
本文主要探讨spark计算引擎与调度管理的实现方式,包括spark计算引擎原理、spark调度管理原理、spark存储管理原理以及spark监控管理。
一:Spark计算引擎原理
Spark计算引擎的核心流程是从RDD创建DAG图,通过DAG图生成逻辑计划,划分Stage并生成Task,最后调度并执行这些Task以实现分布式计算。
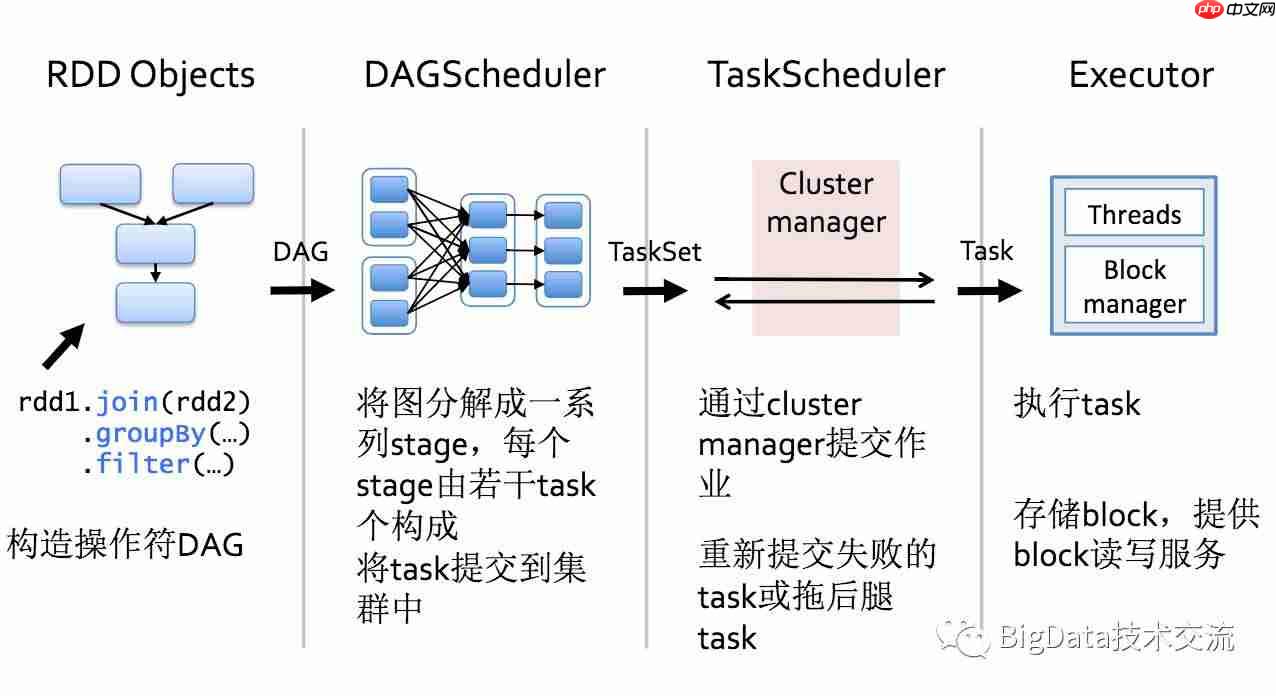
上图清晰展示了从Job的action到中间调度再到具体执行的过程。以下通过一个实例详细解释:

我们启动spark-shell,读取本地文件并执行wordcount操作,统计行数。通过这个简单的Job操作,可以在Spark UI中观察到DAGScheduler的工作方式。
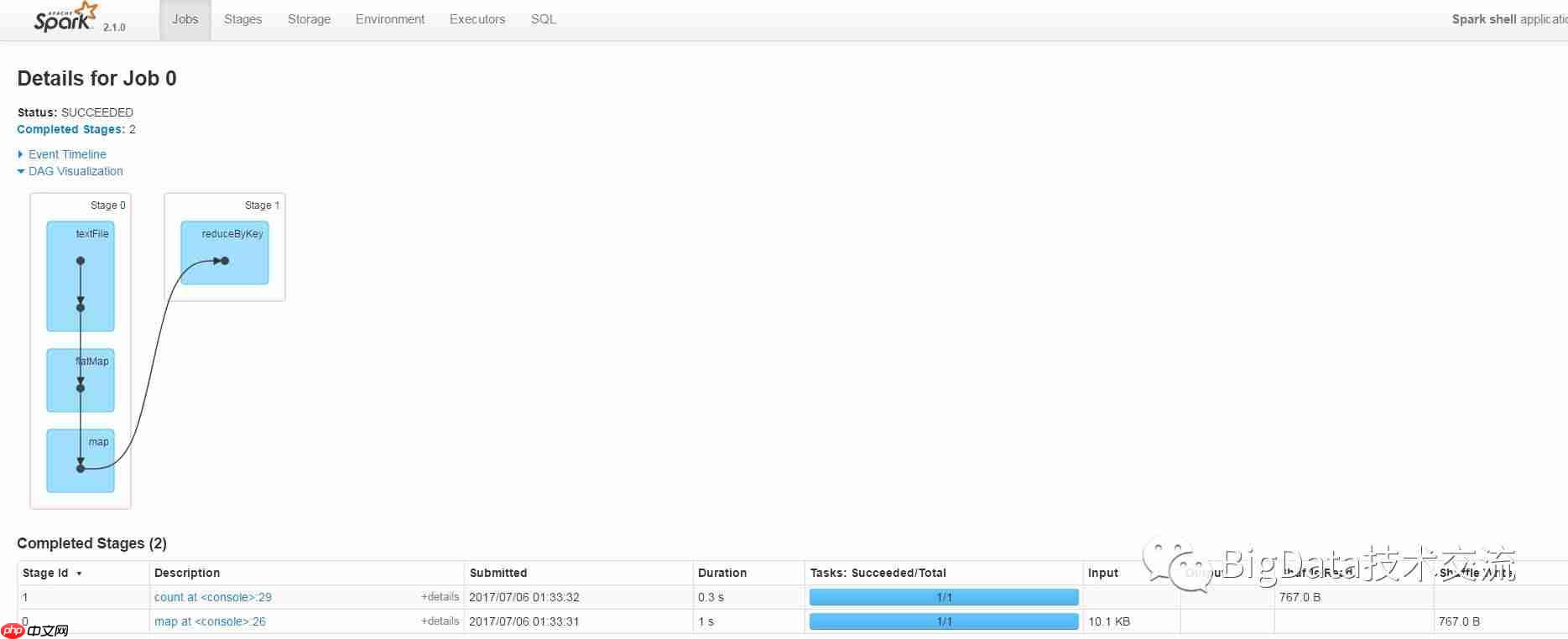
从图中可以看到,flatmap和map操作属于Stage0,而reducebykey操作则属于Stage1。Stage的划分依据是Shuffle或依赖关系。
接下来讨论Shuffle的概念。Shuffle是数据分类和聚合的过程,用于跨节点数据的聚合和归并操作。Shuffle是分布式计算框架的核心数据交换方式,其实现直接影响计算框架的性能和扩展性。Shuffle操作可能会降低数据计算的效率,因此Spark对Shuffle进行了逐步改进。
Spark Shuffle分为两个阶段:write阶段和read阶段。
Spark Shuffle Write阶段
Write阶段有两种方式:Hash-based和Sort-based。
Hash-based是早期Spark版本使用的Shuffle write方式。
Hash-based实现结构图(摘自网络):
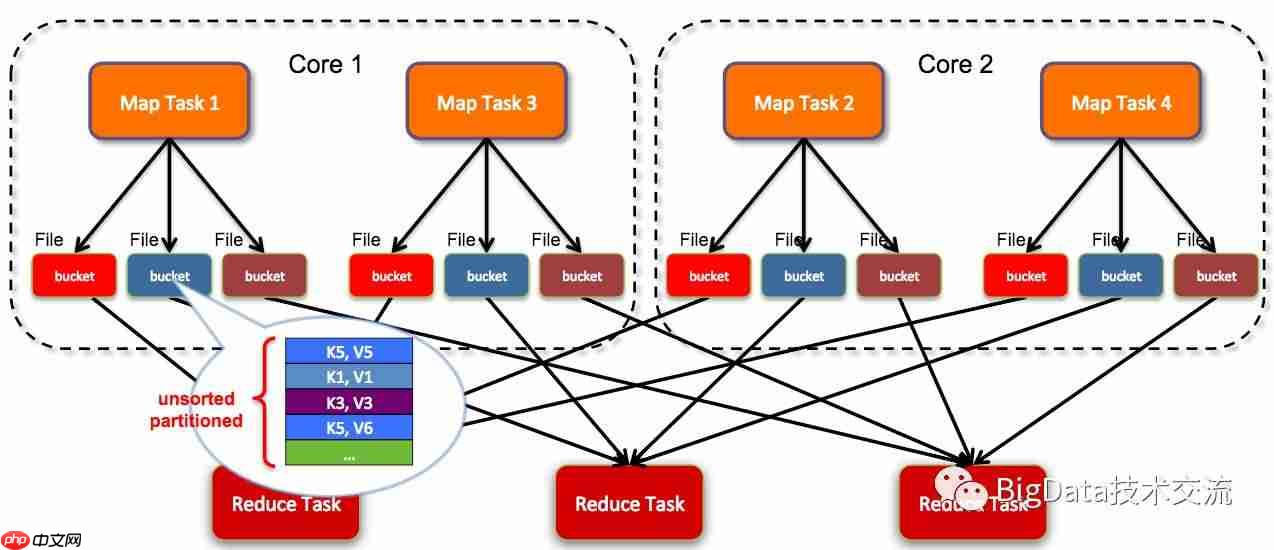
如图所示,每个Task计算完后,结果集存储到本地文件中,Shuffle操作时会产生M*N条连接。如果bucket数量多,会消耗大量资源。因此,Spark后来采用了Sort-based方式。
Sort-based实现结构图(摘自网络):
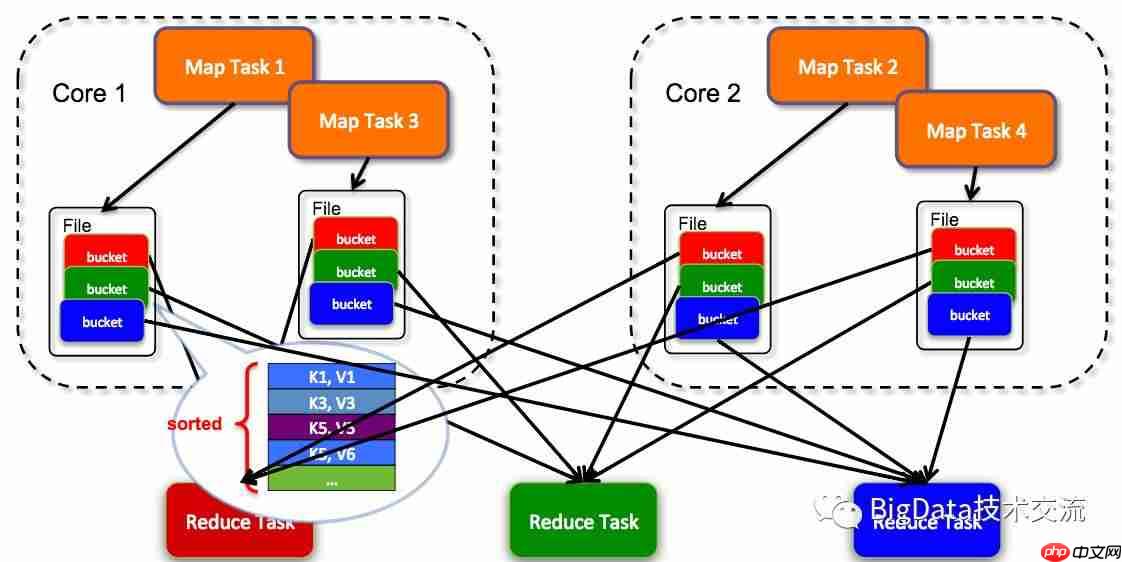
每个Task计算完后生成一个文件,结果集追加到该文件中,同时有一个索引文件记录数据位置,减少了连接数量。
Spark Shuffle Read阶段
在Shuffle操作中,Spark内部隐式创建了一个transformation操作用于Shuffle。
Shuffle read结构图(摘自网络):
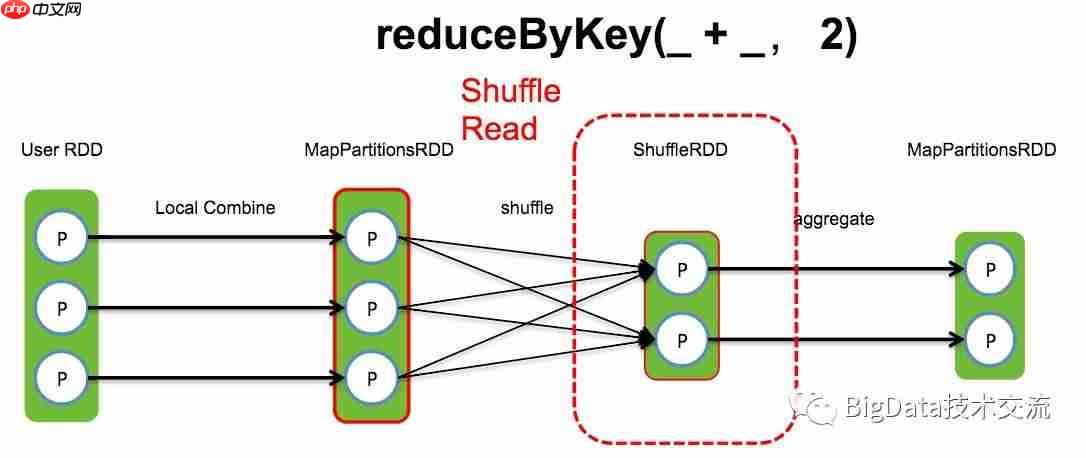
Shuffle read阶段,Spark内部使用BlockStoreShuffleFetcher获取数据,之后获取meta信息并存入Set中。如果数据在本地,直接通过BlockManager.getBlockData读取;如果数据在远程Executor中,则通过NettyBlockTransferService.fetchBlocks获取。
(关于Spark Shuffle的详细内容将在后续章节中详细介绍,这里就不再赘述。)
二:Spark调度管理原理
Spark调度管理系统是Spark程序运行的核心,其中作业调度是调度管理模块的关键。调度的前提是判断多个作业任务的依赖关系(Stage),任务之间存在因果依赖关系,有些任务必须先执行,相关依赖的任务才能执行,任务之间不能出现循环依赖,本质上是DAG图。
作业调度相关类型,以DAGScheduler为核心。
Spark调度相关概念:
Spark调度相关概念逻辑关系图:
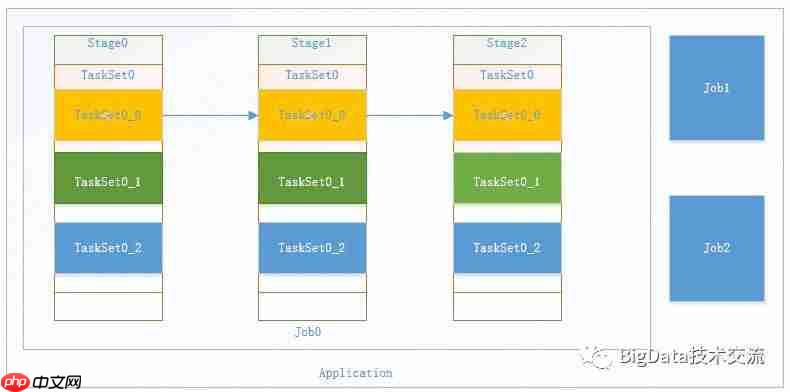
Spark作业调度顶层逻辑:
每个RDD Action类型的算子内部都是一次隐式的作业提交。DAGScheduler的主要任务是计算作业和任务的依赖关系,制定调度逻辑。DAGScheduler在SparkContext初始化过程中被实例化,一个SparkContext应创建一个DAGScheduler。DAGScheduler内部维护着各种“任务/调度阶段/作业”的状态互相之间的映射表,用于在任务状态、集群状态更新时,能够正确维护作业的运行逻辑。
Spark作业调度流程图:
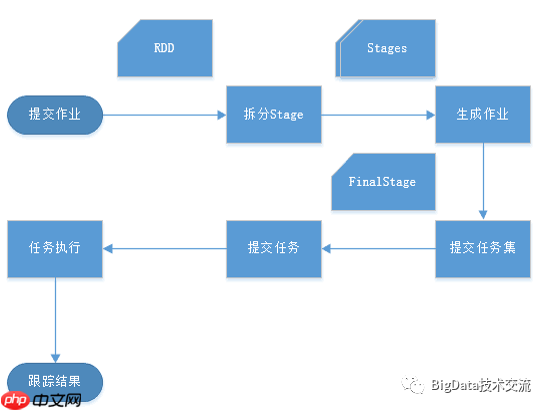
Spark作业调度交互流程:
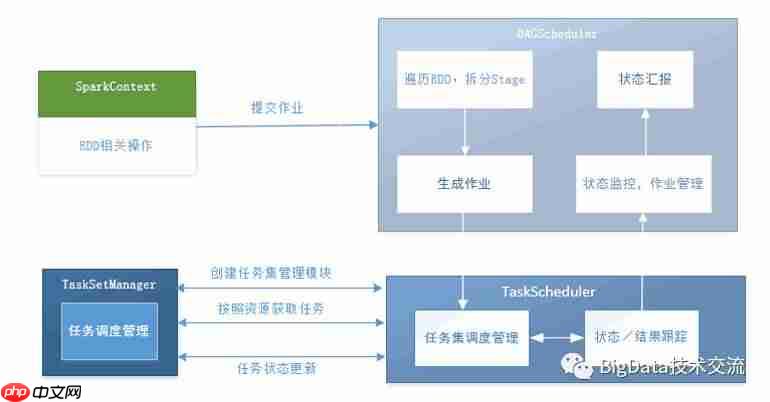
Spark作业调度-调度阶段的拆分:
当一个RDD操作触发计算,向DAGScheduler提交作业时,DAGScheduler需要从RDD依赖链的末端RDD出发,遍历整个RDD依赖链,划分调度阶段,并决定各个调度阶段之间的依赖关系。调度阶段的划分是以ShuffleDependency为依据,即当某个RDD的运算需要Shuffle操作时,整个包含了Shuffle依赖关系的RDD将被用作输入信息,构建一个新的调度阶段。
Spark作业调度-finalStage的提交:
在划分调度阶段的步骤中会得到一个或多个有依赖关系的调度阶段,其中直接触发RDD关联的调度阶段称为FinalStage。然后DAGScheduler进一步从这个FinalStage生成一个作业实例,这两者的关系进一步存储在映射表中,用于在该调度阶段全部完成后做一些后续处理,比如状态报告、清理作业相关数据等。
Spark作业调度-状态监控&任务结果获取:
DAGScheduler对外暴露了一系列的回调函数,对于TaskScheduler而言,这些回调函数主要包括任务的开始、结束、失败,任务集的失败。DAGScheduler根据这些任务的生命周期进一步维护作业和调度阶段的状态信息。
Spark作业调度-任务结果获取:
一个具体任务在Executor中执行完毕后,其结果需要以某种形式返回给DAGScheduler。根据调度的方式不同,返回的方式也不同。对于FinalStage所对应的任务,返回给DAGScheduler的是运算结果本身,而对于中间调度阶段对应的任务ShuffleMapTask,返回给DAGScheduler的是一个MapStatus对象,MapStatus对象管理了ShuffleMapTask的运算输出结果在BlockManager里的项目存储信息,而非结果本身。根据任务结果的大小不同,ResultTask返回的结果分为两类,如果结果足够小,则直接放在DirectTaskResult对象内,如果超过特定尺寸,则在Executor端会将DirectTaskResult先序列化,再把序列化的结果作为一个数据块存放在BlockManager中,然后将BlockManager返回的BlockID放在IndirectTaskResult对象中,返回给TaskScheduler。TaskScheduler进而调用TaskResultGetter将IndirectTaskResult中的BlockID取出并通过BlockManager最终取得对应的DirectTaskResult。
Spark作业调度总结:
Spark的调度管理是Spark作业运行和资源分配的核心,调度的层次依次是底层计算资源、任务调度、作业调度、应用调度。了解这些层次之间的逻辑关系,可以更方便地对Spark的运行状态进行监控以及对集群进行配置优化。
以上就是Spark 内部原理(上) - 计算引擎与调度管理的详细内容,更多请关注php中文网其它相关文章!

每个人都需要一台速度更快、更稳定的 PC。随着时间的推移,垃圾文件、旧注册表数据和不必要的后台进程会占用资源并降低性能。幸运的是,许多工具可以让 Windows 保持平稳运行。

 广告
广告


Copyright 2014-2025 https://www.php.cn/ All Rights Reserved | php.cn | 湘ICP备2023035733号








 866
866



















