
大家好,又见面了,我是你们的朋友全栈君。
StreamingContext和SparkContext一样,是Spark Streaming应用程序连接Spark集群的入口。它的定义如下:
Java代码
/**
* Main entry point for Spark Streaming functionality. It provides methods used to create
* [[org.apache.spark.streaming.dstream.DStream]]s from various input sources. It can be either
* created by providing a Spark master URL and an appName, or from a org.apache.spark.SparkConf
* configuration (see core Spark documentation), or from an existing org.apache.spark.SparkContext.
* The associated SparkContext can be accessed using `context.sparkContext`. After
* creating and transforming DStreams, the streaming computation can be started and stopped
* using `context.start()` and `context.stop()`, respectively.
* `context.awaitTermination()` allows the current thread to wait for the termination
* of the context by `stop()` or by an exception.
*/
class StreamingContext private[streaming] (
sc_ : SparkContext,
cp_ : Checkpoint,
batchDur_ : Duration
) extends Logging {从类的文档注释中,我们可以看到:
batchDur_是一个Duration类型的对象,例如Seconds(10),这个参数的含义是流数据被分成批次的时间间隔。假设batchDur_为Seconds(10),表示Spark Streaming会将每10秒钟的数据作为一个批次,而一个批次对应一个RDD。没错,一个RDD的数据对应一个batchInterval累加读取到的数据。DStream的Java代码如下:
/** * A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous * sequence of RDDs (of the same type) representing a continuous stream of data (see * org.apache.spark.rdd.RDD in the Spark core documentation for more details on RDDs). * DStreams can either be created from live data (such as, data from TCP sockets, Kafka, Flume, * etc.) using a [[org.apache.spark.streaming.StreamingContext]] or it can be generated by * transforming existing DStreams using operations such as `map`, * `window` and `reduceByKeyAndWindow`. While a Spark Streaming program is running, each DStream * periodically generates a RDD, either from live data or by transforming the RDD generated by a * parent DStream. * * This class contains the basic operations available on all DStreams, such as `map`, `filter` and * `window`. In addition, [[org.apache.spark.streaming.dstream.PairDStreamFunctions]] contains * operations available only on DStreams of key-value pairs, such as `groupByKeyAndWindow` and * `join`. These operations are automatically available on any DStream of pairs * (e.g., DStream[(Int, Int)] through implicit conversions when * `org.apache.spark.streaming.StreamingContext._` is imported. * * DStreams internally is characterized by a few basic properties: * – A list of other DStreams that the DStream depends on * – A time interval at which the DStream generates an RDD * – A function that is used to generate an RDD after each time interval */
从文档中,我们可以得出以下几点:
map操作,会转换成另一个DStream。batchInterval)间隔切片,每个batchInterval都会构造一个RDD。因此,Spark Streaming实质上是根据batchInterval切分出来的RDD串,想象成糖葫芦,每个山楂就是一个batchInterval形成的RDD。window或reduceByKeyAndWindow操作,也会转换成另一个DStream(window操作是状态化的DStream变换)。map, filter, window等操作,同时,对于元素类型为(K,V)的pair DStream,Spark Streaming提供了一个隐式转换的类,PairStreamFunctions。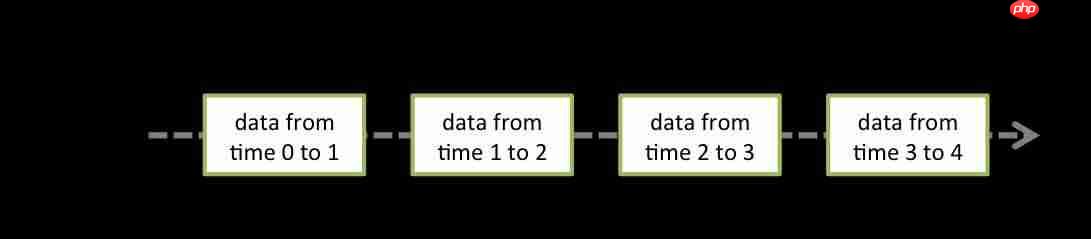
在DStream内部,DStream表现为一系列的RDD序列,针对DStream的操作(比如map,filter)会转换到它底层的RDD的操作。从图中可以看出,0-1这段时间的数据累积构成了RDD@time1,1-2这段时间的数据累积构成了RDD@time2,依此类推。也就是说,在Spark Streaming中,DStream中的每个RDD的数据是一个时间窗口的累计。
下图展示了对DStream实施转换算子flatMap操作。需要指出的是,RDD的转换操作是由Spark Engine来实现的,原因是Spark Engine接受了原始的RDD以及作用于RDD上的算子,在计算结果时才真正对RDD实施算子操作。
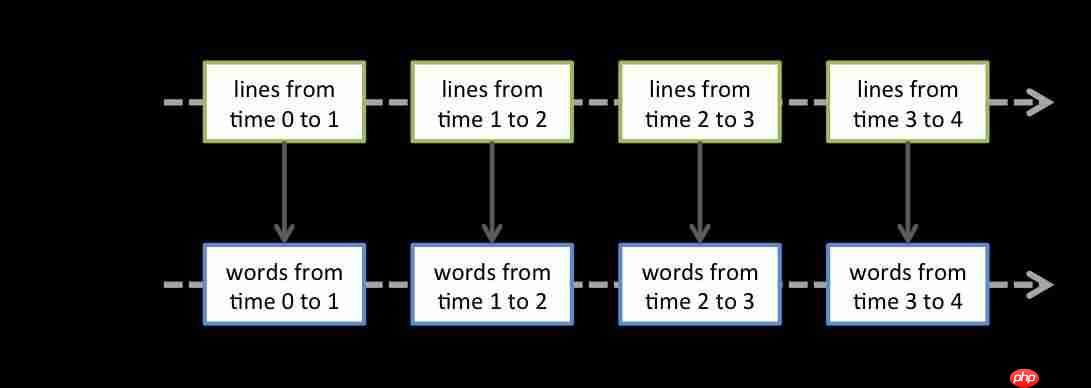
按照下图所呈现的含义,Spark Streaming用于将输入的数据分解成一个一个的RDD,每个RDD交由Spark Engine进行处理以得到最终的处理数据。是的!
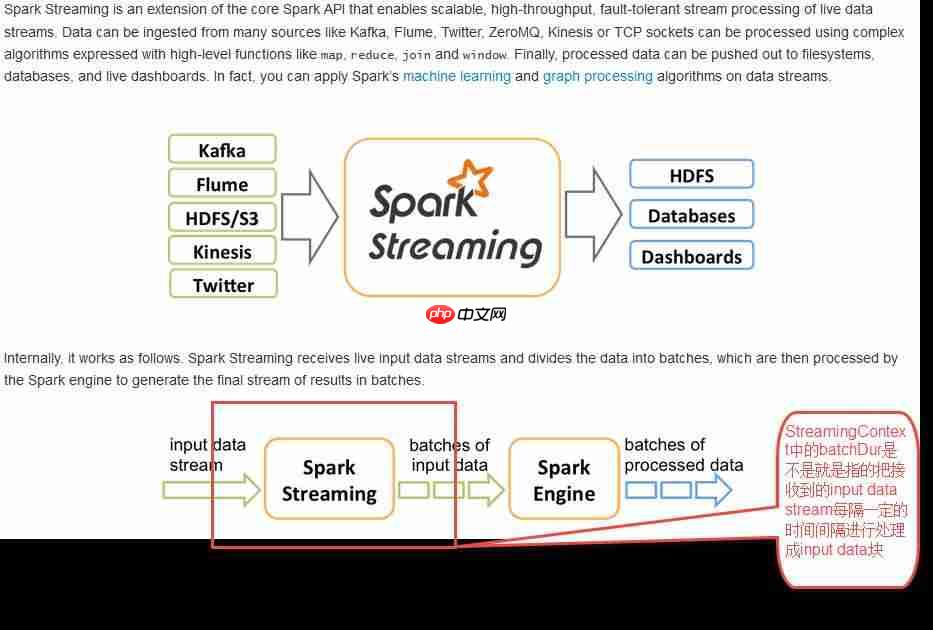
上图中,Spark Streaming模块用于将接收到的数据定时切分成RDD(上图中定义为batch of input data),这些RDD交由Spark Engine进行计算。Spark Streaming模块负责数据接收并定时转换成一系列RDD,Spark Engine对Spark Streaming送过来的RDD进行计算。
DStream的层次关系和window操作的Java代码如下:
/**
* Return a new DStream in which each RDD contains all the elements in seen in a
* sliding window of time over this DStream.
* @param windowDuration width of the window; must be a multiple of this DStream's
* batching interval
* @param slideDuration sliding interval of the window (i.e., the interval after which
* the new DStream will generate RDDs); must be a multiple of this
* DStream's batching interval
*/
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = {
new WindowedDStream(this, windowDuration, slideDuration)
}DStream与window相关的两个参数是windowDuration和slideDuration,这两个参数究竟表示什么含义?通过window操作,DStream转换为了WindowedDStream。
windowDuration表示的是对过去的一个windowDuration时间间隔的数据进行统计计算,windowDuration是intervalBatch的整数倍。也就是说,假设windowDuration=n*intervalBatch,那么window操作就是对过去的n个RDD进行统计计算。以下内容来自于Spark Streaming的官方文档:https://www.php.cn/link/25d6202ac9a813700f3660aafd2c59b8
Spark Streaming也提供了窗口计算(window computations)的功能,允许我们每隔一段时间(sliding duration)对过去一个时间段内(window duration)的数据进行转换操作(transformation)。
slideDuration控制着窗口计算的频度,windowDuration控制着窗口计算的时间跨度。slideDuration和windowDuration都必须是batchInterval的整数倍。假设如下一种场景:
windowDuration=3*batchInterval,
slideDuration=10*batchInterval,
表示的含义是每隔10个时间间隔对之前的3个RDD进行统计计算,也意味着有7个RDD不在window窗口的统计范围内。slideDuration的默认值是batchInterval。
下图展示了滑动窗口的概念。
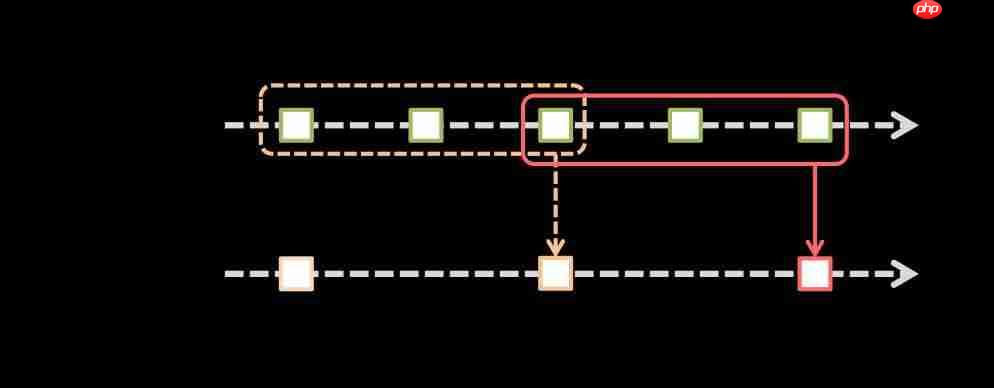
如上图所示,一个滑动窗口时间段(sliding window length)内的所有RDD会进行合并以创建windowed DStream所对应的RDD。每个窗口操作有两个参数:
window length – The duration of the window (3 in the figure),滑动窗口的时间跨度,指本次window操作所包含的过去的时间间隔(图中包含3个batch interval,可以理解时间单位)
sliding interval – The interval at which the window operation is performed (2 in the figure).(窗口操作执行的频率,即每隔多少时间计算一次)
这两个参数必须是源DStream的batch interval的整数倍(1 in the figure)。这表示,sliding window length的时间长度以及sliding interval都要是batch interval的整数倍。batch interval是在构造StreamingContext时传入的(1 in the figure)。
说明:
window length为什么是3?如椭圆形框,它是从第三秒开始算起(包括第三秒),第五秒结束,即包含3,4,5三个1秒,因此是3。
sliding interval为什么是2?主要是看圆角矩形框的右边线,虚线的圆角矩形框的右边线在time 3结束,实线的圆角矩形框的右边线在time 5结束,所以跨度是2。也就是看时间的最右侧即可,以右边线为基准,每个窗口操作(window length)占用了3个时间片。
// Reduce last 30 seconds of data, every 10 seconds val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
表示每隔10秒钟对过去30秒钟产生的单词进行计数。这个方法有个不合理的地方,既然要求sliding window length和sliding interval都是batch interval的整数倍,那么此处为什么不用时间单位,而使用绝对的时间长度呢?
Spark Streaming的数据输入源包括两类:基本数据源和高级数据源。
基本数据源包括:
以上就是Spark Streaming详解(重点窗口计算)的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 915
915



















