
在只有基础对话能力的阶段,大模型更多像一个“一次性回答机”:
User: 问题 LLM : 一次性生成答案
即便我们加上了 Memory、RAG,智能体也只是多了“能记”和“会查”:
Memory:记住过去发生了什么(多轮对话、历史任务状态) RAG:在回答前去查一查知识库或互联网但这仍然是“问一答一”的模式,缺少真正的多步决策与行动能力。
ReAct(Reasoning + Acting) 正是为了解决这个问题提出的:
在推理过程中,显式地交替输出“思考内容(Thought)”和“行动指令(Action)”,再利用环境反馈(Observation)更新后续推理。
原论文《ReAct: Synergizing Reasoning and Acting in Language Models》采用的典型轨迹格式如下:
<code class="python">Question: (用户问题)Thought 1: 我需要先查一下 X 的相关背景。Action 1: search["X 的维基百科页面"]Observation 1: (搜索工具返回的摘要文本)Thought 2: 现在我知道了 X 的定义,还需要确认 Y。Action 2: lookup["Y 相关条目"]Observation 2: (查具体条目返回的信息)Thought 3: 根据 Observation 1 和 2,可以得出结论……Final Answer: (给用户的最终回答)</code>
可以发现,在思考的过程中的关键元素如表所示:
元素 |
是否改变环境 |
主要作用 |
示例 |
|---|---|---|---|
Thought |
❌ 不改变环境 |
作为“内心独白”,用于规划下一步、整理当前已知信息、解释为什么要调用某个工具 |
“我需要先查一下 2024 年奥运会的举办城市。” |
Action |
✅ 通过调用工具/环境间接改变环境 |
发出结构化“命令”,触发具体操作(检索、查表、移动等) |
|
Observation |
✅ 环境产生的结果 |
记录环境或工具对 Action 的反馈,为下一步 Thought 提供依据 |
搜索结果文本、API 返回的 JSON、环境状态描述 |
Final Answer |
❌ 自身不再行动(但对用户是最终输出) |
标志推理/行动序列结束,给出最终对用户的回答 |
|
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
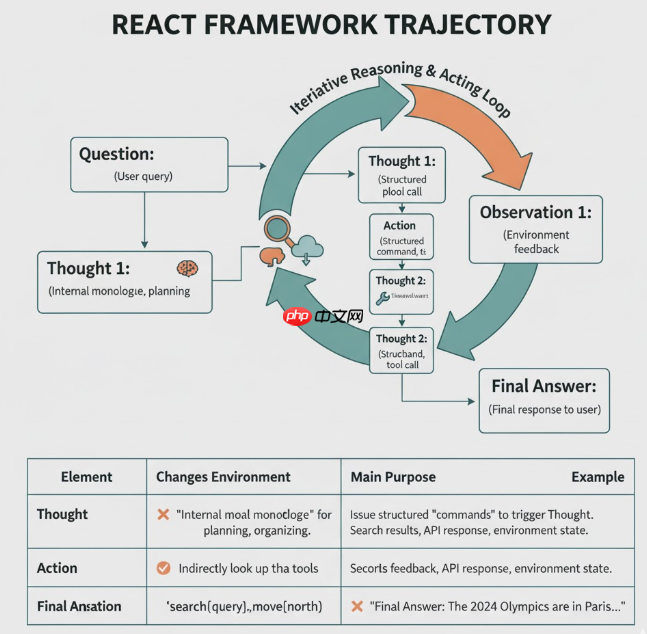
LLM 的工作就变成了:
先来看一下CoT(Chain-of-Thought) 的流程形式:
Q: 2 + 3 * 4 = ?
A:
Step 1: 先算乘法 3*4 = 12
Step 2: 再算加法 2 + 12 = 14
所以答案是 14
链式思考的出现大大提升了大模型的数学推理能力,他并不是重新训练大模型来得到这种能力的,而是通过prompting来挖掘大模型本就有的推理能力。
在CoT的基础上,ReAct 的核心变化就是:在 “思考链(Thought)” 中间插入 “动作(Action)” 和 “环境反馈(Observation)”, 然后多轮循环。具体流程如下:
step 1. 在 Prompt 里定义协议
你是一个可以一边思考一边操作工具的助手。
你必须严格按下面格式输出(非常重要):
Question: {用户问题}
Thought: ...
Action: 工具名"参数"
Observation: ...
...
当你已经可以回答用户问题时,输出:
Final Answer: ...
step 2. 循环控制伪代码
<code class="python">while True: llm_output = call_llm(prompt) if "Final Answer:" in llm_output: 提取最终答案,结束 action = parse_action(llm_output) # 找 Action: xxx["..."] obs = run_tool(action) # 真正调用工具 prompt += llm_output + f"Observation: {obs}"</code>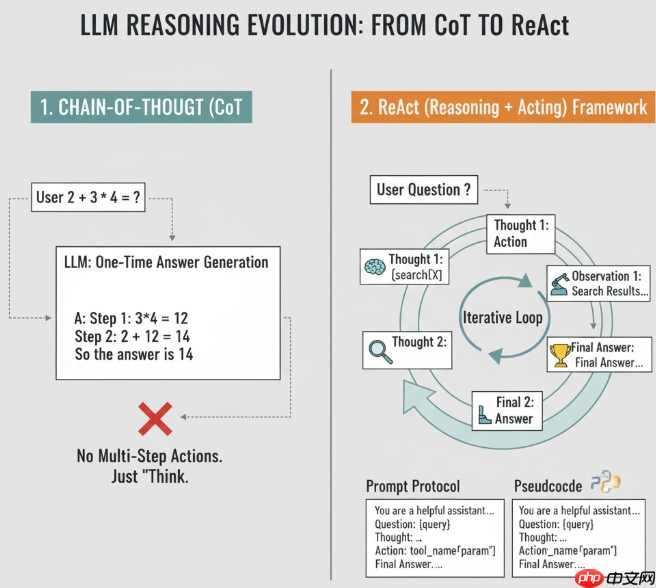
学到这里,我们可以说,ReAct其实本质就是一种更加“高级 prompting + 外层控制逻辑”
为了帮助读者更好的理解ReAct·,我们先手撕简化版 ReAct 循环(伪代码,逻辑关键):
step 0. 工具自定义
<code class="python">import refrom typing import Dict, Callable# 假设这是一个Chat LLM 接口def call_llm(prompt: str) -> str: passTOOLS: Dict[str, Callable[[str], str]] = {}def register_tool(name: str): def decorator(fn): TOOLS[name] = fn return fn return decorator@register_tool("calculator")def calculator(expr: str) -> str: """计算简单数学表达式""" try: return str(eval(expr)) except Exception as e: return f"计算错误: {e}"</code>step 1. 在 Prompt 里定义协议
<code class="python">REACT_SYSTEM_PROMPT = """你是一个可以一边思考一边使用工具的助手。交互格式如下:Thought: 先解释你在想什么Action: 工具名["参数"]Observation: 我会用工具返回的结果填在这里...最后当你可以回答用户问题时,请输出:Final Answer: 给出最终回答当前可用工具:- calculator: 计算数学表达式,格式如 calculator["1+2*3"]"""</code>
step 2. 循环控制
<code class="python">def react_loop(question: str, max_steps: int = 5): scratchpad = "" for step in range(1, max_steps + 1): prompt = ( REACT_SYSTEM_PROMPT + f"Question: {question}" + scratchpad + "请给出下一步 Thought / Action 或 Final Answer:" ) llm_output = call_llm(prompt) # 1. 先看是否已经给出 Final Answer if "Final Answer:" in llm_output: answer = llm_output.split("Final Answer:")[1].strip() print("✅ Final Answer:", answer) return answer # 2. 解析 Action action_match = re.search(r"Action:\s*(\w+)\[\"(.*)\"\]", llm_output) if action_match: tool_name, tool_input = action_match.groups() if tool_name not in TOOLS: observation = f"工具 {tool_name} 不存在。" else: observation = TOOLS[tool_name](tool_input) # 把这一步的 Thought / Action / Observation 追加到 scratchpad scratchpad += ( f"{llm_output.strip()}" f"Observation: {observation}" ) else: # 如果没解析出 Action,只把 Thought 拼进去,继续下一轮 scratchpad += f"{llm_output.strip()}" print("⚠️ 达到最大步数仍未得到 Final Answer") return None</code>LangChain 做的事情,本质上就是把这个“循环 + 解析 + 工具调用”封装成一个可复用的 LCEL 运行图,并提供不少内置工具和 Prompt 模板。
⚙️ 依赖安装(示例环境)
<code class="python">pip install -U langchain langchain-openai langchain-community duckduckgo-search`</code>
<code class="python"># 带搜索 + 计算器的 ReAct Agent 示例import osfrom langchain_openai import ChatOpenAIfrom langchain_community.tools import DuckDuckGoSearchRunfrom langchain_core.tools import tool# 远程调用,需要KEYos.environ["OPENAI_API_KEY"] = "你的 key"# 1️⃣ LLM:底层使用 Chat 接口(如 GPT-4 / DeepSeek 等)llm = ChatOpenAI( model="gpt-4o-mini", # 或者 deepseek/chat 等 temperature=0)# 本地定义llm#from langchain_community.chat_models import ChatOllama#llm = ChatOllama(# model="qwen2.5:7b-instruct", # 本地 ollama 已经拉好的模型# temperature=0#)# 2️⃣ 定义一个自定义工具:计算器@tooldef calculator(expression: str) -> str: """计算一个数学表达式,例如 '1+2*3'。""" #docstring try: return str(eval(expression)) except Exception as e: return f"计算出错: {e}"#内置的 DuckDuckGo 搜索工具,简单的网页搜索工具,无需keysearch = DuckDuckGoSearchRun()tools = [calculator, search]</code>@tool 装饰器会自动把 Python 函数包装成 LangChain 的 BaseTool 对象;
在第三章我们提过,需要在 Prompt 里定义协议;
而在LangChain Hub 中这些事已经不需要我们做了, 因为已经有现成的 ReAct Prompt(hwchase17/react)以直接拿来用:[
<code class="python">from langchain import hub# 从 LangChain Hub 拉取 ReAct Promptprompt = hub.pull("hwchase17/react")print(prompt.template[:400], "...")</code>你打印一下会看到类似结构(英文),明确告诉 LLM 要循环输出 Thought / Action / Observation,直到给出 Final Answer。
<code class="python">Answer the following questions as best you can. You have access to the following tools:{tools}Use the following format:Question: the input question you must answerThought: you should always think about what to doAction: the action to take, should be one of [{tool_names}]Action Input: the input to the actionObservation: the result of the action.. (this Thought/Action/Action Input/Observation can repeat N times)Thought: I now know the final answerFinal Answer: the final answer to the original input questionBegin!Question: {input}Thought:</code>create_react_agent 构建 Agent + ExecutorLangChain 提供了一个封装好的工厂函数:create_react_agent,专门用来构造 ReAct 风格的 Agent。
<code class="python">from langchain.agents import create_react_agent, AgentExecutor# 5️⃣ 构建 ReAct Agent(本质是一个 LCEL runnable)agent = create_react_agent( llm=llm, tools=tools, prompt=prompt,)# 6️⃣ 用 AgentExecutor 包一层循环执行逻辑agent_executor = AgentExecutor( agent=agent, tools=tools, verbose=True, # 打印中间 Thought / Action / Observation 轨迹 max_iterations=5, # 最多迭代 5 轮 handle_parsing_errors=True,)</code>
<code class="python">query = "请查一下 2024 年奥运会举办城市,然后算一下这个城市名称的长度平方是多少?"result = agent_executor.invoke({"input": query})print("? 最终回答:", result["output"])</code>在 verbose=True 的情况下,你会在控制台看到类似这样的轨迹(示意):
<code class="python">Thought: 我需要先查一下 2024 年奥运会的举办城市。Action: duckduckgo_searchAction Input: "2024 Summer Olympics host city"Observation: The 2024 Summer Olympics were held in Paris, France. ...Thought: 我知道了举办城市是 Paris。现在需要计算城市名称长度的平方。Action: calculatorAction Input: "len('Paris')**2"Observation: 25Thought: 我已经知道了最终答案。Final Answer: 2024 年奥运会举办城市是巴黎(Paris),城市名 "Paris" 的长度为 5,5 的平方为 25,因此答案是 25。</code>分析一下:
<code class="python">1. 第一步 Thought:说明“先查办奥运会城市”;2. 第一步 Action:调用 `duckduckgo_search`; 3. Observation 包含了搜索结果(告诉你是 Paris); 4. 第二步 Thought:决定用 calculator 计算长度平方; 5. 第二步 Action:调用 `calculator`; 6. Observation 给出 25; 7. 最后 Thought + Final Answer:给出解释 + 最终结论。</code>
可以发现,这个过程和我们上面手写的 ReAct loop 是一一对应的,只不过 LangChain 帮我们封装了细节。
在 ReAct 的基础循环上,再叠一层“学习自己的经验”的外环。比如 Reflexion 让 Agent 在失败后,用自然语言总结“刚才哪一步错了,下次应该怎么改”,再写入 Memory,下一轮参考。Reflexion: Language Agents with Verbal Reinforcement Learning
原生 ReAct 偏“短视”——每一步都是 “想一点 → 做一步”,对需要长远规划、多阶段子任务的场景不够强。比如 2025 的 Pre-Act 工作就直接点名:ReAct 通常是“即时思考 + 即时动作”,对复杂任务效果有限,于是提出“先做多步规划,再结合 ReAct 执行”的框架
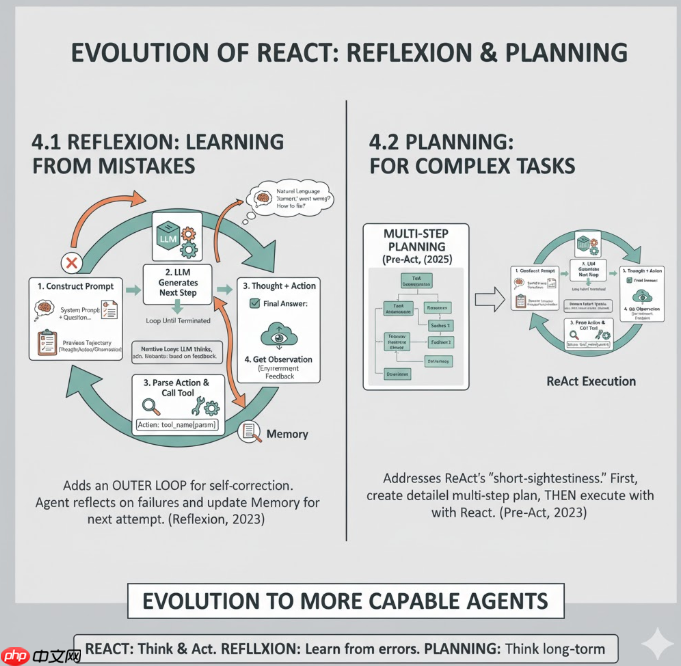
到这一章,我们已经让智能体具备了三种“能力模块”:
Memory 让它记住发生过什么,RAG 让它查询外部世界的知识,而 Planner 则让它从“一问一答”升级为“多步决策的任务执行者”。
但目前这一切,仍然是“静态策略”:
规划规则、检索策略、记忆使用方式,都是我们人为写在 prompt 里或硬编码在逻辑中的。 在未来的学习中,我们希望让这些策略自己学会变好,自然就得进一步引出 Agentic RL:
以上就是【Agentic RL 专题】深入浅出了解ReAct的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 685
685























