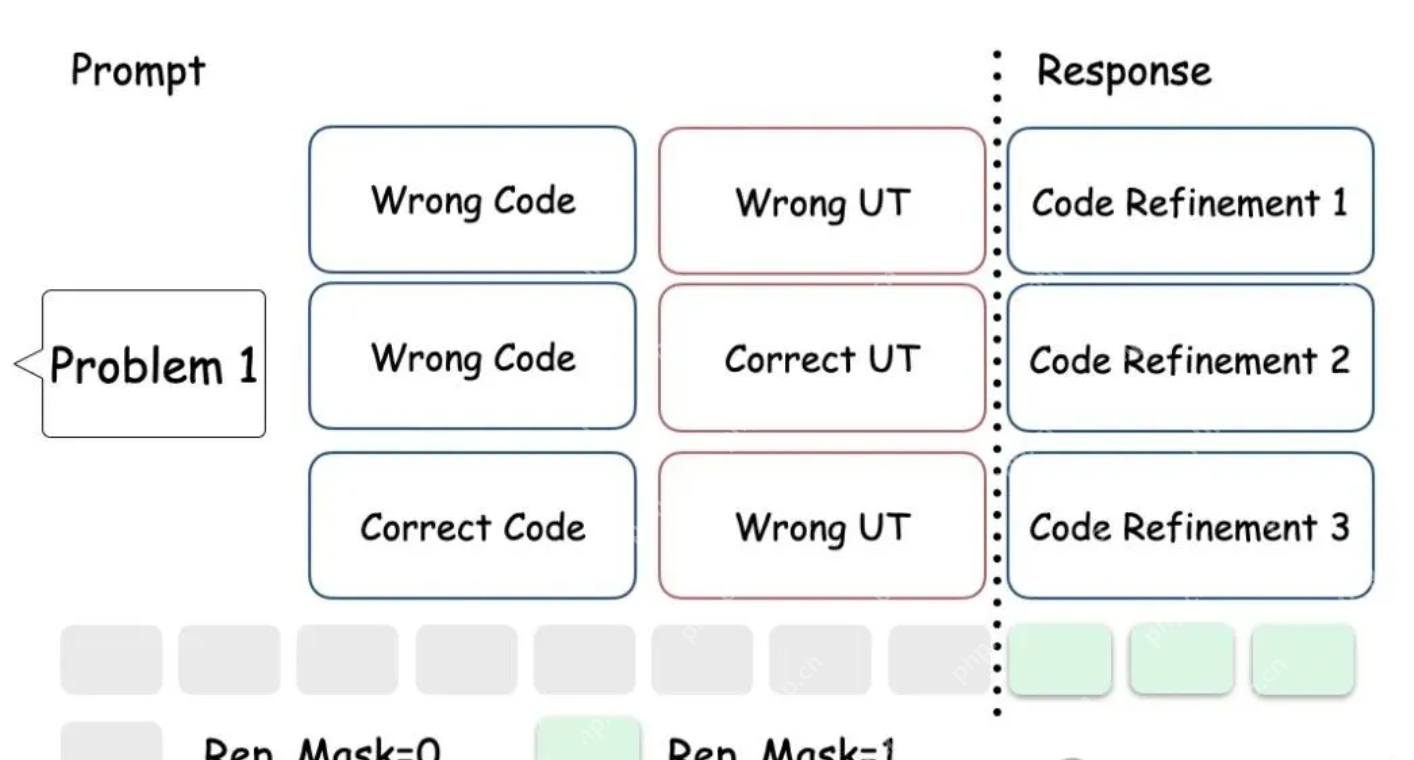
因此,如果在MA环境中仍然简单地将同一个初始问题产生的所有(跨轮次、跨智能体的)回答视为一个“group”来进行优势计算,这就直接违反了GRPO所要求的“共同prompt”的核心假设。
这导致组内的优势计算基准不统一,使得计算结果不再公平或有效。
所以核心问题就是,如何既保证每个组内有一定批次量的回答,又能保证优势计算的公平。

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 750
750



















