
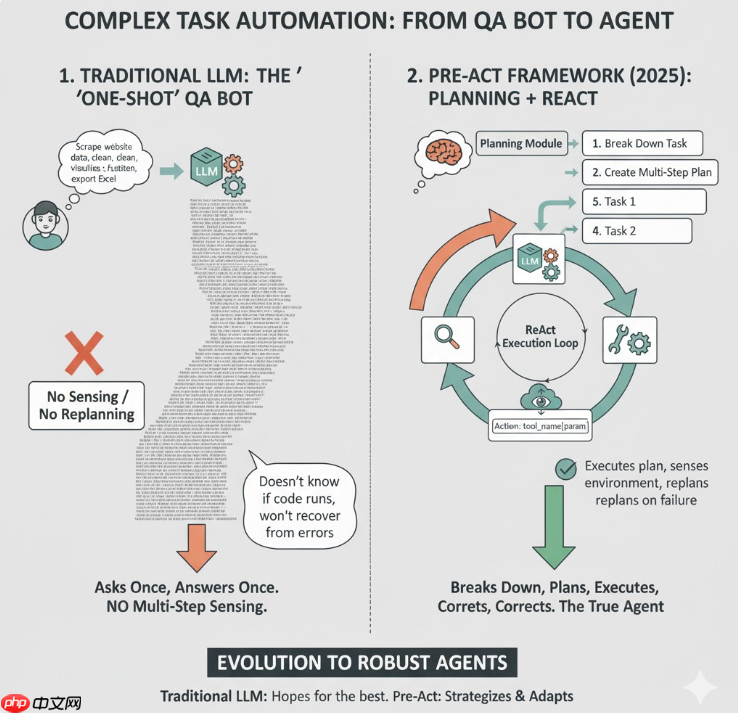
在专题《react》我们提到过,原生的react目光比较短浅,做出的决策是 “想一点 → 做一步”,而在我们的科研、工作中,往往还需要应对长远规划、多阶段子任务的场景。例如
如果我们仍然用传统 LLM 的思路:
那它本质上还是一个“一问一答”的 QA Bot,只是回答变长了而已, 中间过程无法感知执行是否成功(代码跑没跑通、网页抓没抓到);不会根据中途失败重规划(比如某个 API 不存在、权限不足);
这和我们心目中“能真正完成任务的 Agent”还差着一整层抽象:
因此,Pre-Act 提出ReAct通常是“即时思考 + 即时动作”,对复杂任务效果有限,提出了“先做多步规划,再结合 ReAct 执行”的框架,也就是 Planning (规划)。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
先回顾一下我们在 ReAct 章节里出现过的 Chain-of-Thought(CoT):
<code class="python">Q: 2 + 3 * 4 = ?A:Step 1: 先算乘法 3*4 = 12Step 2: 再算加法 2 + 12 = 14所以答案是 14</code>
CoT 做的事情是:在一次回答过充中,把推理过程展开成一条“思路链”。尽管它能够激活大模型的推理能力,但是他依然存在着两个限制:
? 推理过程只能在单词问答中起作用,无法适用于跨多轮、跨任务
? 没有执行的概念,只是把推理写成文字。
Planning 不只是“在脑子里过一遍”,而是把顺序写成一个“可执行的任务表”,并把这些步骤交给下游 Agent 逐步执行
如果再“工程化”一点,可以让 LLM 直接输出结构化 Plan,比如 JSON:
<code class="JSON">[ { "step": 1, "description": "收集 RAG 基础定义与优缺点", "need_retrieval": true }, { "step": 2, "description": "整理 RAG 全流程说明和流程图", "need_retrieval": false }, { "step": 3, "description": "实现一个基于 PDF + FAISS 的 RAG 示例代码", "need_retrieval": false }, { "step": 4, "description": "撰写前言、总结,并补充延伸阅读", "need_retrieval": true }]</code>这类范式不需要重新训练模型,也属于一种高级的prompting的技术,可以分为三类范式:Plan-Then-Act、ReAct + 轻规划、Tree / Graph Planning。这类范式的共同本质还是在“怎么 prompt 这个 LLM 去规划”。
① Plan-Then-Act:
典型交互可以长这样:
<code class="python">User: 帮我写一篇 RAG 入门博客,最后给一个 Python+FAISS 的 Demo。LLM(Planner 输出):1. 解释什么是 RAG 以及解决什么问题2. 画出一个典型 RAG 流程(构建知识库→检索→过滤→压缩→拼 prompt)3. 给出一个基于 pdfplumber + SentenceTransformer + FAISS 的代码示例4. 写一个总结和延伸阅读</code>

② ReAct + 轻规划
按照经典的ReAct范式 Thought → Action → Observation 循环,直接把每一个 Thought 理解成局部的小 Plan,例如:
其实这本身也是一种 Planning,只不过是局部、小步、滚动式的规划:

③ Tree / Graph Planning
再往前一步,可以让 Agent 不只输出一条线性的 Plan,而是针对一个问题,生成多个候选思路 / 子计划,并且在这些思路上进行树搜索 / 图搜索,选择最优路径。典型代表包括:
Tree-of-Thoughts(ToT):多条思路作为树节点,逐步扩展与回溯;LATS / 类 MCTS 搜索:把 LLM 当作“策略 + 评估函数”,在搜索树上走多步。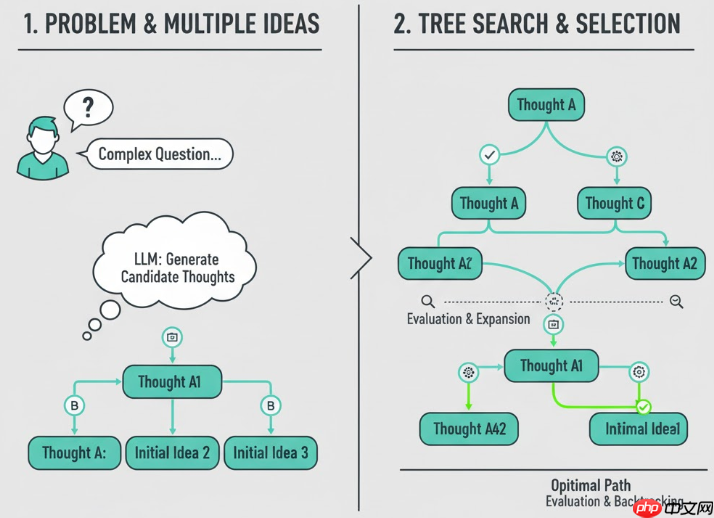
首先将代码实现拆成两个步骤:

享有盛誉的PHP高级教程,Zend Framework核心开发人员力作,深入设计模式、PHP标准库和JSON 。 今天,PHP已经是无可争议的Web开发主流语言。PHP 5以后,它的面向对象特性也足以与Java和C#相抗衡。然而,讲述PHP高级特性的资料一直缺乏,大大影响了PHP语言的深入应用。 本书填补了这一空白。它专门针对有一定经验的PHP程序员,详细讲解了对他们最为重要的主题
 455
455

plan_task:让 LLM 输出结构化 Plan(JSON);execute_plan:按步骤执行 Plan,每步可以接 RAG / Memory / 甚至 ReAct。plan_task代码实现<code class="PYTHON">import jsondef plan_task(user_goal: str, llm) -> list: """ 调用 LLM,把复杂目标拆成 3~7 步的结构化计划。 """ prompt = f""" 你是一个任务规划助手。现在有一个复杂目标,请你把它拆分成 3~7 个有序子任务。 要求: 1. 每个子任务尽量原子化,可以独立完成。 2. 标明该步是否需要调用外部知识库(RAG)(例如需要查 PDF / 文档 / 网页)。 3. 只输出 JSON 数组,不要多余解释。 JSON 元素字段: - "step": 整数,从 1 开始 - "description": 这一步要做什么 - "need_retrieval": true 或 false 用户目标:{user_goal} """ # 假设 llm(prompt) 直接返回一个字符串形式的 JSON resp = llm(prompt) plan = json.loads(resp) return plan</code>execute_plan 代码实现<code class="PYTHON">def execute_plan(plan: list, llm, retriever=None, memory=None): """ 逐步执行规划好的子任务。 retriever: 检索函数,例如 RAG 的 retrieve_docs(desc) -> [doc1, doc2, ...] memory: 一个简单的 Memory 对象,支持 get_recent() / write(...) """ for step in plan: desc = step["description"] need_ret = step.get("need_retrieval", False) # 1️⃣ 按需要触发 RAG 检索 context = "" if need_ret and retriever is not None: docs = retriever(desc) # 简单拼一下,也可以在这里先做摘要 context = "</p><p>".join(docs) # 2️⃣ 从 Memory 里拿最近若干条历史记录(可选) history = "" if memory is not None: history = memory.get_recent() # 3️⃣ 让 LLM 专注完成“当前这一步” sub_prompt = f""" 你正在执行一个多步任务中的第 {step["step"]} 步。 当前子任务描述: {desc} 可用资料(可能为空): {context or "【无外部资料】"} 历史记录(可能为空): {history or "【无历史记录】"} 请只完成当前这一步,不要提前执行后续步骤。 """ sub_answer = llm(sub_prompt) print(f"[Step {step['step']}] 子任务说明:{desc}") print(f"[Step {step['step']}] 输出:{sub_answer}") # 4️⃣ 把结果写入 Memory(如果有的话) if memory is not None: memory.write( role="assistant", content=f"[Step {step['step']}] {sub_answer}" )</code><code class="python">from langchain_openai import ChatOpenAIfrom langchain_community.tools import DuckDuckGoSearchRunfrom langchain_experimental.plan_and_execute import ( PlanAndExecute, load_chat_planner, load_agent_executor,)llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)tools = [DuckDuckGoSearchRun()]planner = load_chat_planner(llm) executor = load_agent_executor(llm, tools, verbose=True)agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)res = agent.invoke({"input": "帮我调研三篇关于 RAG+RL 的论文并输出一个中文总结"})print(res["output"])</code>在工程习惯里,80% 的场景用 ReAct + 小步规划 就足够了。在 LangChain 中并没有一个单独叫做 “Planning 模块” 的东西——ReAct Agent 自己就是一种“把 planning 揉进每一次 Thought”的滚动式小步规划。所以这里的实现可以直接复用 LangChain 的 ReAct Agent 代码:
<code class="python">from langchain_openai import ChatOpenAIfrom langchain.agents import AgentExecutor, create_react_agentfrom langchain import hubfrom langchain_community.tools import DuckDuckGoSearchRunfrom langchain_core.tools import tool# 1. LLMllm = ChatOpenAI(model="gpt-4o-mini", temperature=0)# 2. 定义工具search = DuckDuckGoSearchRun()@tooldef calculator(expr: str) -> str: """计算一个数学表达式,例如 '1+2*3'。""" import math try: return str(eval(expr)) except Exception as e: return f"error: {e}"tools = [search, calculator]# 3. 用官方 hub 上的 ReAct prompt 模板prompt = hub.pull("hwchase17/react") # 4. 创建 ReAct Agent(底层是一个 Runnable 序列)agent = create_react_agent(llm, tools, prompt)# 5. 外面再包一层 AgentExecutor,负责 loopagent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)result = agent_executor.invoke({"input": "帮我查一下北京今天天气,再算一下 1+2*3"})print(result["output"])</code>? 回答思路: 我一般会把这个问题拆成三层:别让它乱想 → 想完先审一遍 → 真执行时还能纠错。
1)先“缩小想象空间”:不要给它机会乱编世界
显式给 Planner 一份“世界说明书”: 在 prompt 里列清楚:可用的工具 / API 名单(名字 + 功能)能访问到的数据源 / 文件禁止的行为(删库、写线上、访问外网等等)用结构化字段把它“锁死”,比如要求输出:
这样它就没法随手来一句 "tool": "call_magic_api"。
2)Planner 说完不算数:先过一遍“Plan 校验器”
Planner 输出的是 JSON,不是散文,这就很好做事了:
Schema 校验:字段是不是全了?类型对不对?tool / action_type 是否在允许集合里?step 是否是 1,2,3... 递增?规则校验(跟业务绑),比如:调“写库”之前,plan 里必须出现过“备份 / 权限检查”这类步骤;某些高危工具只允许出现在最后 N 步。简单伪代码可以这么说(面试不用真写):
<code class="python">def validate_plan(plan): for step in plan: if step["tool"] not in ALLOWED_TOOLS: return False, f"非法工具: {step['tool']}" return True, ""</code>这个问题其实就是在问你: “怎么控制 step 粒度,让 plan 既好执行,又不啰嗦。”
我一般会先说明:我看两个指标:
步数:是不是一上来就 20、30 步;单步复杂度:这一行是不是抽象到根本没法直接执行。然后分别讲“太碎”和“太粗”。
症状:
Planner 把任务拆成 20+ 步,每一步就是“调用一下这个 API / 打一次日志”,
结果:
执行很慢,工具调用次数爆炸;整个 orchestration 变得非常啰嗦。我的处理方式:让 Planner 只做“人类级别的大纲”,微观步骤交给 ReAct。? 做法 1:在 Prompt 上限步数 + 定义“合适粒度”在 Planner 的 prompt 里直接写:也可以给反例:❌ “第 1 步:打印日志;第 2 步:调用接口 A;第 3 步:打印日志;……”✅ “第 1 步:从系统 A 拉取原始数据并记录关键日志。”症状:
一个 step 写:“完成所有实验并写完论文结论”,Executor 完全不知道从哪一步开始。我的做法:让 Planner 对“单步可执行”负责,必要时再做二级拆解。
写 prompt 的时候直接告诉它:
<code class="python">每一步需要做到:- 单步是可执行的:一个子 Agent 可以在若干次工具调用内完成。- 避免过于抽象的表达,如“完成所有实验并写完论文”。</code>
给个对比例子:
❌ “完成 RAG 系统的所有实现和测试”✅ “基于现有 PDF 文档构建向量索引,并保存到本地目录 X”。本章主要介绍了PLANNING的基本概念、基本范式、代码实现以及常见面经。基本范式主要介绍了静态类型的范式,本质上还是属于高级的prompting,当我们学习完智能体的全部功能后,会将rag、react、memory、planning等逐步升级为真正的agentic RL。除此之外,目前的代码还是基于langchain实现的,为了能够紧跟前沿技术,在学习完所有功能后还会统一的学习langgraph的实现。
以上就是【Agentic专题】 Planning专题学习与面经的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号





 922
922























