
deepseek依旧保持了不让程序猿们安心过长假的优良传统,在十一长假之前推出了deepseek-v3.2报告,之前一直在跟进deepseek的加速技术,第一时间看了报告,不长就6页纸,优化点也不多,本来想第一时间更新,不过还是让技术和鹅厂月饼一起消化发酵一下再来写吧,所以这篇还是在长假后和同学们见面了。
关注PHP中文网开发者,一手技术干货提前解锁?
10/23晚7:30鹅厂面对面直播继续!
从DeepSeek-V3说起
之前写过一篇比较长的关于DeepSeek-V3的加速分析,从模型结构到工程提速都有介绍DeepSeek-V3的加速技术,这里在文章开始之前先简单总结一下 V3 的技术亮点。
1.1 MOE:DeepSeekMoE
这个是在V2的论文里面就提出来的概念,叫做DeepSeekMoE: Training Strong Models at Economical Costs。怎么看都是一篇独立的论文,确实也是一篇独立的论文:只不过那会儿主打的副标题是:Ultimate Expert Specialization https://arxiv.org/abs/2401.06066 。这个Ultimate确实嚣张了一些。主要贡献就是:DeepSeek除了根据token选择的routed专家,还有一直工作的shared专家,这样Expert Specialization这个分工难题就很好的被解决了!应该是从无数次训练失败总结出来的经验,大模型现阶段很多方法都是没有理论的,好用就是好用。
在V3里面又对DeepSeekMoE进行了优化,加入了Auxiliary Loss Free Load Balancing(无辅助损耗负载平衡),来优化了原来的Expert-Level Balance Loss(专家级平衡损失),以及Device-Level Balance Loss(设备级平衡损失)。就是说可以进一步避免Expert Specialization偏坠导致的问题,算法简单粗暴,后面会展开说说。
1.2 MLA:Multi-Head Lantent Attention
这个技术也是V2时就用上了,V3报告里面又说了一回,简单来说就是把Multi-Head Attention(MHA)中的Q、K、V都给压缩了,压缩方式有些类似于LoRA(这里用大模型中出名的LoRA做类比了,其实提到Lantent,老NLP人最容易想到的应该是LDA中表示doc的方法)。先用一个矩阵乘法把输入ht给压缩到低纬度--ckv向量,之后K、V的值也是通过升维矩阵和这个ckv来计算出来,所以缓存的时候就不需要存储K和V了,只需要存储一个(每个时刻t就只存一个)维度很低的ckv就行了。这样就不会频繁的去内存交换那些KV了,可以在显存里面放更多的ckv了。至于那几个用来升维和降维的矩阵,那些算是模型参数,所以会随着模型参数的存取一起搞定。
那这样压缩、解压缩,多了很多计算量,再加上解压也不是无损的,那训练精度岂不要玩完。DeepSeek表示矩阵乘法计算起来比内存和显存之间存取节省更多的时间,有人说是 1:100的节省。至于精度问题,DeepSeek表示完全没有,后面用FP8都没遇到。而且因为这几个压缩矩阵参数量少,导致梯度变得集中,反而更容易收敛了,真的是绝活。
1.3 MTP:Multi-Token Prediction
这个技术V3中才引进过来,但结果是V3推理直接比V2提速一倍,那既然1和2在V2中就用了,那这个翻倍应该和后面的关系大一些。传统GPT都是每次输出一个token,而MTP就和名字一样,每次预测多个Token,原文中https://arxiv.org/abs/2404.19737 是建议一次预测4个,我看V3报告中示例图也是4个,但最后为了准确每次只输出2个,后面会详解。
MTP技术区别于之前的Look ahead,因为MTP训练的时候就要一次预测4个token,然后这4个token的loss都参与训练,而不是只在预测推理的时候投机。MTP训练时候步长还是1的滑动窗口,只是改了最后目标那一层。但是预测时候可以直接出4个,而且比各种ahead技术效果要好,因为这个是训练时候就进行了优化。
1.4 FP8:Mixed precision framework with FP8 data format
再来看FP8混合精度训练,BF16混合精度大家应该都了解了,这里把部分BF16精度降低到FP8了。DeepSeek在huggingface上开源的也是FP8精度模型,这点大家不需要担心了,不会比BF16的差多少,因为训练时候输入真的就是FP8精度的,模型Weight也是FP8的,但是中间结果还是要用BF16,梯度和优化器还是用的FP32。这么看来配合123技术,貌似FP8的精度确实不那么容易崩盘了,毕竟输入时候精度就被砍了,可能误差累积也就弱了。

V3.2 这篇需要先了解之前MLA(Multi-Head Lantent Attention)的一些基础知识,同时加入了一个 selected attention for important token机制,继而推出了一个叫做DSA(DeepSeek Sparse Attention)的东西。
另外这次DeepSeek-V3.2是深度的推理速度优化!对的,推理速度优化!并不提升训练速度和模型效果,是深度的推理速度优化!接近无损的优化!重要的话多说几遍。
DeepSeek的Sparse Attention概念
因为消化发酵了一下,所以先回顾一下历史,V3.2并不是DeepSeek第一次提出Sparse Attention的概念。早在今年元宵节后DeepSeek就提出了Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention的概念,估计写报告的不像R1那样不想让大家不能好好过年,所以报告晚了半个多月。论文里给了三种parallel attention branches,这里突出下原文是并行的意思,然后最后用一个Gated Output 门来控制这三个分支Attention结果的组合,请结合下图享用。
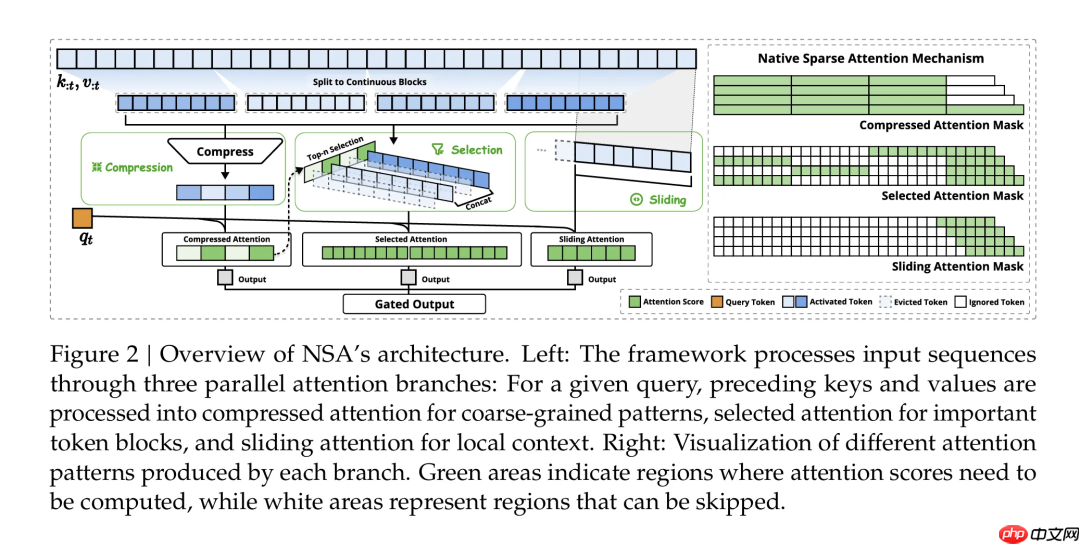
来简单说一下这三种Attention技术:
最左侧是compressed attention,这个就是V3和R1等采用的第一并行分支-MLA(Multi-Head Lantent Attention),简单来说就是将t时刻的输入ht去乘以一个矩阵得来储存全部t时刻压缩后的Key,Value的信息,需要真实的KV时再乘以矩阵和就得到的原始值。这些W矩阵都是训练得到来的,也对应这篇文章所说的Natively Trainable Sparse Attention的意思。想仔细了解的小伙伴可以看我之前的KM介绍 DeepSeek-V3的加速技术接下来是第二并行分支selected attention for important token blocks, MLA加上这个selected后,就是这次V3.2提出的DSA(DeepSeek Sparse Attention),估计加入第三并行分支后应该还是这个名字。selected这个意思也很简单,就是选择一些important的token来计算attention。所以这篇后面也会主要介绍如何select important token。第三并行分支,sliding attention for local context,这种窗口范围的attention早在23年的LONGNET 中就有类似的思想,今年也有专门就叫做SWA(Sliding Window Attention Training for Efficient Large Language Models)等类似论文。DeepSeek这里也是使用了Sliding Window来实现。目前还没有应用的开源模型出来,估计后续会见到类似的模型出来。但是V3.2并非是第一分支和第二分支的并行,而是第一分支和第二分支的一种组合。因为实际上如果采用两个并行,那么速度肯定会卡在最慢的那个,目前从V3.2的论文来看,速度肯定会卡在标准多头注意力机制(MHA)版本的MLA上面,即V3的版本速度,所以这里也是放弃了并行,而是做了第一和第二的组合。至于第三分支的SWA如何加入进来,那就要等DeepSeek的后续版本了,希望不要过年的时候大家赶工。
V3.2的DSA详解
从上面我们讲解中提到了,V3.2的DAS就是V3的第一分支MLA加上第二分支selected attention for important token blocks,为了加速和适配,这里MLA从标准的MHA(Multi-Head Attention)替换为了MQA(Multi-Query Attention)
3.1 MHA版MLA VS MQA版MLA
先来看一张V3时提出MLA的老图,因为MQA所有的Attention共享一组Key和Value,所以之前DeepSeek被诟病会丢掉很多Key和Value的信息。
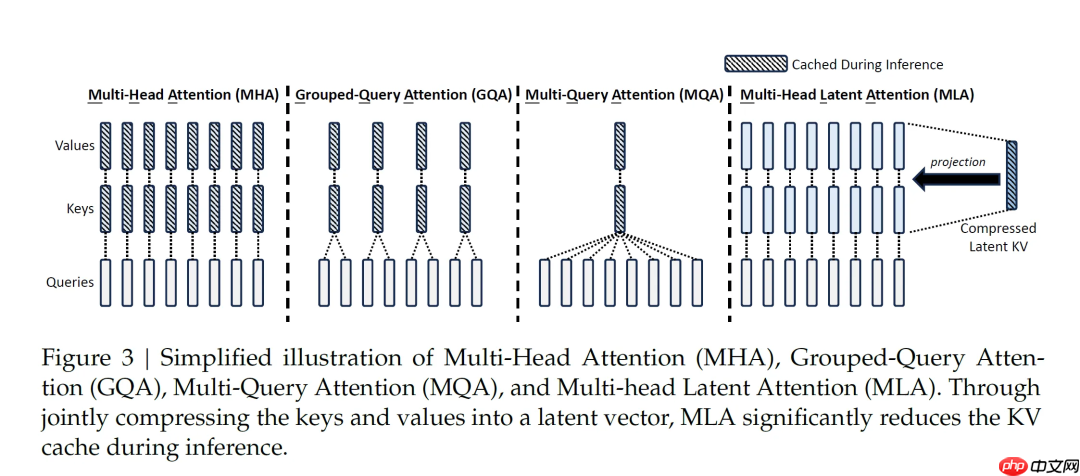
但实际上MLA的压缩也是全Attention共享一组

,不过计算时候要还原出全部的Key和Value,当时也讲了,是用GPU的计算量来换RAM显存的I/O时间,因为计算比I/O快很多。
这次V3.2终于也对KV动刀了,所以这里不再是靠压缩和解压版的全MHA,而是成为MQA了版本的MLA。如下图所示,这里理解起来并不难易,就是不先用
还原出KV,而是先用中间结果计算出Attention,在最后再还原出Value,节省了不少计算量,但操作更接近MQA了,所以起了MQA版MLA这个名字。

以上就是DeepSeek-V3.2加速技术详解,效果惊人的秘密?的详细内容,更多请关注php中文网其它相关文章!

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号









 617
617





















